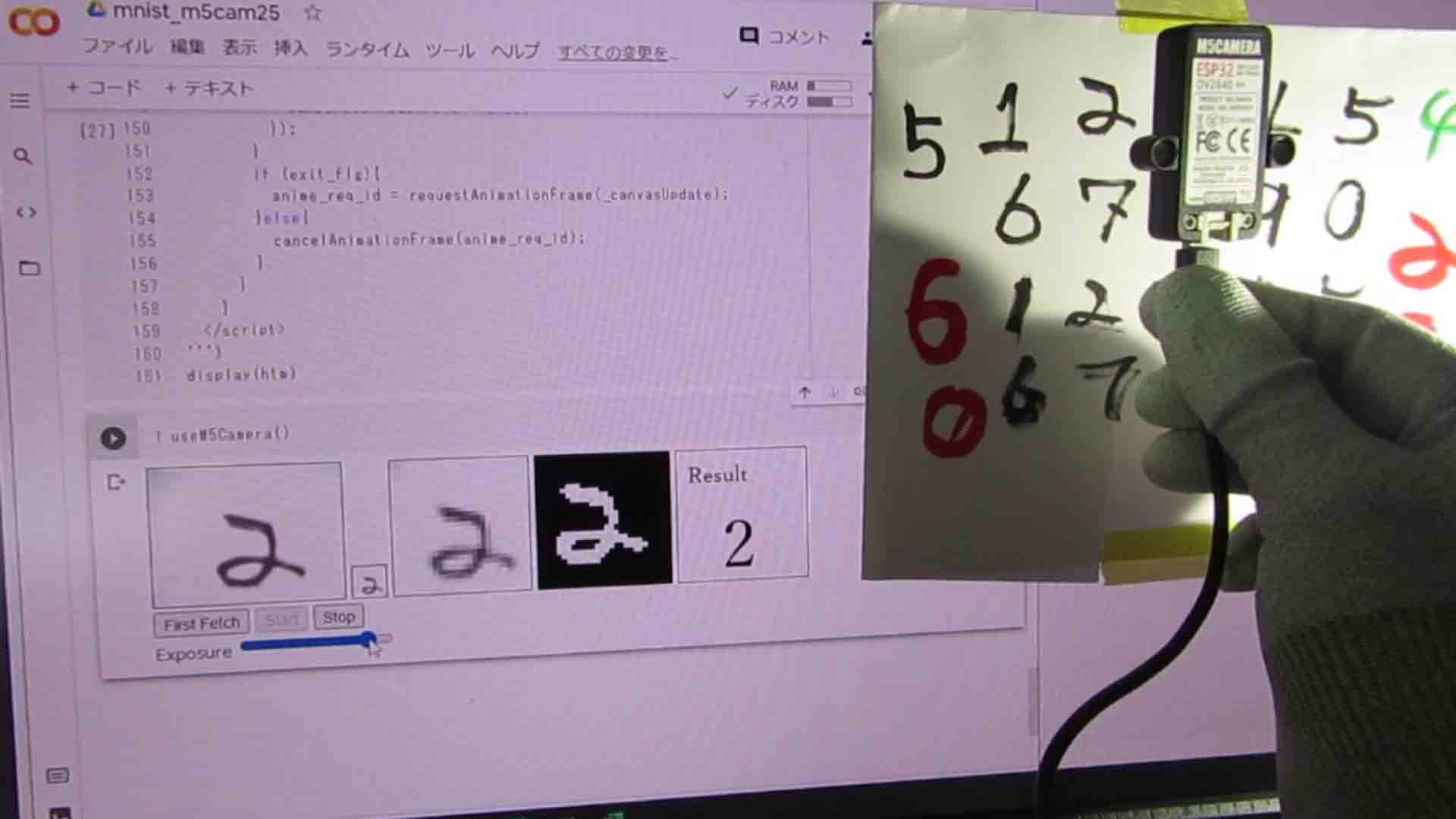
今回は、前回記事で紹介した方式を使って、Google Colaboratory上に表示させたM5Cameraの動画データを機械学習モデルに入力してリアルタイム推論させてみる実験をしてみました。
推論計算速度はコールバック関数を使っているため少々遅いですが、個人的には上出来でした。
何はともあれ、以下の動画をご覧ください。
この推論モデルは、手書き数字MNISTを使って独自のCNN(畳み込みニューラルネットワーク)モデルを作って学習させて、正答率が約98%のものを使いました。
この動画を見てお分かりのように、YouTube動画撮影用にセットすると、被写体への光の当たり具合が均等にならず、M5CameraのExposure(露出)を頻繁に変える必要がありました。
文字のカスレ具合や、色によってもある程度露出を変える必要がありました。
(ホワイトバランスは自動制御に設定しています。)
それでも、ハッキリとした黒い文字ならば、かなりの確率で手書き数字を認識してくれているので、推論モデルとしては上出来ではないでしょうか。
認識率の悪かった数字は、その画像で再学習させればもっと良くなると思いますが、それは今後の課題とします。
このように、Google Colaboratory上で推論モデルの確認がリアルタイムでできれば、Google Colaboratoryによる作業の効率が良くなるのではないかと個人的に思いました。
ということで、今回の実験を紹介して行きます。
なお、私はディープラーニングもプログラミングも独学で素人です。
間違い等がありましたら、コメント投稿でご連絡いただけると助かります。
事前準備
手書き数字MNISTデータセットで機械学習させて推論モデルを作成し、Googleドライブに保存しておく
以下の記事を参照して、Google Colaboratoryで手書き数字MNISTデータセットを使ったCNN(畳み込みニューラルネットワーク)を作成し、機械学習させて、推論モデルを作成しておきます。
その後、Google DriveへモデルをHDF5(H5)形式で保存しておきます。
ディープラーニングのお勉強~その9。Google Colab Kerasのレイヤー設定を独自に解釈してみた~
Basic認証有りのngrokを使って、Google Colaboratory上にM5Cameraの映像をストリーミングできる状態にしておく
前回の以下の記事を参照して、ngrokのBasic認証を使って、M5Cameraの映像をGoogle Colaboratoryに表示できるようにしておきます。
ngrokによるBasic認証M5Cameraサーバーの映像をGoogle Colaboratoryに表示させてOpenCVで画像処理させてみた
Google ColaboratoryのPythonおよびJavaScriptコード
では、Google ColaboratoryのJupyter Notebookに入力するPythonおよびHTML、JavaScriptコードを紹介していきます。
なお、先ほども述べたように、私はプログラミングも機械学習も趣味程度の独学です。
誤り等ありましたら、コメント投稿等でご連絡いただけると助かります。
Google Driveから学習済みモデルをインポート
まず、Jupyter NotebookにGoogle Driveをマウントしておきます。
(マウント法方法はこちらの記事を参照)
その後、先ほどGoogle Driveに保存しておいた、HDF5(H5)形式のCNN(畳み込みニューラルネットワーク)モデルを読み込むPythonコードを以下のように入力します。
最後に確認のためのサマリー表示させています。
因みに、この学習済みデータはGitHubのこちらにmnist_model01.h5というファイル名でしばらく置いておきますので、よかったら使ってみて下さい。
Google Driveのパスは自分が保存したパスに書き換えておいてください。
# 学習済みモデルh5ファイルを読み込んで出力
# ※必ずGoogleドライブをマウントしておくこと
# load_modelをインポートする
from tensorflow.python.keras.models import load_model
# modelへ保存データを読み込み
model = load_model('/content/drive/MyDrive/xxxxx/mnist_model01.h5')
model.summary()
コールバック関数内で推論モデルを組み込む
これは、次の節で紹介しているJavaScriptコードの127行目の
google.colab.kernel.invokeFunction
で呼ばれるコールバック関数を定義しています。
import IPython
from google.colab import output
import cv2
import numpy as np
from PIL import Image
from io import BytesIO
import base64
def run(img_str):
# Base64文字列をデコード
decimg = base64.b64decode(img_str.split(',')[1], validate=True)
decimg = Image.open(BytesIO(decimg)) #PIL形式でメモリ上のファイルを開く
decimg = np.array(decimg, dtype=np.uint8) #Open CVは基本的にNumPy配列
# BGR→グレースケールに変換。shape(28, 28)になる
decimg = cv2.cvtColor(decimg, cv2.COLOR_BGR2GRAY)
# OpenCV用にshape(28,28)→(28, 28, 3)にコピースタックして次元追加。
# 2次元目に追加すること
decimg = np.stack([decimg, decimg, decimg], 2)
#print(decimg.shape)
# ガウシアンブラーでノイズをボカしてもよいかも。
#decimg = cv2.GaussianBlur(decimg, (1, 1), 3)
decimg = 255 - decimg #白黒反転
# 画像を2値化
decimg = cv2.threshold(decimg, 30, 255, cv2.THRESH_BINARY)[1]
tmp_decimg = decimg
# shape(28,28,3)→(3,28,28)channel_firstに変更
decimg = np.transpose(decimg, [2, 0, 1])
# shape次元消去
decimg = np.delete(decimg, 1, axis=0)
decimg = np.delete(decimg, 1, axis=0)
# 0~255の値を0~1.0の値へ正規化する
decimg = decimg.astype('float32')
decimg = decimg / 255.0
# modelに入力するためにshape整形
decimg = decimg.reshape(1, 1, 28, 28)
# 先に読み込んだ学習済みモデルで推論
model_result = model.predict_on_batch(decimg)
# 推論結果配列からインデックスを取得
model_result = model_result[0].argmax()
# JPEG形式にエンコード。最初のアンダースコアは、返り値のbool値を無視するという意味
_, encimg = cv2.imencode(".jpg", tmp_decimg, [int(cv2.IMWRITE_JPEG_QUALITY), 80])
img_str = encimg.tobytes() #NumPy配列をバイト配列に変換
# Base64形式文字列に変換
img_str = "data:image/jpeg;base64," + base64.b64encode(img_str).decode('utf-8')
return IPython.display.JSON({'model_result': model_result, 'img_str': img_str})
output.register_callback('notebook.run', run)
【ザッと解説】
ここでは、M5Cameraから取得したJPEG画像をビットマップに変換してOpenCVでグレースケール画像に変換し、画像を2値化して、先ほどインポートした学習済みモデルに入力させて推論させています。
後で紹介しているJavaScriptコードで取得したM5CameraのJPEG画像は、Base64エンコードされたテキスト形式データなので、それをバイナリ形式に変換して、NumPy配列に変換します。
OpenCVはNumPy配列でやり取りするためです。
そして、15行目のcv2.cvtColorでカラー画像をグレースケール(白黒)画像に変換します。
ここで注意することは、13行目のNumPy配列に変換した時点では、shapeで次元数を確認すると、(28, 28, 3)となっているのに、cv2.cvtColor関数でグレースケールにすると、shapeが(28, 28)になってしまって配列の次元が減ってしまいます。
基本的にOpenCVの関数はフルカラー映像を扱うものだと思われ、他のOpenCV関数に単色次元の画像配列を渡してしまうとエラーになってしまいました。
よって、18行目にあるように、単色の全く同じ画像データでスタックして、BGR次元と同じ配列のshape = (28, 28, 3) にしました。
もっとスマートな方法があったら教えてください。
その状態で、白黒反転させて、26行目のように2値化変換のcv2.threshold関数へ渡すと、問題無く動作しました。
因みに、2値化というのは、例えば画素の明るさが30以下の場合は0とし、それ以上は全て255とするものです。
それくらいだったらOpenCVを使わずとも、自分でプログラミングして処理しても良いかも知れませんが、せっかくなので今回はOpenCVを使ってみました。
その後は、学習済みモデルに入力するためには、以下のようにshapeを変換します。
(28, 28, 3) → (1, 1, 28, 28)
これは私が作ったこちらの記事のモデルがchannel_firstだからです。
また、0~255の値を0.0~1.0へ変換する正規化も行います。
それでようやく、42行目のように、model.predict_on_batchへ入力して推論しています。
返り値は、10個の配列で確率値です。
その確率が高いところが推論結果なので、そのインデックスを取得すれば良いわけです。
インデックス取得は、44行目のargmax関数を使います。
あとは、画像データをBase64エンコードして、コールバック関数でJavaScriptへ返してやります。
52行目のように、JSON形式で画像データと推論結果という複数の値が返せるというのは良いですね。
IPythonでHTMLおよびJavaScriptを入力
これは前回や前々回の記事で紹介した、IPythonを用いてHTMLおよびJavaScriptを使うコードです。
from IPython.display import display, HTML
def useM5Camera():
htm = HTML('''
<style>
.box{border: 1px solid}
</style>
<div>
<img id='id_mjpeg' class='box' crossOrigin='use-credentials'>
<canvas id='canvas28x28' class='box'></canvas>
<canvas id='canvas_zoom' class='box'></canvas>
<canvas id='canvas_cv' class='box'></canvas>
<canvas id='canvas_txt' class='box'></canvas>
</div>
<div>
<button onclick='firstFetch()'>First Fetch</button>
<button id='btn_start' onclick='startStream()'>Start</button>
<button id='btn_stop' onclick='stopStream()'>Stop</button>
<div>Exposure
<input type='range' id='aec_val' max='255' onchange='aecVal()'>
</div>
</div>
<script type='text/javascript'>
const url_ngrok = 'https://xxxxxxxx.jp.ngrok.io',//自分のngrokサーバーに書き換える
url_mjpeg = url_ngrok + '/stream';
//Basic認証のパスワードはブラウザで手入力する。
let exit_flg = true;
const img_width = 160, img_height = 120,
src_canvas_w = 28, src_canvas_h = 28;
const mjpeg = document.getElementById('id_mjpeg');
mjpeg.width = img_width;
mjpeg.height = img_height;
const src_canvas = document.getElementById('canvas28x28'),
src_canvasCtx = src_canvas.getContext('2d');
src_canvas.width = src_canvas_w;
src_canvas.height = src_canvas_h;
const zoom_canvas = document.getElementById('canvas_zoom'),
zoom_canvasCtx = zoom_canvas.getContext('2d');
zoom_canvas.width = 120;
zoom_canvas.height = 120;
const cv_canvas = document.getElementById('canvas_cv'),
cv_canvasCtx = cv_canvas.getContext('2d');
cv_canvas.width = 120;
cv_canvas.height = 120;
const txt_canvas = document.getElementById('canvas_txt'),
txt_canvasCtx = txt_canvas.getContext('2d');
txt_canvas.width = 120;
txt_canvas.height = 120;
txt_canvasCtx.font = "20px serif";
txt_canvasCtx.fillText('Result', 10, 30);
const btn_start = document.getElementById('btn_start'),
btn_stop = document.getElementById('btn_stop'),
range_aec = document.getElementById('aec_val');
btn_start.disabled = true;
btn_stop.disabled = true;
function firstFetch(){
btn_start.disabled = false;
btn_stop.disabled = false;
exit_flg = false;
changeCtrlCam('first',0);
}
async function startStream(){
btn_start.disabled = true;
exit_flg = true;
let d = new Date();
mjpeg.src = url_mjpeg + '?' + d.getTime();
mjpeg.onload = useOpenCV();
}
function stopStream(){
btn_start.disabled = false;
exit_flg = false;
changeCtrlCam('stop_stream',0);
}
function aecVal(){
let aec_val = range_aec.value;
changeCtrlCam('aec_val',aec_val);
}
async function changeCtrlCam(var_txt, value_txt){
let ctrl_url = url_ngrok + '/control?var=';
ctrl_url += var_txt + '&';
ctrl_url += 'val=' + value_txt;
await fetch(ctrl_url, {
method: 'GET',
credentials: 'include', //これ重要
mode: 'cors'
})
.then(response => response.text())
.then(data => console.log(data));
}
function useOpenCV() {
const jpg_quality = 0.8;
let canSendCallbackFunc = true,
anime_req_id = 0;
_canvasUpdate();
function _canvasUpdate(){
src_canvasCtx.drawImage(mjpeg, 20, 0, 120, 120, 0, 0, 28, 28);
var imageData = src_canvasCtx.getImageData(0, 0, 28, 28);
const img_url3 = src_canvas.toDataURL('image/jpeg', jpg_quality);
let image3 = new Image();
image3.src = img_url3;
image3.onload = function(){
//アンチエイリアシング解除。(デフォルトはON)
//zoom_canvasCtx.mozImageSmoothingEnabled = false;
//zoom_canvasCtx.webkitImageSmoothingEnabled = false;
//zoom_canvasCtx.msImageSmoothingEnabled = false;
zoom_canvasCtx.imageSmoothingEnabled = false;
zoom_canvasCtx.drawImage(image3, 0, 0, 28, 28, 0, 0, 120, 120);
};
if(canSendCallbackFunc){
const img_url = src_canvas.toDataURL('image/jpeg', jpg_quality);
const result = google.colab.kernel.invokeFunction('notebook.run', [img_url], {});
canSendCallbackFunc = false;
result.then(function(value) {
//console.log(value); //valueはJavaScriptオブジェクト
const m_result = value.data['application/json'].model_result;
const cv_img_url = value.data['application/json'].img_str;
let image = new Image();
image.src = cv_img_url;
image.onload = function(){
//アンチエイリアシング解除。(デフォルトはON)
//cv_canvasCtx.mozImageSmoothingEnabled = false;
//cv_canvasCtx.webkitImageSmoothingEnabled = false;
//cv_canvasCtx.msImageSmoothingEnabled = false;
cv_canvasCtx.imageSmoothingEnabled = false;
cv_canvasCtx.drawImage(image, 0, 0, 28, 28, 0, 0, 120, 120);
};
txt_canvasCtx.font = "60px serif";
txt_canvasCtx.clearRect(0, 50, 120, 70);
txt_canvasCtx.fillText(m_result, 40, 110);
canSendCallbackFunc = true;
});
}
if (exit_flg){
anime_req_id = requestAnimationFrame(_canvasUpdate);
}else{
cancelAnimationFrame(anime_req_id);
}
}
}
</script>
''')
display(htm)
【ザッと解説】
基本的に、前回記事のコードをベースにしています。
24行目で新たに発行したBasic認証有りのngrokアドレスに書き換えます。
また、前回記事で紹介したように、96行目のcredentialsは重要なところです。
ただ、今回は、160×120 pixelのM5CameraからのJPEG画像を、MNISTデータセットと同じ28×28 pixelに縮小し、それをコールバック関数へ送っています。
あとは、確認のためにその画像を120×120 pixelに引き伸ばして表示させているだけです。
127行目のコールバック関数で返ってきたデータは、JSON形式というよりもJavaScriptオブジェクトです。それは、132-133行目でOpenCV加工後の画像データと、推論モデルから得た結果を抽出します。
そして、それぞれHTMLのCanvasに表示させているというわけです。
このように、今回の実験で、PythonとJavaScript間で複数のデータを受け渡しできるというのがわかりました。今後何かと使えそうです。
実行関数セル入力(2021/06/25追加)
すっかり忘れていましたが、セルをもう一つ入力することを忘れていました。
以下の一行の関数セルを追加するだけです。
これは忘れがちですね。これが無いと動きません。失礼しました。
m(_ _)m
useM5Camera()
M5Camera側のスケッチ
M5Camera側のスケッチは前回記事と同じなので、そちらを参照してください。
ランタイム実行
では、Google Colaboratoryのランタイムを実行しますが、ここで注意しなければならないことがあります。
注意点
「ランタイムのタイプを変更」で「GPU」を選択することを忘れずに
今回は、TensorFlowのKerasを使ったディープラーニング学習モデルを使うため、ランタイムをGPUに設定しておかないと動きません。
Google Colaboratoryの「ランタイム」→「ランタイムのタイプを変更」で、「GPU」に変更しておくことです。
忘れがちですので、注意してください。
長時間GPU使うと、使用量上限に達して使用できない
無料のGoogle Colaboratoryでは、長時間GPUを使うと、
「GPUバックエンドに接続できません」
「Colabでの使用料上限に達したため、現在GPUに接続できません」
というメッセージが出て、使用料上限ルールに引っかかる場合があります。
(図10)
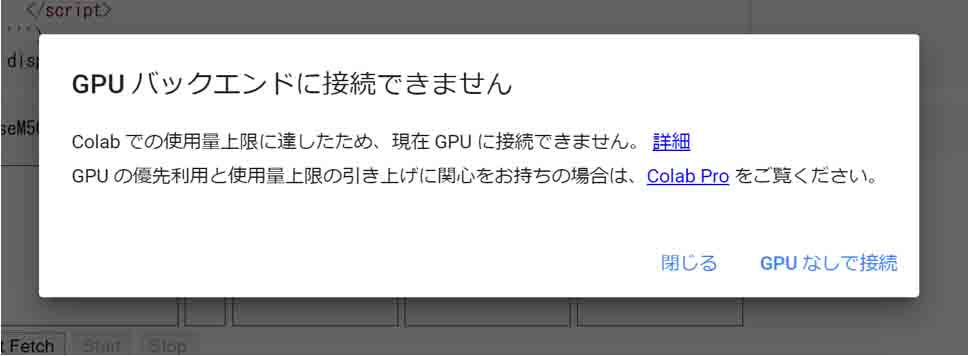
使用量上限でGPUが使用できないメッセージ
そうなった場合は、12~24時間は使えないので諦めるしかありませんね。
もし、長時間GPUを使いたいのであれば、有料のGoogle Colab PROにするか、ローカルランタイム設定をして、自分のPCのGPUを使うしか無いと思います。
ストリーミングは5分程度で強制停止?
因みに、img要素のMotion JPEG動画は約5分経過するとストリーミングが自動停止してしまうようです。
これについて正確な原因は分からないのですが、おそらくブラウザのセッション時間の設定によるものかと思われます。
特に今回のように、異なるソースにアクセスして表示するCROS(Cross-Origin Resource Sharing)の時、長時間セッションを接続したままだと、セキュリティ上問題があるのだと思われます。しかも、HTTPSのSSLでアクセスしていますしね。
ブラウザの設定でセッション継続時間を変更すれば、もっと長時間ストリーミングできるかもしれませんが、セキュリティ上、それは変更しない方が良いかも知れません。というか、設定変更する方法がわかりませんでした。
ただ、同じストリーミングでも、MPEG4などは長時間ストリーミング可能なので、今回のMotion JPEGのビデオストリーミングについては全く別の問題なのだろうと思われます。
これについてはあくまで個人的推測なので、間違えていたらコメント投稿でご連絡いただけると助かります。
全てのセルを実行
では、Wi-Fiルータを起動し、M5Cameraを起動して、Wi-Fiネットワークに接続した状態にしておきます。
そして、上記の注意点を踏まえて、「ランタイム」→「全てのセルを実行」させます。
すると、最初に紹介した動画のように表示すればOKです。
前回記事のように、「First Fetch」ボタンを押すと、ngrokにアクセスしてBasic認証ポップアップウィンドウが表示されるので、ユーザー名やパスワードを入力します。
その後、「Start」ボタンを押すと、<img>要素でMotion JPEGストリーミング開始します。
ただ、M5Cameraの被写体が暗いと判定できないので、ライトを当てて明るくします。
そして、Exposure(露出)スライダーで調整してください。
下図の様に、被写体の明るさやExposure(露出)の具合によって、認識力がかなり違うことが分かると思います。
(図20)
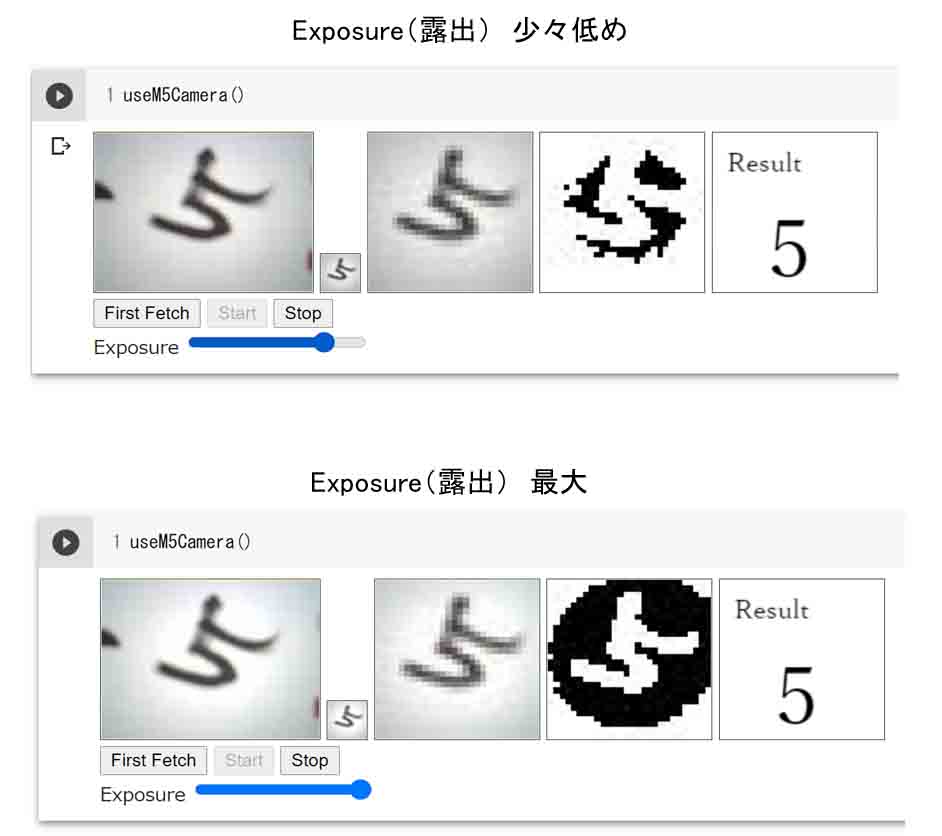
M5Cameraの露出調整で認識率が変わる
これは、OpenCVのcv2.threshold関数で、閾値を30としていることによるものです。
つまり、画素データの値0~255のうち、30以上のものは全て255として真っ白にしてしまうのです。
ですから、上図の画像を見てみると、生の画像の周囲が若干暗めになっています。すると、反転した画像で2値化すると、白くなってしまうのです。
というわけで、被写体を充分明るくして、白い紙が白くなるようにライトを当てなければなりません。
そして、露出調整で画像が認識できるようにしなければならないというところがミソです。
最初の動画を見てもらえれば分かりますが、文字色はやはり黒が良いですね。
では、特殊な例として、下図の様な文字を見てみます。
これは、私の意図では「4」という数字を書いたつもりです。
(図21)
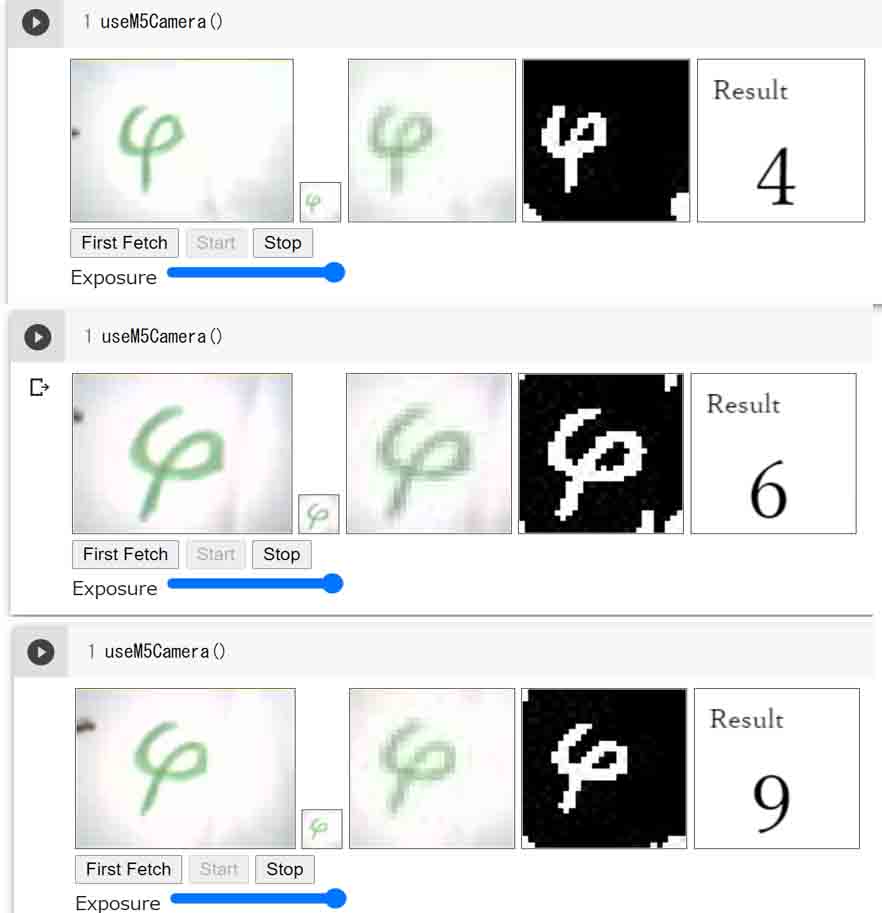
認識が難しい手書き数字の場合
こう見ると、文字の角度や見る方向によっては「6」にも見えるし、「9」にも見えますね。
ですから、この文字の判定(推論)は安定しません。
これを安定させるには、この画像で新たに機械学習させるしかありませんね。
以上から、いくらMNISTで手書き数字を6万件学習させたとしても前処理が悪いと認識率が悪くなるということです。
被写体を明るくしてクッキリ表示させることや、イメージセンサの露出や2値化などの前処理設定が大事だということですね。
これを頭に入れていれば、今後のディープラーニングの勉強に役立つと思われます。
まとめ
以上、Google Colaboratory上でM5Cameraのストリーミングさせながら、MNISTディープラーニングモデルでリアルタイム推論させてみる実験でした。
推論モデルで正しい判定を得るには、被写体を充分明るくしたり、イメージセンサの露出を適度に調整するなど、前処理が大事だということが良くわかりましたね。
モデルの推論計算はコールバック関数を使っているので速度は遅いですが、個人的にはここまで出来れば十分だと思いました。
ただ、無料のGoogle Colaboratoryでは、GPU使える時間が限られているので、長時間の推論モデルを試したい場合は、Google Colaboratory PRO にするとか、ローカルランタイムを使うとか、推論モデルをマイコンに組み込んでしまうとかしなければなりませんね。
というわけで、今回はここまでです。
ではまた…。
コメント