
今回は、Google Colaboratoryで外部ファイルに保存した学習済みモデルを読み込んで再評価をしてみたり、学習済みモデルから重みとバイアスを抽出してみたり、CSVファイルに出力してみたり、中間層の出力を取り出して確認したり、ニューラルネットワークをExcelで再現したりと、いろいろ実験してみました。
Pythonで自分の好きなレイアウトでCSVファイルにデータを出力できるようになると、Excelでそのまま使えますし、他のプログラムに移行し易くなると思います。
そして、今回、私が個人的に発見したことは、学習済みモデルの各レイヤの中間層出力結果を表示する方法です。
実は、私のネット検索力では、model.predictというものを使う方法しか情報を得られませんでした。
しかし、つい最近、predictを使わないでも簡単に中間層の出力結果が得られることを発見したんです。
と言っても、TensorFlowやKerasの熟練者から見れば、至極当たり前のことですが、Keras初心者の私からすれば大きな発見でした。
そして、中間層の出力結果と、Excelで作ったニューラルネットワークの計算結果を照合して、ピッタリ合うようになると、難解でブラックボックス化していたTensorFlowやKerasの動作が、だいぶ理解できるようになってきました。
これで、今後はいろいろと応用が利くと思われます。
因みに何度も申し上げておりますが、私はPythonやKerasプログラミングに関しては素人です。
誤りがありましたら、コメント投稿でご連絡いただけると助かります。
- 学習済みモデルを読み込み、評価して確かめる
- 学習済みモデルから重みとバイアスを抽出
- 抽出した重みとバイアスをCSV形式ファイルで保存する
- Excelでニューラルネットワークを再現してみる
- 学習済みモデルの中間層の出力結果を表示させてみる
- まとめ
【目次】
1.HDF5形式学習済みモデルを読み込み、評価して確かめる
まず、前回のこちらの記事でサラッと紹介しましたが、HDF5形式で保存した学習済みモデルを、Googleドライブから読み込んで、評価して、そのモデルが正しく読み込まれているか確認してみます。
1-01. HDF5形式学習済みモデルを読み込む
まず、前回記事を参照して、事前に学習が済んだCNNモデルをHDF5形式でGoogleドライブに保存しておきます。
以下の記事を参照してください。
学習済みモデルをHDF5形式でGoogle Driveに保存する
次に、Google Colaboratoryでファイルを新規に作成しておきます。
では、以下のようなコードを入力して、学習済みモデルのHDF5ファイルを読み込んで、summary出力させます。
ただ、注意していただきたいのは、新規にGoogle Colaboratoryファイルを作成した場合、必ずGoogleドライブをマウントしておいてください。
GoogleドライブのHDF5ファイルのパスは前回記事と同じです。
# 学習済みモデルh5ファイルを読み込んで出力
# ※必ずGoogleドライブをマウントしておくこと
# load_modelをインポートする
from tensorflow.python.keras.models import load_model
# modelへ保存データを読み込み
model = load_model('/content/drive/MyDrive/colab_my_data/my_model.h5')
model.summary()
【実行結果】
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv1 (Conv2D) (None, 5, 25, 25) 85 _________________________________________________________________ maxpool1 (MaxPooling2D) (None, 5, 13, 13) 0 _________________________________________________________________ activation_4 (Activation) (None, 5, 13, 13) 0 _________________________________________________________________ conv2 (Conv2D) (None, 3, 11, 11) 138 _________________________________________________________________ maxpool2 (MaxPooling2D) (None, 3, 6, 6) 0 _________________________________________________________________ activation_5 (Activation) (None, 3, 6, 6) 0 _________________________________________________________________ conv3 (Conv2D) (None, 3, 3, 3) 147 _________________________________________________________________ activation_6 (Activation) (None, 3, 3, 3) 0 _________________________________________________________________ flat1 (Flatten) (None, 27) 0 _________________________________________________________________ dense1 (Dense) (None, 10) 280 _________________________________________________________________ activation_7 (Activation) (None, 10) 0 ================================================================= Total params: 650 Trainable params: 650 Non-trainable params: 0 _________________________________________________________________
1-02. 手書き数字MNISTデータセットをインポートして正規化しておく
次に、読み込んだ学習済みモデルの正答率が前回記事と同じかどうか確かめるために、新たに手書き数字MNISTデータセットをインポートしておきます。
以下のコードは、前回記事と同様で、MNISTインポートとデータの正規化を一括にまとめました。
# 手書き数字MNISTデータセットのインポート
import keras
from keras.datasets import mnist
from matplotlib import pyplot
import numpy as np # NumPyモジュールをインポート
# kerasのバージョン確認
print('keras version ',keras.__version__)
# 手書き数字MNISTデータを読み込み
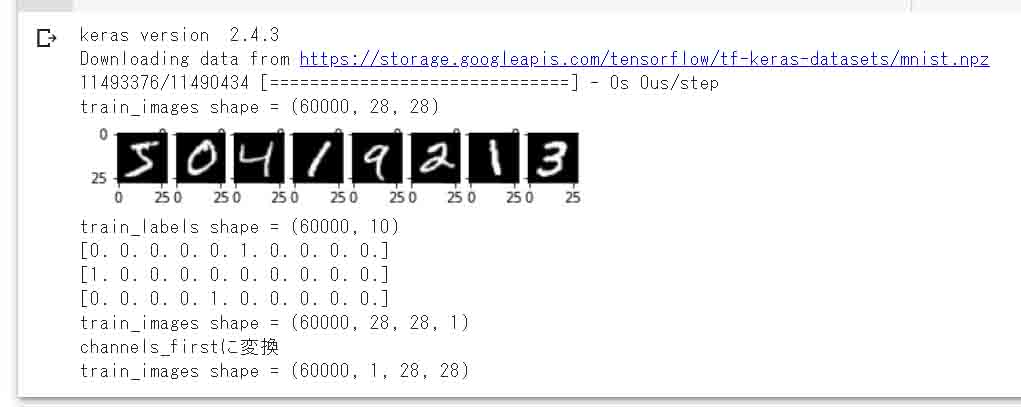
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 画像データの次元確認
print('train_images shape =', train_images.shape)
# 画像データ8件をキャンバスに1行8列で白黒で出力
for i in range(0, 8):
pyplot.subplot(2, 8, i + 1)
pyplot.imshow(train_images[i], cmap='gray')
pyplot.show()
# ラベルデータをone-hotベクトルに変換
# np_utilsはAPIが変わったので使わない事
# https://keras.io/ja/utils/#to_categorical
train_labels = keras.utils.to_categorical(train_labels.astype('int32'), 10)
test_labels = keras.utils.to_categorical(test_labels.astype('int32'), 10)
# ラベルデータの要素数確認
print('train_labels shape =', train_labels.shape)
# ラベルデータ3件だけ表示
for i in range(0, 3):
print(train_labels[i])
# shapeが(60000, 28, 28)を(60000, 28, 28, 1)に次元を増やす。
# KerasでCNN演算行う場合、デフォルトがchannels_lastになっていることに注意。
# 因みにRGBカラー画像だと、(60000, 28, 28, 3)となる。
# train_images.shape[0] = 60000
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1)
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1)
# 次元の確認
print('train_images shape =', train_images.shape)
# 整数型の画像データをfloat型に変換
train_images = train_images.astype('float32')
test_images = test_images.astype('float32')
# 学習のために0~255の整数値を0~1.0の範囲に収めるために、全要素を255で割る
train_images = train_images / 255.0
test_images = test_images / 255.0
# MNIST画像データをchannels_firstにする為に次元を入れ換え
train_images = np.transpose(train_images, [0, 3, 1, 2])
test_images = np.transpose(test_images, [0, 3, 1, 2])
print('channels_firstに変換')
print('train_images shape =', train_images.shape)
【実行結果】
(図01_02_01)
1-03. 学習済みモデルにテストデータを入力して評価させ、正答率が合っているか確認する
次に、前回記事の正答率と合っているか確認するために、学習済みモデルに評価用(テスト)データを入力して評価してみます。
ここで注意していただきたいのは、ハードウェアアクセラレータをGPUにすることです。
そうしないとエラーが出るので注意して下さい。
おそらく、evaluate(評価)する時はテンソル形式データでGPU計算するようにできているものと思われます。
# 読み込んだモデルにデータセットを代入し評価する
# ※ハードウェアアクセラレータをGPUにしないとエラーが出るので注意
score = model.evaluate(test_images, test_labels, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
【実行結果】
313/313 [==============================] - 7s 2ms/step - loss: 0.0611 - accuracy: 0.9807 正解率= 0.9807000160217285 loss= 0.061071861535310745
このように正答率が98%なので、前回記事と同様のモデルがちゃんと読み込まれていることが確認できました。
2.学習済みモデルから重みとバイアスを抽出
では、読み込んだ学習済みモデルから重みとバイアスを抽出してみます。
まず先に言っておきたいことがあります。
前回記事で紹介したように、各レイヤにname引数を使って名前を付けておきました。
それを使えば、get_layer関数で学習済みレイヤの情報が取得できます。
それがここで生きてくるわけです。
さて、Kerasには学習済みモデルのレイヤにget_weightsという便利な関数があり、それを使えば重みが抽出できることが分かりました。
こんな感じです。
# 学習済みモデルからconv1の重みとバイアス値を抽出
import numpy as np # NumPyモジュールをインポート
layer_conv1 = model.get_layer('conv1')
# conv1のget_weightsの出力結果を見てみる
conv1_weights = layer_conv1.get_weights()
print('layer_conv1.get_weights()=\n')
print(conv1_weights)
【実行結果】
layer_conv1.get_weights()=
[array([[[[ 0.3024972 , -0.12046432, 1.1668445 , -0.08471765,
0.50666964]],
[[ 0.8258916 , -0.87764156, -0.10202333, -0.3599728 ,
0.35130185]],
[[ 0.02913883, -1.2250097 , 0.35615897, -0.45269975,
0.27686888]],
[[ 0.10776022, -0.5368966 , 0.7530693 , -0.19655459,
0.56644505]]],
[[[ 0.08676838, -0.8293965 , 1.5078446 , 0.23133287,
-1.2229576 ]],
[[ 0.5218094 , -0.8594758 , 2.3221092 , -0.05093303,
0.20626369]],
[[-0.60181016, 0.48028857, 4.240992 , -0.17620689,
0.28682438]],
[[ 0.32897255, 0.4738648 , 0.94423836, -0.3680279 ,
0.35189298]]],
[[[ 0.39741772, -1.3711711 , 0.3376623 , 0.27054733,
-0.3001343 ]],
[[-1.3807857 , 0.31480992, -2.5563085 , -0.1217019 ,
-0.5218974 ]],
[[ 2.6640604 , 0.07472414, -2.6789103 , 0.44363895,
-0.99858564]],
[[ 0.29727504, 0.31714895, 0.17971452, -0.21216662,
-1.9957496 ]]],
[[[-0.4181669 , -0.56292087, 0.15854076, 0.12870304,
-0.00627275]],
[[ 0.19367328, -0.43130538, -0.6207984 , 0.07182112,
-0.15930852]],
[[ 0.00863842, 0.10902223, -0.27064487, 0.29982772,
-0.08143044]],
[[ 0.8347777 , 0.3888695 , -0.02917243, 0.5192239 ,
0.39241385]]]], dtype=float32), array([-0.03911582, -0.566945 , -0.39932117, -0.23809178, -0.19687998],
dtype=float32)]
あれ!?
この実行結果の下の方をよく見ると、重みだけではない別の配列データが入っていますね。
実は、これは何と、バイアスデータでした!
get_weightsとあるから、私はてっきり重みだけを取得すると思っていました。
でも、どうやら、TensorFlowやKeras界隈では、weightsと言ったら重みとバイアスも含むデータを示すようです。
これには長い間気付きませんでしたね。
Kerasのドキュメントにもバイアス込みだなんて書いてなかったのです。
そんなの分かりませんよねぇ~、、、。
ということで、この中から重みだけを抽出したい場合は、以下のようにゼロ番目の要素をGETすれば良いのです。
# conv1の重みだけを抽出
conv1_weight = layer_conv1.get_weights()[0]
print('layer_conv1.get_weights()[0]=\n')
print(conv1_weight)
【実行結果】
layer_conv1.get_weights()[0]= [[[[ 0.3024972 -0.12046432 1.1668445 -0.08471765 0.50666964]] [[ 0.8258916 -0.87764156 -0.10202333 -0.3599728 0.35130185]] [[ 0.02913883 -1.2250097 0.35615897 -0.45269975 0.27686888]] [[ 0.10776022 -0.5368966 0.7530693 -0.19655459 0.56644505]]] [[[ 0.08676838 -0.8293965 1.5078446 0.23133287 -1.2229576 ]] [[ 0.5218094 -0.8594758 2.3221092 -0.05093303 0.20626369]] [[-0.60181016 0.48028857 4.240992 -0.17620689 0.28682438]] [[ 0.32897255 0.4738648 0.94423836 -0.3680279 0.35189298]]] [[[ 0.39741772 -1.3711711 0.3376623 0.27054733 -0.3001343 ]] [[-1.3807857 0.31480992 -2.5563085 -0.1217019 -0.5218974 ]] [[ 2.6640604 0.07472414 -2.6789103 0.44363895 -0.99858564]] [[ 0.29727504 0.31714895 0.17971452 -0.21216662 -1.9957496 ]]] [[[-0.4181669 -0.56292087 0.15854076 0.12870304 -0.00627275]] [[ 0.19367328 -0.43130538 -0.6207984 0.07182112 -0.15930852]] [[ 0.00863842 0.10902223 -0.27064487 0.29982772 -0.08143044]] [[ 0.8347777 0.3888695 -0.02917243 0.5192239 0.39241385]]]]
やったー!
重みだけ抽出できました。
では、バイアスだけを抽出する場合、1番目の要素をGETすれば良いです。
# conv1のバイアスだけを抽出
conv1_bias = layer_conv1.get_weights()[1]
print('layer_conv1.get_weights()[1]=\n')
print(conv1_bias)
【実行結果】
layer_conv1.get_weights()[1]= [-0.03911582 -0.566945 -0.39932117 -0.23809178 -0.19687998]
やったー!
バイアスが抽出できたー!
実は、get_biasという関数が存在するのではないかと思い、かなりネット検索しましたが、ネット上の情報にも公式ドキュメントにもどこにもありませんでした。
まさか、get_weightsで重みとバイアス両方が取得できるなんて思いませんでしたよ。
Kerasって、一筋縄ではいきませんね。
では、全レイヤの重みとバイアスを抽出する場合は以下のようになります。
ただ、後々にExcelでニューラルネットワークを再現できるようにするため、channels_firstに変換しなければならなく、reshapeやtransposeを使いますので注意してください。
# 学習済みモデルから全レイヤの重みとバイアス値を抽出
import numpy as np # NumPyモジュールをインポート
layer_conv1 = model.get_layer('conv1')
layer_conv2 = model.get_layer('conv2')
layer_conv3 = model.get_layer('conv3')
layer_dense1 = model.get_layer('dense1')
# conv1の重みとバイアスを抽出-----------------------------------------
conv1_weight = layer_conv1.get_weights()[0]
print('conv1 重み')
print(conv1_weight)
print('conv1_weight.shape=', conv1_weight.shape)
# shape=(4, 4, 1, 5)のため、次元を1つ減らし、3次元配列に変換
conv1_weight = conv1_weight.reshape(4, 4, 5)
# channels_last形式になっているため、channels_first形式に変更
conv1_weight = np.transpose(conv1_weight, [2, 0, 1])
print('次元を1つ減らし、channels_firstに変更')
print('conv1_weight.shape=', conv1_weight.shape)
print(conv1_weight)
print()
# conv1のバイアス値抽出
conv1_bias = layer_conv1.get_weights()[1]
print('conv1 バイアス')
print(conv1_bias)
# conv2の重みとバイアスを抽出----------------------------------------
conv2_weight = layer_conv2.get_weights()[0]
print('\n--------------------------------------')
print('conv2 重み')
print('conv2_weight.shape=', conv2_weight.shape)
# shape=(3, 3, 5, 3)でchannels_last形式になっているため、channels_first形式に変更
conv2_weight = np.transpose(conv2_weight, [3, 2, 0, 1])
print('channels_firstに変更')
print('conv2_weight.shape=', conv2_weight.shape)
print(conv2_weight)
print()
# conv2のバイアス値抽出
conv2_bias = layer_conv2.get_weights()[1]
print('conv2 バイアス')
print(conv2_bias)
# conv3の重みとバイアスを抽出----------------------------------------
conv3_weight = layer_conv3.get_weights()[0]
print('\n--------------------------------------')
print('conv3 重み')
print('conv3_weight.shape=', conv3_weight.shape)
# shape=(4, 4, 3, 3)でchannels_last形式になっているため、channels_first形式に変更
conv3_weight = np.transpose(conv3_weight, [3, 2, 0, 1])
print('channels_firstに変更')
print('conv3_weight.shape=', conv3_weight.shape)
print(conv3_weight)
print()
# conv3のバイアス値抽出
conv3_bias = layer_conv3.get_weights()[1]
print('conv3 バイアス')
print(conv3_bias)
# dense1の重みとバイアスを抽出----------------------------------------
dense1_weight = layer_dense1.get_weights()[0]
print('\n--------------------------------------')
print('dense1 重み')
print('dense1_weight.shape=', dense1_weight.shape)
# dense1_weight.shape=(27, 10)なので、channels_firstの(10, 27)に変換
print('dense1 重み channles_firstに変更')
dense1_weight = np.transpose(dense1_weight, [1, 0])
print('dense1_weight.shape=', dense1_weight.shape)
print(dense1_weight)
print()
# dense1のバイアス値抽出
dense1_bias = layer_dense1.get_weights()[1]
print('dense1 バイアス')
print(dense1_bias)
【実行結果】
conv1 重み [[[[ 0.3024972 -0.12046432 1.1668445 -0.08471765 0.50666964]] [[ 0.8258916 -0.87764156 -0.10202333 -0.3599728 0.35130185]] [[ 0.02913883 -1.2250097 0.35615897 -0.45269975 0.27686888]] [[ 0.10776022 -0.5368966 0.7530693 -0.19655459 0.56644505]]] [[[ 0.08676838 -0.8293965 1.5078446 0.23133287 -1.2229576 ]] ・・・・・・・・・・・・・・・・・・・・ ・・・・・・・<中略>・・・・・・・・・ ・・・・・・・・・・・・・・・・・・・・ [-1.40986633e+00 -3.65869617e+00 -2.12090343e-01 1.41635358e+00 -3.22638869e+00 1.44717157e+00 -2.06798220e+00 -3.45906758e+00 4.34206152e+00 -2.18066171e-01 5.91134489e-01 8.69690239e-01 6.61583185e-01 -6.50768161e-01 1.99231648e+00 2.11508012e+00 1.74076569e+00 7.37015486e-01 5.15004516e-01 -1.28891855e-01 -2.31712055e+00 -3.10516143e+00 -7.90611982e-01 1.55424511e+00 -3.00089359e+00 1.85540187e+00 -2.38645181e-01] [-2.28589725e+00 -2.41197920e+00 6.94251895e-01 -4.20079470e+00 -1.73598468e+00 3.65452957e+00 3.70032579e-01 4.19307280e+00 -3.88668633e+00 -1.52674735e+00 4.50353956e+00 -3.73875618e-01 -6.57015383e-01 1.27603900e+00 2.14003712e-01 4.40069437e+00 -4.13804412e-01 -1.49310780e+00 -4.64827478e-01 -7.73745775e-01 1.13748026e+00 1.49190819e+00 -1.63274062e+00 -1.97609377e+00 -3.08482790e+00 4.08087134e-01 -7.49412119e-01]] dense1 バイアス [-0.27790773 -2.3080177 3.897405 -3.8346603 4.8839145 0.43151203 -2.5492678 -1.0328032 4.7668715 3.26831 ]
白黒の手書き数字MNISTデータセットを入力とした場合、第1層のconv1の重みをget_weightsで取得すると、上記の様にshapeは
(4, 4, 1, 5)
という4次元配列になっています。
重みフィルタ(カーネル)が4×4です。
1という値は、白黒のため、入力が1チャンネル(ニューロン)という意味です。
よって、その1という要素は不要なので、3次元配列にreshapeします。
そして、5という値は出力が5チャンネル(ニューロン)という意味で、channels_last形式になっています。
それでは理解しにくいので、これをchannels_firstに変更して、
(5, 4, 4)
にすればExcelやマイコンプログラミングに移行し易くなります。
conv2の重みのshapeは
(3, 3, 5, 3)
となっていて、重みフィルタ(カーネル)が3×3、入力5チャンネル、出力3チャンネルという意味です。
これもchannels_firstに変更して、
(3, 5, 3, 3)
とします。
同様に、conv3の重みは
(4, 4, 3, 3)
となっていて、重みフィルタ4×4、入力3チャンネル、出力3チャンネルです。
これをchannels_firstに変更して、
(3, 3, 4, 4)
とします。
dense1の重みは
(27, 10)
となっているので、channels_firstに変更して、
(10, 27)
とします。
各レイヤのバイアスはshapeを変更する必要はありません。
ここまでできれば、Excelや組み込みマイコンでモデルを再現できますね。
あとは、CSV形式ファイルで保存するだけです。
3.抽出した重みとバイアスをCSV形式ファイルで保存する
学習済みCNNモデルから重みとバイアスが抽出できたので、それをCSV形式ファイルへ保存してみます。
Google ドライブに保存しますので、事前にGoogle ColaboratoryでGoogleドライブをマウントしておいてください。
CSVファイルはカンマで区切られたテキスト形式ファイルですが、Microsoft Excelで読み込むことができるので便利です。
これは、Pythonに装備されているCSV関連モジュールをインポートします。
以下のPython公式ドキュメントも合わせて参照してみてください。
Python公式 CSV ファイルの読み書き
# 学習済みモデルから重みとバイアス値をCSVファイルに出力
# csvをインポート
import csv
# csvファイル内に見出しを付けるための文字配列
# 1行の文字列として出力する場合は、2次元配列にすべし
index_str = [['conv1_weight'],
['conv1_bias'],
['conv2_weight'],
['conv2_bias'],
['conv3_weight'],
['conv3_bias'],
['dense1_weight'],
['dense1_bias'],
['###########']]
# ファイルを書き込みモードでオープン
with open('/content/drive/MyDrive/colab_my_data/weight_bias.csv',
'w',
newline='',
encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
# conv1レイヤの重みとバイアス書き込み
writer.writerow(index_str[0])
for i in range(5):
writer.writerows(conv1_weight[i])
writer.writerow(index_str[8])
writer.writerow(index_str[1])
writer.writerow(conv1_bias)
writer.writerow(index_str[8])
# conv2レイヤの重みとバイアス書き込み
writer.writerow(index_str[2])
for j in range(3):
for i in range(5):
writer.writerows(conv2_weight[j][i])
writer.writerow(index_str[8])
writer.writerow(index_str[3])
writer.writerow(conv2_bias)
writer.writerow(index_str[8])
# conv3レイヤの重みとバイアス書き込み
writer.writerow(index_str[4])
for j in range(3):
for i in range(3):
writer.writerows(conv3_weight[j][i])
writer.writerow(index_str[8])
writer.writerow(index_str[5])
writer.writerow(conv3_bias)
writer.writerow(index_str[8])
# dense1レイヤの重みとバイアス書き込み
writer.writerow(index_str[6])
for j in range(10):
ii = 0
for i in range(9):
ii = i * 3
writer.writerow(dense1_weight[j][ii:ii+3])
if j == 4: # dense1の重みの数が多いため、半分で区切る
writer.writerow(index_str[8])
writer.writerow(index_str[8])
writer.writerow(index_str[7])
writer.writerow(dense1_bias)
writer.writerow(index_str[8])
csvfile.close()
print('CSV書き込み終了')
これを実行する時は、「全てのセルを実行」させることに注意です。
【実行結果】
CSV書き込み終了
出力されたCSVファイルをExcelで開くと下図の様な感じになります。
(図3_01)
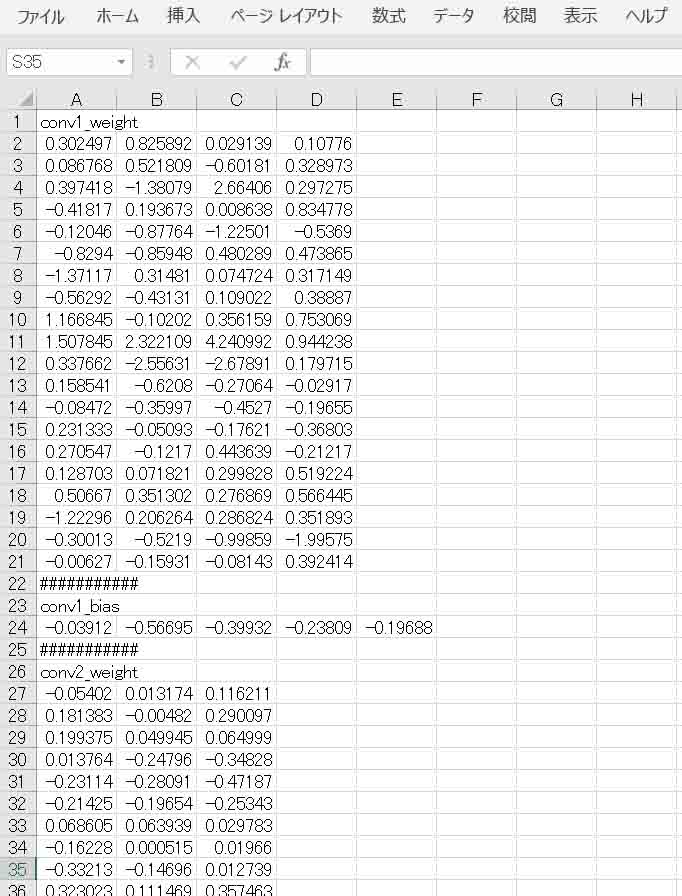
ソースコードの3行目のimport csvでcsvファイル書き込みモジュールをインポートします。
index_strは、個人的に見出し文字列を出力したかったので、2次元配列にしました。
ここで注意しなければならないのは、writerow関数でファイルに文字列を出力する時、文字列は2次元配列でなければならないということです。
Pythonの特徴として、
index_str = ['conv1_weight', 'conv1_bias']
のように、1次元配列(C言語では2次元配列になる)で表現できますが、writerowやwriterowsで出力すると、
c, o, n, v, 1, _, w, e, i, g, h, t,
のように、1文字ずつカンマで区切られて出力されてしまいます。
ということで、通常の文字列として出力させたい場合には、2次元配列にするというところはポイントですね。
また、open文の出力ファイルのパスは、前回のこちらの記事で紹介したように、Googleドライブ上のパスです。
何度も言っているように、必ずGoogleドライブを事前にマウントしておく必要があります。
以上で学習済みモデルの重みとバイアスデータを、CSVファイルに自由なレイアウトで出力することができました。
こうすれば、Excelでニューラルネットワークを再現する場合でもセルのコピーが楽にできますね。
それに、組み込みマイコンのプログラミングにも移行し易いと思います。
これは、SONY Neural Network Consoleよりも自由度が高くて重宝すると思いますね。
4.Excelでニューラルネットワークを再現してみる
では、Google Colaboratoryで学習させたCNN(畳み込みニューラルネットワーク)の重みとバイアスが抽出できたので、ExcelでCNNを再現してみて、Kerasの出力結果と合っているか検証してみます。
これができれば、他の組み込みマイコン等に移植できます。
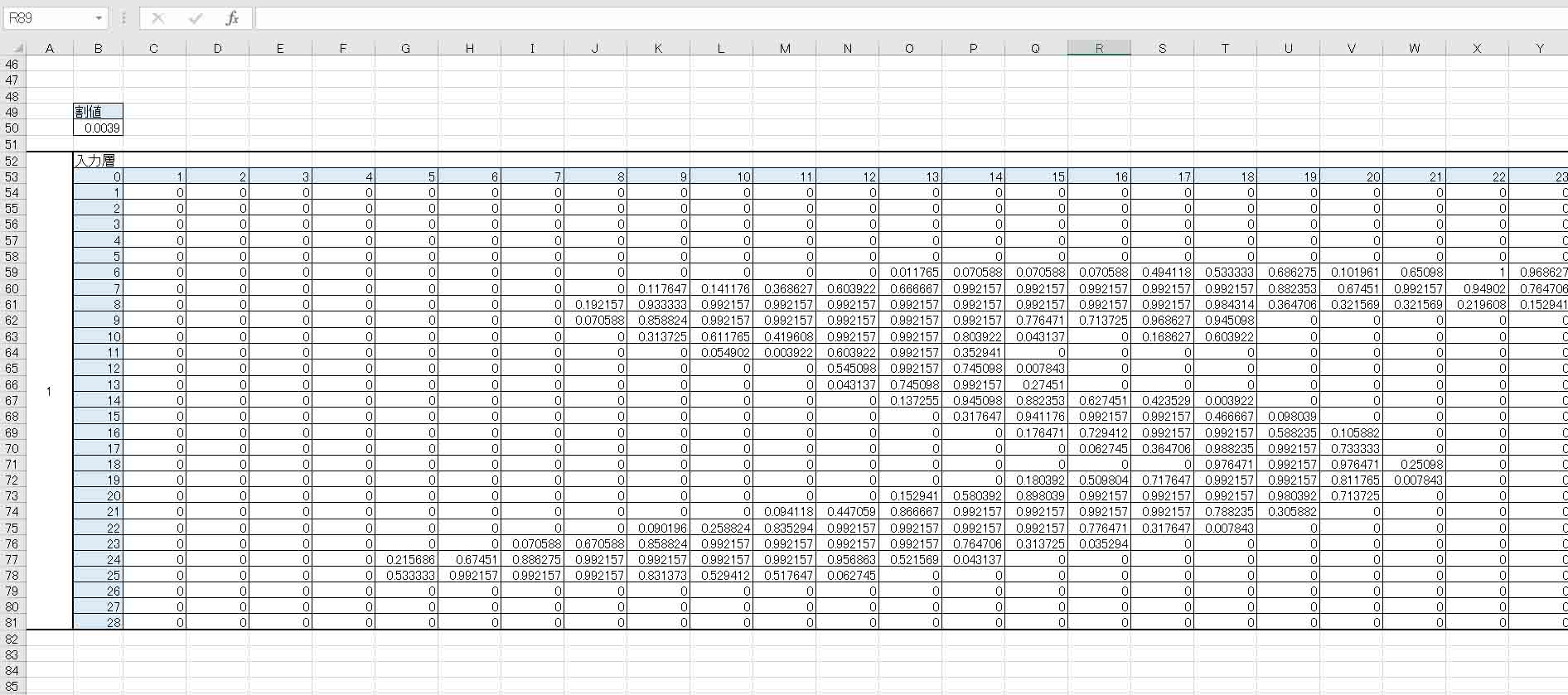
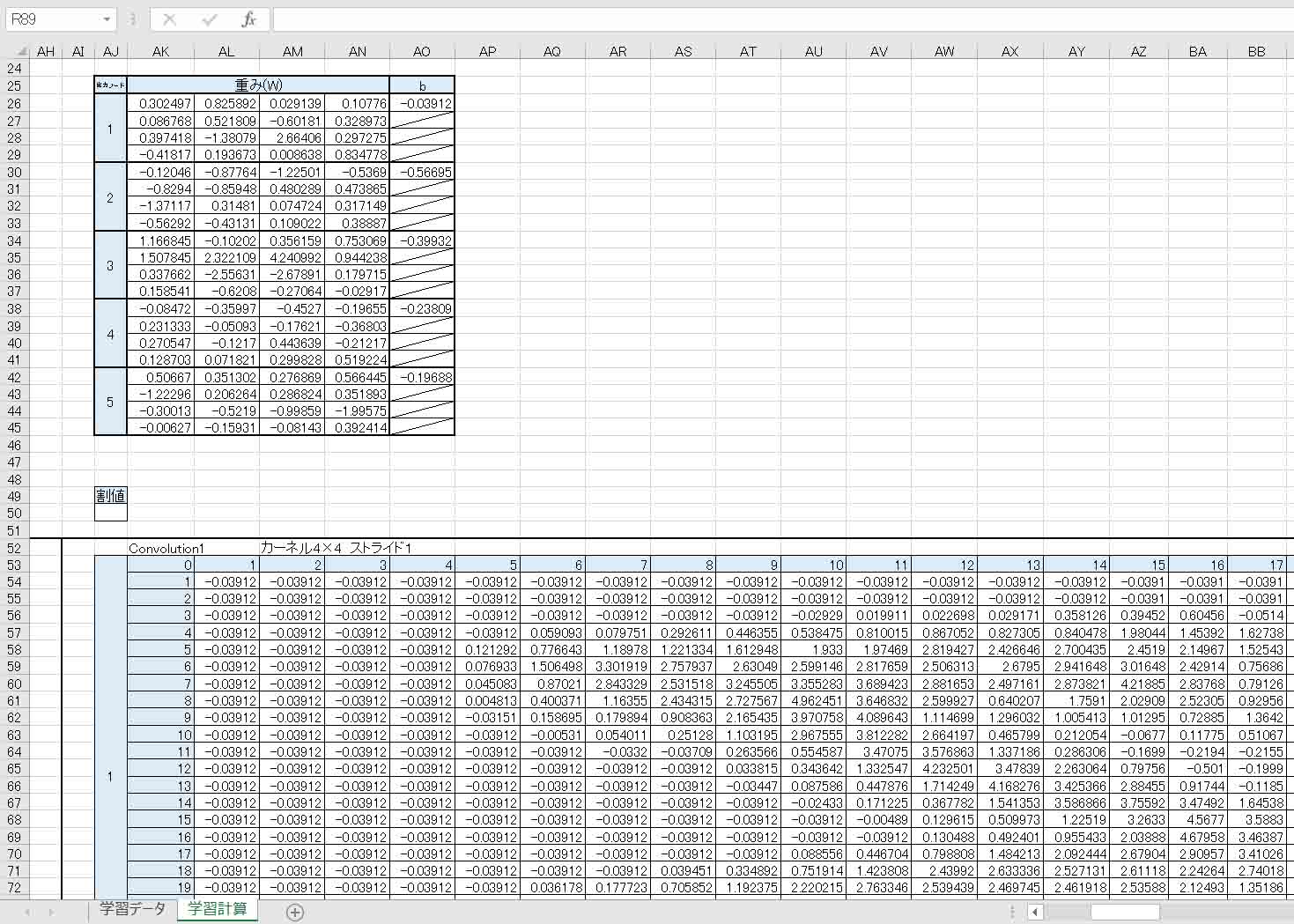
3章で出力したCSVファイルをExcelで開き、重みとバイアスをそれぞれコピペして、ExcelでCNNモデルを作ってみました。
これは、GitHubの以下のリンクに置いておきますので、ご自由にどうぞ。
https://github.com/mgo-tec/test_excel_deeplearning/blob/master/Keras_CNN/keras_cnn(5_3_3)01.xlsx
このExcelファイルは、手書き数字MNISTデータセットのうち、trainデータの最初の5という数字のデータを入力して判定しています。
こんな感じです。
(図4_01)
(図4_02)
(図4_03)
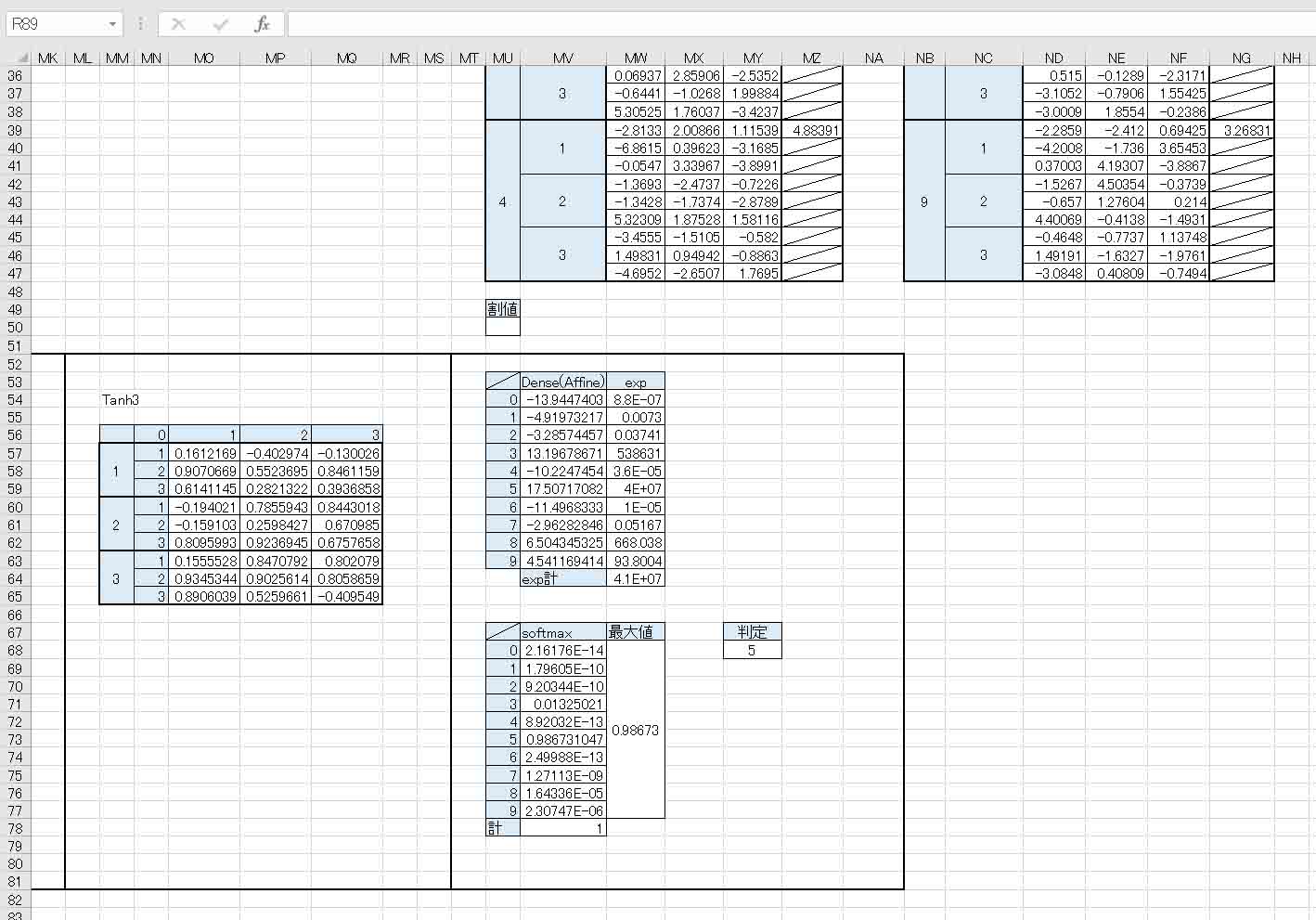
これを見て分かる通り、最後のSoftmaxの最大値が5の箇所なので、正常に判定されています。
ただ、これはたまたまなのかも知れませんよね。
そこで、各層の出力結果の数値が合っているか確かめたいと思います。
つまり、中間層の出力結果を得る方法を次で紹介します。
5.学習済みモデルの中間層の出力結果を表示させてみる
では、前章のExcelで再現したCNN(畳み込みニューラルネットワーク)が正しい計算式かどうか検証するために、Kerasの学習済みモデルから中間層の出力結果を個別に抽出してみたいと思います。
まず、簡単な例として、先ほどの学習済みモデルの入力層からconv1レイヤまでのニューラルネットワークモデルを新たに生成し、それに学習用MNISTデータを入力して出力結果を得る方法を紹介します。
MNISTデータは60000件のうち、最初のゼロ番目のデータだけを入力します。
以下の感じです。
# ModelクラスAPIをインポート
from keras.models import Model
# 入力層から出力する中間層までのニューラルネットワークモデルを生成
model_to_conv1 = Model(inputs=model.input,
outputs=model.get_layer('conv1').output)
# 学習用MNISTデータの最初の画像(ゼロ番目)を取り出して、4次元配列に変換しておく
image0 = train_images[0].reshape(1, 1, 28, 28)
# 中間層までのモデルに最初のゼロ番目の学習用MNISTデータを入力させて、出力結果を取得
conv1_output = model_to_conv1(image0)
# 出力結果conv1_outputはテンソル形式データのため、NumPy配列に変換して表示
print('conv1値\n', conv1_output[0].numpy())
【実行結果】
conv1値 [[[-3.9115820e-02 -3.9115820e-02 -3.9115820e-02 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02] [-3.9115820e-02 -3.9115820e-02 -3.9115820e-02 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02] [-3.9115820e-02 -3.9115820e-02 -3.9115820e-02 ... -3.4770688e-01 -2.4737933e-01 -3.9115820e-02] ... [-3.9115820e-02 1.9038574e-01 1.7687529e+00 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02] [-3.9115820e-02 1.5957862e-01 4.5281295e-02 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02] [-3.9115820e-02 1.8356301e-02 8.3339930e-02 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02]] [[-5.6694502e-01 -5.6694502e-01 -5.6694502e-01 ... -5.6694502e-01 -5.6694502e-01 -5.6694502e-01] [-5.6694502e-01 -5.6694502e-01 -5.6694502e-01 ... -5.6694502e-01 -5.6694502e-01 -5.6694502e-01] [-5.6694502e-01 -5.6694502e-01 -5.6694502e-01 ... -1.3270125e+00 -8.4730172e-01 -5.6694502e-01] ... [-5.6694502e-01 -2.9559276e-01 2.1078748e-01 ... -5.6694502e-01 -5.6694502e-01 -5.6694502e-01] [-5.6694502e-01 -4.3001834e-01 -4.6700266e-01 ... -5.6694502e-01 -5.6694502e-01 -5.6694502e-01] [-5.6694502e-01 -8.5328984e-01 -1.7529693e+00 ... -5.6694502e-01 -5.6694502e-01 -5.6694502e-01]] [[-3.9932117e-01 -3.9932117e-01 -3.9932117e-01 ... -3.9932117e-01 -3.9932117e-01 -3.9932117e-01] [-3.9932117e-01 -3.9932117e-01 -3.9932117e-01 ... -3.9932117e-01 -3.9932117e-01 -3.9932117e-01] [-3.9932117e-01 -3.9932117e-01 -3.9932117e-01 ... -5.5493617e-01 -3.2036164e-01 -3.9932117e-01] ... [-3.9932117e-01 -9.9814177e-02 -9.8146468e-02 ... -3.9932117e-01 -3.9932117e-01 -3.9932117e-01] [-3.9932117e-01 2.6669934e-01 3.3841453e+00 ... -3.9932117e-01 -3.9932117e-01 -3.9932117e-01] [-3.9932117e-01 2.3157895e-03 5.3779316e-01 ... -3.9932117e-01 -3.9932117e-01 -3.9932117e-01]] [[-2.3809178e-01 -2.3809178e-01 -2.3809178e-01 ... -2.3809178e-01 -2.3809178e-01 -2.3809178e-01] [-2.3809178e-01 -2.3809178e-01 -2.3809178e-01 ... -2.3809178e-01 -2.3809178e-01 -2.3809178e-01] [-2.3809178e-01 -2.3809178e-01 -2.3809178e-01 ... -7.7656746e-02 -1.7399262e-01 -2.3809178e-01] ... [-2.3809178e-01 -4.3062589e-01 -4.9823076e-01 ... -2.3809178e-01 -2.3809178e-01 -2.3809178e-01] [-2.3809178e-01 -4.7676748e-01 -9.2742932e-01 ... -2.3809178e-01 -2.3809178e-01 -2.3809178e-01] [-2.3809178e-01 -3.4292090e-01 -6.7454463e-01 ... -2.3809178e-01 -2.3809178e-01 -2.3809178e-01]] [[-1.9687998e-01 -1.9687998e-01 -1.9687998e-01 ... -1.9687998e-01 -1.9687998e-01 -1.9687998e-01] [-1.9687998e-01 -1.9687998e-01 -1.9687998e-01 ... -1.9687998e-01 -1.9687998e-01 -1.9687998e-01] [-1.9687998e-01 -1.9687998e-01 -1.9687998e-01 ... -2.8229785e-01 -2.0000406e-01 -1.9687998e-01] ... [-1.9687998e-01 -1.1853814e+00 -2.4103365e+00 ... -1.9687998e-01 -1.9687998e-01 -1.9687998e-01] [-1.9687998e-01 1.1297071e-01 7.4701560e-01 ... -1.9687998e-01 -1.9687998e-01 -1.9687998e-01] [-1.9687998e-01 1.0522407e-01 5.1278579e-01 ... -1.9687998e-01 -1.9687998e-01 -1.9687998e-01]]]
ソースコードの5-6行目で、学習済みCNNモデルのうち、入力層からconv1レイヤまでのニューラルネットワークモデルを新たに生成し、model_to_conv1とします。
次に、学習用MNISTデータのうち、最初(ゼロ番目)のデータを取り出し、4次元配列の(1, 1, 28, 28)に変換し、image0とします。
それを、model_to_conv1に入力すれば、出力結果conv1_outputを得ることができます。
ただ、その出力結果はテンソル形式のため、自分が分かり易いようにNumPy配列に変換して表示させています。
では、これが理解出来たら、以下のように各々の全レイヤについて、中間層出力させてみると、以下の感じになります。
# 学習済みモデルから中間層のデータを出力する
# ModelクラスAPIをインポート
from keras.models import Model
# 入力層から各々出力する中間層までのニューラルネットワークモデルを生成
model_to_conv1 = Model(inputs=model.input,
outputs=model.get_layer('conv1').output)
model_to_maxpool1 = Model(inputs=model.input,
outputs=model.get_layer('maxpool1').output)
model_to_conv2 = Model(inputs=model.input,
outputs=model.get_layer('conv2').output)
model_to_maxpool2 = Model(inputs=model.input,
outputs=model.get_layer('maxpool2').output)
model_to_conv3 = Model(inputs=model.input,
outputs=model.get_layer('conv3').output)
model_to_flat1 = Model(inputs=model.input,
outputs=model.get_layer('flat1').output)
model_to_dense1 = Model(inputs=model.input,
outputs=model.get_layer('dense1').output)
# 学習用MNISTデータの最初の画像(ゼロ番目)を取り出して、4次元配列に変換しておく
# ※channels_firstになっていることに注意
image0 = train_images[0].reshape(1, 1, 28, 28)
# 中間層までのモデルに最初の画像(ゼロ番目)の学習用MNISTデータを入力させて、出力結果を取得
conv1_output = model_to_conv1(image0)
maxpool1_output = model_to_maxpool1(image0)
conv2_output = model_to_conv2(image0)
maxpool2_output = model_to_maxpool2(image0)
conv3_output = model_to_conv3(image0)
flat1_output = model_to_flat1(image0)
dense1_output = model_to_dense1(image0)
# 出力結果はテンソル形式データのため、NumPyに変換して表示
print("中間層の出力表示")
print('conv1値\n', conv1_output[0].numpy())
print('\nmaxpool1値\n', maxpool1_output[0].numpy())
print('\nconv2値\n', conv2_output[0].numpy())
print('\nmaxpool2値\n', maxpool2_output[0].numpy())
print('\nconv3値\n', conv3_output[0].numpy())
print('\nFlatten値\n', flat1_output[0].numpy())
print('\nDense(Affine)値\n', dense1_output[0].numpy())
【実行結果】
中間層の出力表示 conv1値 [[[-3.9115820e-02 -3.9115820e-02 -3.9115820e-02 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02] [-3.9115820e-02 -3.9115820e-02 -3.9115820e-02 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02] [-3.9115820e-02 -3.9115820e-02 -3.9115820e-02 ... -3.4770688e-01 -2.4737933e-01 -3.9115820e-02] ... [-3.9115820e-02 1.9038574e-01 1.7687529e+00 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02] [-3.9115820e-02 1.5957862e-01 4.5281295e-02 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02] [-3.9115820e-02 1.8356301e-02 8.3339930e-02 ... -3.9115820e-02 -3.9115820e-02 -3.9115820e-02]] ・・・・・・・・・・・・・・・・・・・・ ・・・・・・・<中略>・・・・・・・・・ ・・・・・・・・・・・・・・・・・・・・ conv3値 [[[ 0.16263592 -0.42719412 -0.13076615] [ 1.510721 0.62178487 1.2423201 ] [ 0.7155005 0.28999722 0.41615474]] [[-0.1965121 1.0598183 1.2359684 ] [-0.16046584 0.26594007 0.8125322 ] [ 1.125865 1.6136291 0.82127964]] [[ 0.15682626 1.2457205 1.1044141 ] [ 1.6930487 1.4858665 1.1151228 ] [ 1.4248376 0.58455145 -0.43506986]]] Flatten値 [ 0.16121699 -0.40297374 -0.13002585 0.9070669 0.55236953 0.846116 0.61411446 0.28213224 0.3936861 -0.19402099 0.7855944 0.8443018 -0.15910256 0.259843 0.6709848 0.8095994 0.92369455 0.6757658 0.15555309 0.8470793 0.802079 0.9345343 0.90256125 0.8058658 0.89060384 0.5259657 -0.40954953] Dense(Affine)値 [-13.94474 -4.919732 -3.285744 13.196788 -10.224747 17.507172 -11.496836 -2.9628277 6.5043454 4.541171 ]
この実行結果全てのデータを4章で作ったExcel表と照らし合わせても良いのですが、実は最後のDense(Affine)値だけチェックすれば良いのです。
それが合っていれば、恐らく他の全ても合っているはずです。
下図のような感じです。
(図05_01)
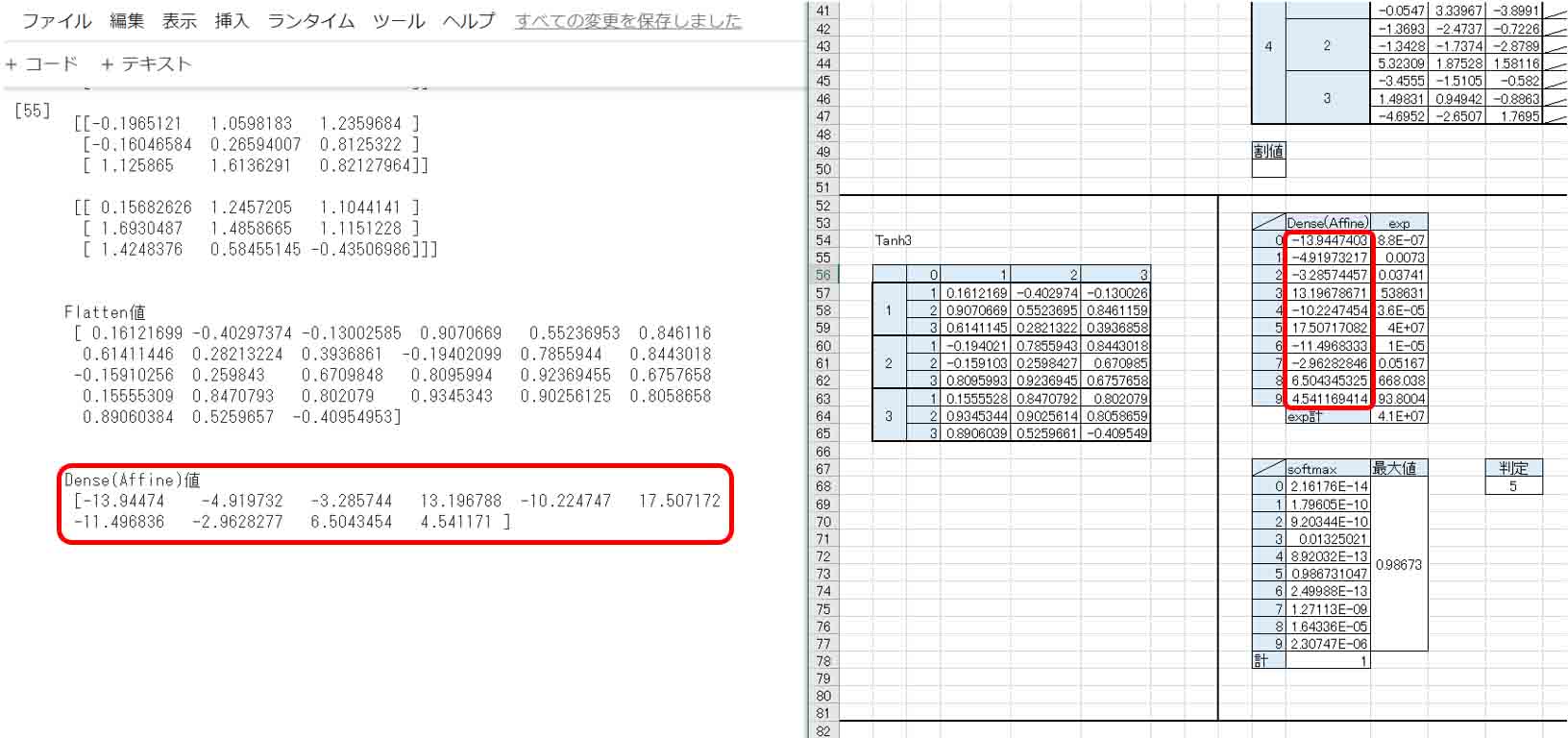
やったー!
Excelで作ったニューラルネットワークとピッタリ計算結果が合いました。
Denseの前段のFlatten値もピッタリ合っています。
Excelでニューラルネットワークを組むと実感できると思うのですが、かなり緻密な計算で最終のDense値まで導き出されているので、この数値がピタリと一致すれば、ほかの出力も絶対にぴたりと一致していると言えます。
ここまでの複雑なネットワークだと、たまたま値が一致したっていうことは無いと言えます。
そういう場合は、入力層の値が全てゼロか又は1の時くらいだと思います。
これがある意味ニューラルネットワークの特徴かもしれませんね。
これで、Google ColaboratoryのKerasでディープラーニングさせても、他のソフトや組み込みマイコンでもニューラルネットワークを再現できる道筋ができました。
めでたし、めでたし。
6.まとめ
今回は、学習済みモデルを読み込んで、重みとバイアスを抽出したり、CSVファイルに出力したり、Excelでニューラルネットワークを再現したり、中間層の出力データを確認したりしました。
以上のことができるようになれば、他のソフトウェアや組み込みマイコンへの応用が利くと思います。
TensorFlowやKerasは、サラッと使ってみただけでは内部で何をやっているか全く掴めませんが、今回のように実際に出力結果を確認しながらExcelで再現できるようになると、かなり内容が見えてきますね。
そうなると、いろいろ自由度が増して、使い易くなる気がしました。
ということで、今回はここまでです。
次回は、入力データセットを独自に組み上げてみたいと思います。
ではまた・・・。
Amazon.co.jp 当ブログのおすすめ












コメント