今回はディープラーニングのお勉強第8弾として、Google Colaboratoryを使ってPythonプログラミングしてみた使用感および雑感を述べてみたいと思います。
当ブログのディープラーニングのこれまでの勉強シリーズで、なぜここでいきなりGoogle Colaboratoryを使うことになったのか、ということや、そこで使うPython環境、Jupyter Notebook、TensorFlow、Keras等のツールの個人的な感想や疑問点を述べてみたいと思います。
ネット上ではGoogle Colaboratoryの情報は有り余るほど沢山ありますが、私はPythonやKerasは全くの初心者なので、自分なりの視点で軽く紹介してみたいと思います。
簡単に言うと、Google Colaboratoryセットアップはと~っても簡単!
そして、Pythonプログラミングはと~っても手軽!
そしてそして、行列演算がメチャメチャ楽!
でも、無料で簡単ゆえの欠点もありました。
プログラミングやディープラーニングを知らずにいきなりGoogle Colaboratoryを始めても、意味がサッパリ分からないと思います。
正直言ってビギナー向けではありません。
かなりブラックボックス化されているので、ある程度プログラミングを学んで、ディープラーニングも勉強してからGoogle Colaboratoryを使えば、かなり便利だなという感じです。
個人的に思ったのは、当ブログのディープラーニングの勉強その1、その2、その3にあるように、ExcelでディープラーニングをやってみてからGoogle Colaboratoryを使うと理解しやすいかと思いました。
実は、つい最近まで、Kerasでニューラルネットワークのレイヤーを組んでいて、パラメータ設定方法があまりにも難解で、いろいろネットで調べまくっていました。
やっと、ここ数日、かなりの線まで自分なりに解明できました。
ただ、今回上げようとした記事があまりにも長くなってしまったので、2分割することにしました。
そんなこんなで、今回はGoogle Colaboratorの雑感だけ述べていきます。
- Google Colaboratory雑感
- Google Colaboratoryのセットアップ方法
- Pythonを初めて使ってみた雑感
- チュートリアルを参考にしてMNISTデータセットでCNNを組んでディープラーニングしてみる
- まとめ
【目次】
1.Google Colaboratory雑感
1-01. なぜGoogle Colaboratoryを使うことにしたのか(メリット等)
以前のこちらの記事で、イメージセンサを積んだWiFiマイコン、M5Cameraと、LCD付きマイコンモジュールM5Stackでディープラーニング画像認識を実験しましたが、この場合、事前に用意された手書き数字MNISTデータセットを学習用データとして使いました。
これから本格的にディープラーニングをやろうとすると、イメージセンサで独自に取得した画像から新たに学習用データセットを作って機械学習させなければなりません。
その場合、組み込みマイコンで画像データを保存させて学習させるには、スペックが小さすぎてとても無理なので、画像データをブラウザに表示させて、それをパソコンに動的に保存してデータセットを作り、パソコンで学習させた方が断然効率的で速いです。
パソコンで学習させたモデルの重みとバイアスデータを使って、マイコンにニューラルネットワークだけをプログラミングできれば、AI搭載マイコンのような動作をさせることができます。
そして、ブラウザで画像データを保存してデータセットを作るなら、ブラウザで動作するJavaScriptでディープラーニング出来た方が、将来的には何かと有利だろうと思うに至ったわけです。
翌々は、新たな画像を自動的に保存しながら自動的に再学習させて、重みデータを更新できるようにすることができたら良いなと思いました。
そうすると、JavaScriptでディープラーニングができるのは、Googleが開発したオープンソースライブラリのTensorFlowがあるということを知りました。
そして、そのTensorFlowを使ってみようとしたら、KerasやJupyter Notebookを使えと書いてあったんです。
何それ???
謎ツールが多すぎる!!!
と、思いました。
最初はJupyter NotebookをローカルPC環境で使ってみようといろいろ調べたんですが、Python環境構築の前にAnacondaをインストールが必要とかあって、意味不明なライブラリが浮上してきて、「何て面倒なんだ!」とウンザリしていました。
これはビギナーにとってはとても敷居が高いなと思いましたね。
以前まで使っていたSONY Neural Network Consoleの方が断然簡単でした。
そんなこんなで、Twitterでウンザリ感をつぶやいていたら、Google Colaboratoryが良いのではないかという情報をある方から頂きました。
そこで、ある時、TensorFlow入門者向けチュートリアルを見てみると、Google Colaboratoryノートブック形式で書かれているのを見ました。
なら、試しに使ってみるか!
と、なったわけです。
そしたら、何と、セットアップ一切無しでいきなり普通に使えたんです。
しかもブラウザ上です。
なーんだ、こんな簡単な方法があるじゃないか!
さすが、いろいろ考え尽くされているな!
と感心しました。
そんなこんなでGoogle Colaboratoryを使うことにしたわけです。
ちょっと使ってみた感じでメリットを述べると、
●Google Colaboratory (略してGoogle Colab)とは、セットアップ不要で、ブラウザ上でいきなりTensorFlow、Kerasを使ってディープラーニングをすることができる。
●ブラウザ上のPythonプログラミングで、自分の意図した入力や出力およびニューラルネットワークを組み上げることが出来る。
●Jupyter Notebook環境が良い。セルごとに実行結果を出力できる。
●クラウド上のGPUやTPUを使ってディープラーニングができるので、パソコンの負荷が無い。
(ただし少々条件があります。後で述べます)
というところでしょうか。
今まで、SonyのNeural Network Consoleを使っていましたが、それとの違いは、自分でPythonプログラミングすれば、自由に入力データセットを組んだり、出力データの個数や構成を変えたり、自由に変更できるということですかね。
ただ、Google Colaboratoryにはちょっとしたデメリットがありました。
それは後で述べます。
1-02. Jupyter Notebook というツール
Google Colaboratory はセットアップ無しでいきなりPythonプログラミングやTensorFlow、Kerasが使えますが、それは、ブラウザ上のJupyter Notebookというツール上でプログラミングすることになります。
始めて使う人は何だか良く分らないと思いますが、ただ単にブラウザ版開発環境みたいなもんです。
お馴染みのArduino IDEがブラウザで動くような感じだと思えば良いかと思います。
個人的に感じるのは、最近のGoogleと言えば、何でもブラウザで実現しようという意図が見受けられますので、そこで動作するPython開発環境を提供するのは納得しますね。
確かにブラウザで動作するというものは、インストールの面倒さが軽減できるし、基本的にOSやパソコンの機種を選びませんので、賢い選択だと思います。
ただ、全てがお膳立てされているので、オープンソースとはいえ、Googleの手のひらで踊らされている感が強いです。
今の世では仕方のないところですかね。
また、Jupyter NotebookのPython環境で面白いなと思ったのは、「セル」という構成です。
その、ソースコードをセルという単位で一括りに分割できて、そのセルごとにビルドできて、すぐ下に実行結果が表示されるところです。
そして、テキスト用のセルというものを間に入れて、解説やグラフ等を同時に表示できるところです。
プログラムの途中でテキストセルがあってもビルドOKというやつです。
下図の様な感じです。
(図01_02_01)
これって、スゴイと思いませんか?
Arduinoなどのプログラミングの場合、説明文はコメント行ですし、実行結果は別ウィンドウで表示ですが、こうやってセルごとにコードを分けて、一つの論文のように表示できるっていうのは私個人としてはとても新鮮でしたね。
確かにJupyter Notebookは、ソースコードやその実行結果について、間に説明文を書くと他人に説明しやすいだろうし、データ解析などの分野ではものすごく重宝しそうですね。
因みに、一番下のテキストセルはマークダウン記法というちょっと特殊なものです。
テキストの前に「#」を置くと見出し表示となり、文字が大きくなります。
右側にプレビュー画面が出ています。
マークダウン記法は憶えてしまえば簡単です。
GitHubにREADME.txtをアップする場合などに使われるものですから、憶えておいて損はないと思います。
そして、もう一つ面白いのは、Pythonという言語がインタープリタ型なので、1個のプログラムを分割して、間にテキストセルや実行結果を入れても、変数や引数の値が次のコードセルに引き継がれるんです。
たとえば、自作関数1個の動作を確かめたい時に、ArduinoのようなC/C++の場合は、全体をコンパイルしなければなりませんでしたが、PythonのJupyter Notebookでは、セルごとにビルドして実行結果を確かめられます。
これは面白いですね。
ただ、Google Colaboratoryの場合は90分以上操作しないで放置していると、ランタイムというセッションが切れて、セル間の変数値や引数が引き継がれません。
その場合は全セルをビルドしなければいけないところが注意ですね。
これについては、デメリットの章で述べます。
1-03. Kerasってよく言うけど、いったい何?
ディープラーニングについて、Twitterやその他ネットでは、まず、GoogleのTensorFlowというものをよく目にします。
そして、Kerasというものもよく目にします。
それって一体何なの??
種類が多くて意味わからん。
と、いつも思っていました。
そこで、いろいろ調べてみると、Googleの開発したTensorFlowが大元で、その使い方は少々難しいらしく、それをもっと簡単に扱えるようにしたものがKerasというものらしいです。
なーんだ、そういうことか!
TensorFlowは、Googleが開発したオープンソースライブラリで、それを使い易くラッピングしたものがKerasということのようです。
情報がいろいろありすぎて、ビギナーにとっては混乱しますが、ディープラーニングをやるなら、まずは
「Google ColaboratoryのKerasを使え!」
と言ってくれれば、こんなに苦労しないのになと思いました。
Kerasに限らず、オープンソースのライブラリあるあるですが、無料で使うことはできるけど、いろいろなライブラリと合わせて使わないと機能しなかったりしますよね。
だから、結局はいろいろなライブラリやツールで詰め合わせて、ラッピングして開発環境を整えなきゃいけないものなんだなと改めて思いました。
1-04. Google Colaboratoryのデメリット
無料でセットアップ無しで使えて、クラウド上のGPUが使えて、Google Colaboratoryは良いことずくめではないか、と思いましたが、そんなに甘くはありませんでした。
やはり無料なものは何かしらデメリットがあるものです。
使用量上限ルール
まず、私が最初にぶち当たったのは、使用料上限ルールです。
実際、私はクラウドのGPUが使えて「スゲー!」と思いながら、鬼のように機械学習させていました。
そして、翌日、いろいろ設定を済ませて、いざ学習させようと思って実行させると、以下のメッセージを食らいました。
Colab での使用量上限に達したため、現在 GPU に接続できません。
(図01_04_01)
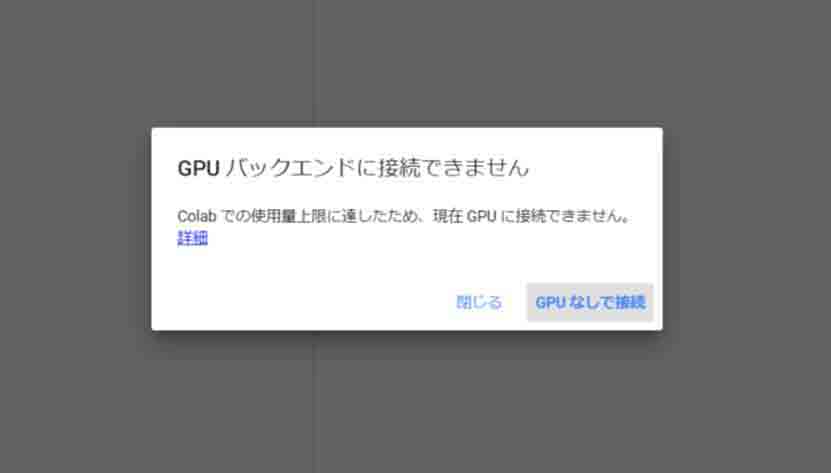
じょ、冗談でしょ!
と思いました。
せっかく時間ができてプログラミングして、いざ学習させようとしたらこのメッセージ。
何にも知らないとショック大きいですよね。
このメッセージが出ると、12時間以上待たないと使えませんでした。
ていうか、丸1日待って、翌日に接続した方が良いです。
1日無駄になってしまいます。
やはり無限にGPU使える訳無いですよね。
もっとクラウドのGPUを多くの時間使いたい場合はColaboratory Proという有料バージョンがあるとのことですが、これはアメリカのアカウントを持っていないと使えないそうです。(2021/1/28時点)
それでも高速のGPUが使えることは有難いことではあります。
90分ルール
90分間、Google Colaboratoryを使わない状態で放置していると、以下のようなメッセージが出ます。
(図01_04_02)
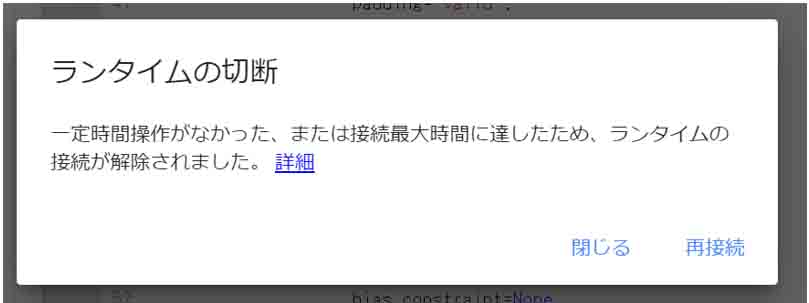
こうなった場合、PythonのJupyter Notebookのメリットであった、セル単位で実行できなく、セル間で変数の値が引き継がれません。
こうなった場合は、改めて、「全てのセルを実行」すれば問題無く使えます。
しかし、1つのセルで計算時間が長い場合はまた同じ時間をかけなければならないという不便さがあります。
これは無料のクラウド環境だから仕方ないですね。
ただ、ローカルランタイム環境というものを自身で構築すれば、この束縛から解放されるようですよ。
12時間ルール
私はまだこのルールに引っかかったことはありませんが、12時間以上連続して機械学習させたりすることができないようです。
私の場合は長くてもまだ2時間程度しかGPUで機械学習させていません。
12時間以上も連続して稼働させるようなら、クラウドをかなり使い込むことになるので、やはり有料版のProに切り替えるしかないでしょうね。
便利さゆえのブラックボックス
あと、もう一つのデメリットとして、個人的に感じたのは、ライブラリ等のツールが予め全部入っているということは、逆に、ブラックボックス化してしまうということです。
パソコンで一からローカル環境構築すれば、ツールやライブラリの意味を調べて理解しながら進められるのですが、全てがお膳立てされていると、自分自身の理解を妨げてしまうように思います。
現に、私はGoogle Colaboratoryでプログラミング最中に、使用しているライブラリの意味が分らなくて、何度もネットで調べるという手間がありました。
意味を調べるだけで1時間以上経ってしまい、90分ルールに引っかかることも度々でした。
意味なんか知らないでどんどん進められる性格の人は良いのですが、私のような人間は進捗がどうしても遅くなりますね。
それと、これはGoogle Colaboratoryに限らないのですが、中間層の出力結果を見る方法がなかなか難しくて、かなりネット検索する羽目になりました。
それに、学習済みのモデルから重みやバイアスデータを抽出する方法も難しく、Excelに落とし込んだり、他の組み込みマイコンにニューラルネットワークを移植たりするのはハードルが高かったです。
SONY Neural Network Consoleもそれなりに難しいのですが、日本語ドキュメントが充実しているのと、ユーザーインターフェースが理解し易いというところはありましたね。
でも、一度、Google Colaboratoryの使い方が分かってしまえば、その後はスラスラと使えるようにはなるかと思います。
今の所感じたデメリットはこんなところです。
2.Google Colaboratoryのセットアップ方法
では、Google Colaboratoryのセットアップ方法について、説明してみたいと思います。
これは、ネットに情報が沢山ありますが、一応紹介してみます。
2-01. Google Colaboratoryの準備
簡単に言うと以下です。
1.Googleアカウントを作っておく
2.Google Chromeブラウザを開き、Googleアカウントにログインしておく
3.Google Colaboratoryサイトを開く
https://colab.research.google.com/
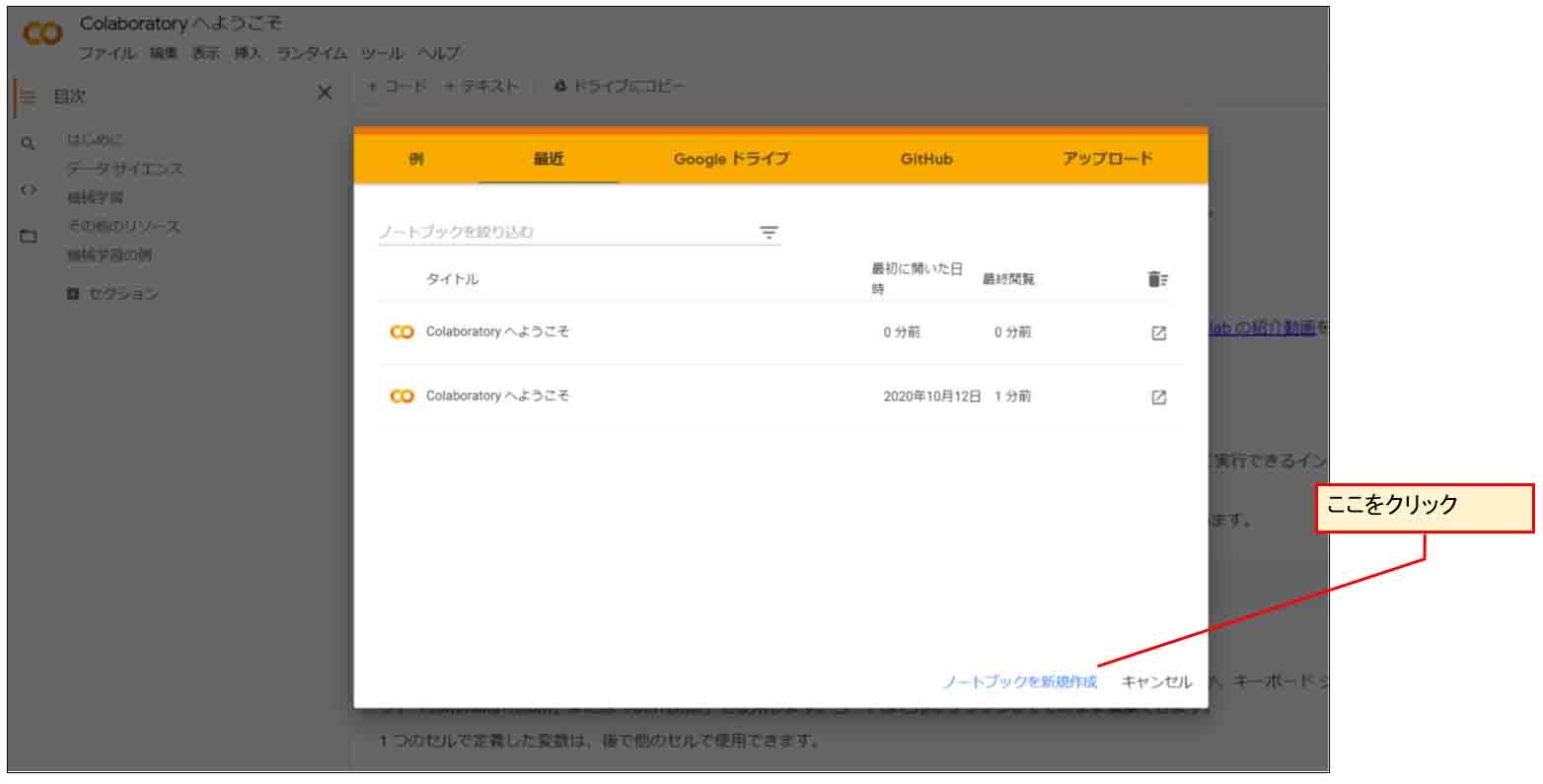
すると、以下のような画面になるので、「ノートブックの新規作成」をクリック。
(図02_01_01)
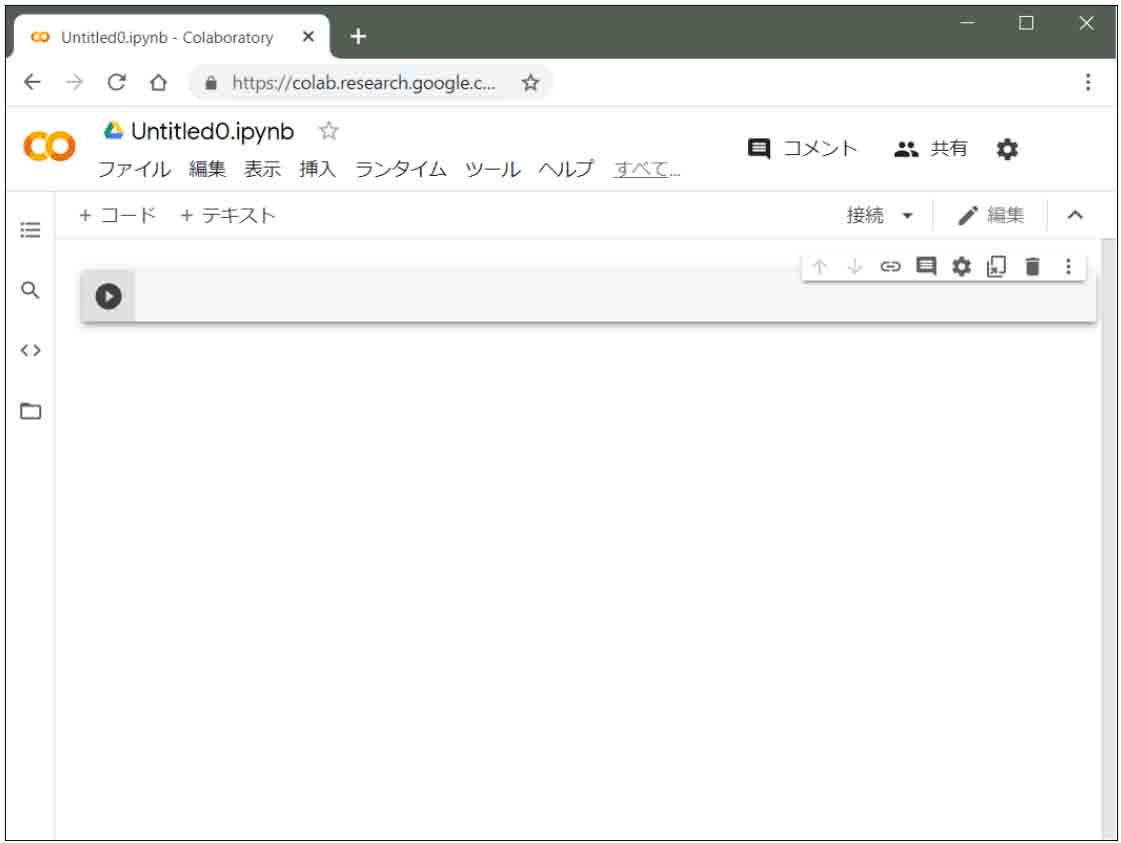
すると、下図の様な画面になって、プログラミング可能になります。
簡単ですね。
(図02_01_02)
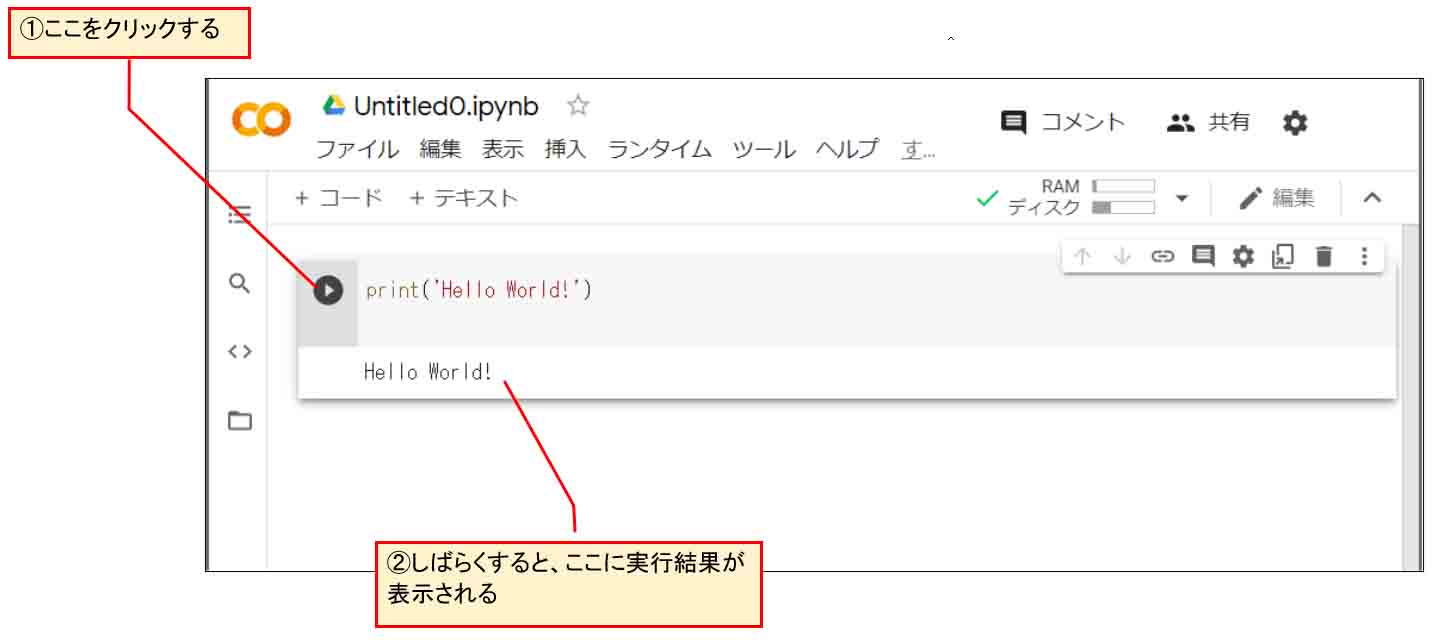
2-02. Hello Worldを表示させてみる
試しに、下図のようにPythonプログラミングでHello Worldを表示させてみて、実行させて動けばOKです。
(図02_02_01)
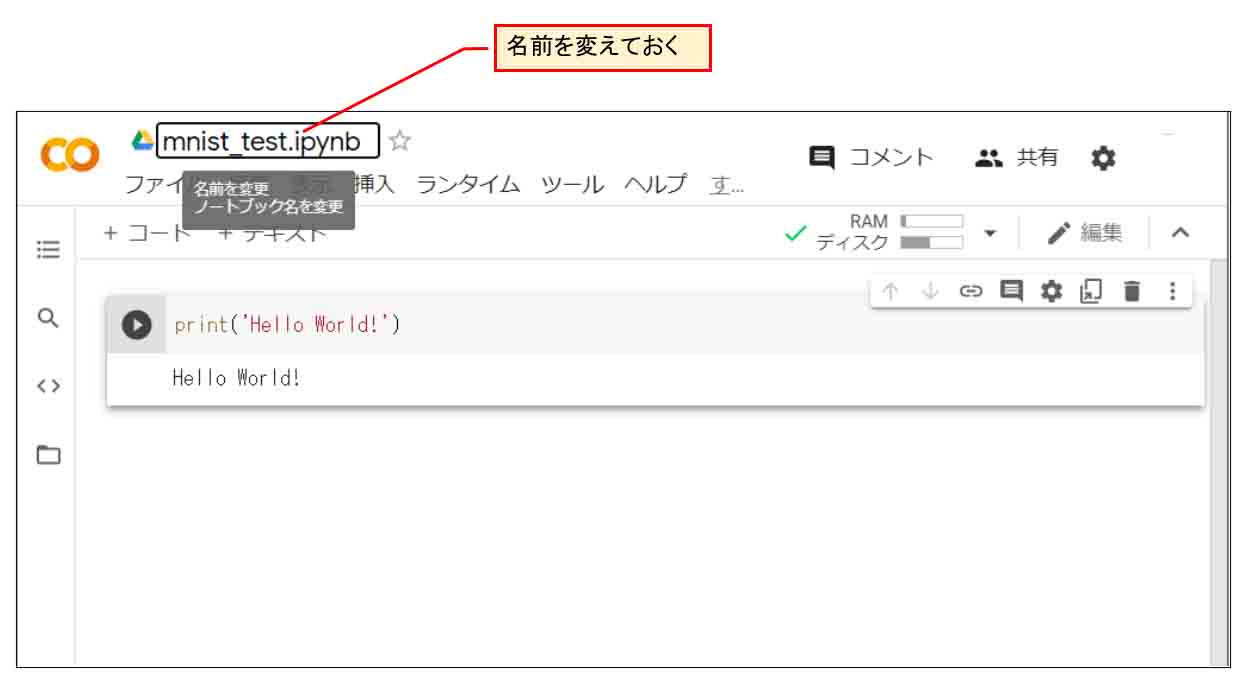
2-03. Google Driveに保存されていることを確認
今度は、このノートブックの名前を変えておきます。
(図02_03_01)
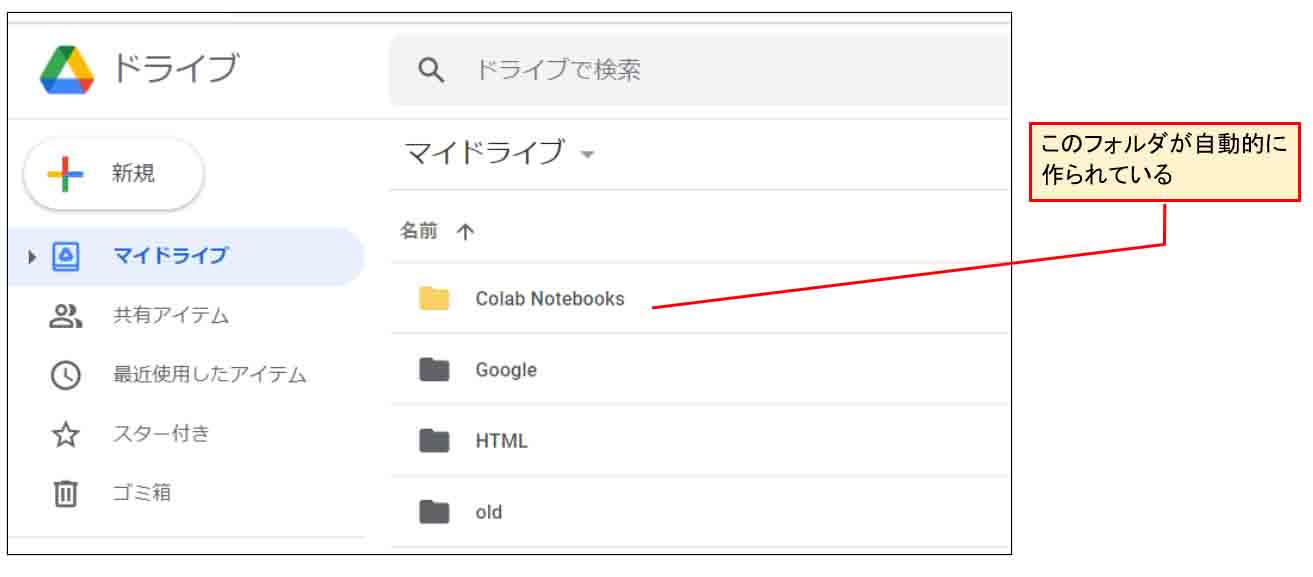
すると、Googleドライブの「マイドライブ」に、以下のように「Colab Notebooks」というフォルダが自動的に作成されていると思います。
(図02_03_02)
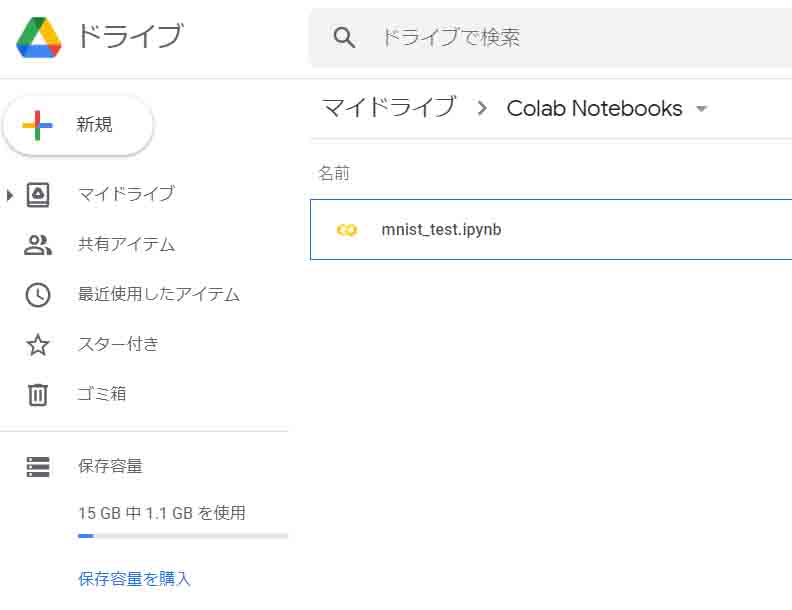
そのフォルダの中に先ほどの名前のノートブックが保存されていると思います。
(図02_03_03)
これで、大まかなセットアップ完了です。
2-04. Google Driveのフォルダから開けるか確認
因みに、Google Colaboratoryとブラウザを一旦閉じて、再度Google Chromeブラウザを起動し、Googleドライブの中の先ほどのファイルをダブルクリックして、開くと、以下のような画面になります。
(図02_04_01)
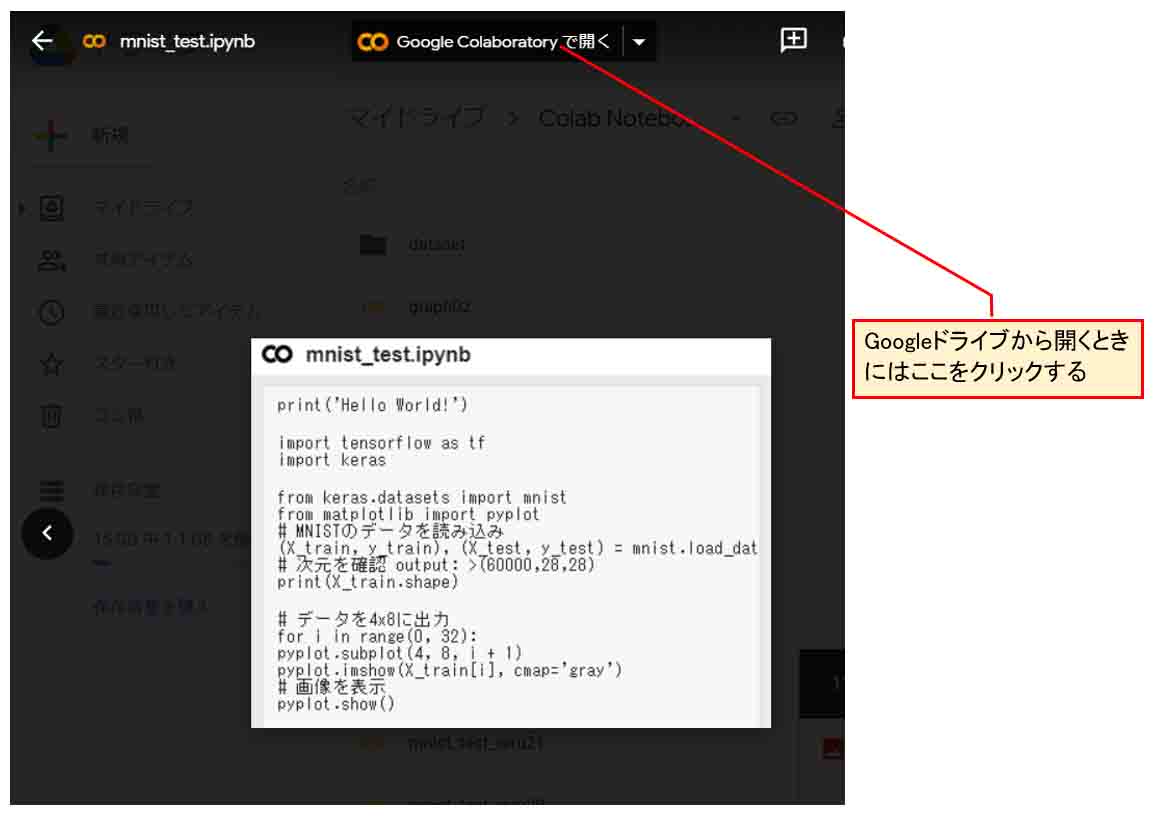
そしたら、上図のように、「Google Colaboratoryで開く」というところをクリックすれば、そのノートブックを開くことができます。
これでザッとしたGoogle Colaboratoryのセットアップ方法の説明でしたが、とても簡単でしたね。
2-05. ハードウェアアクセラレータをGPUにできる
先に述べましたが、Google Colaboratoryの最大のメリットとして、クラウド上のGPUやTPUを使えるということです。
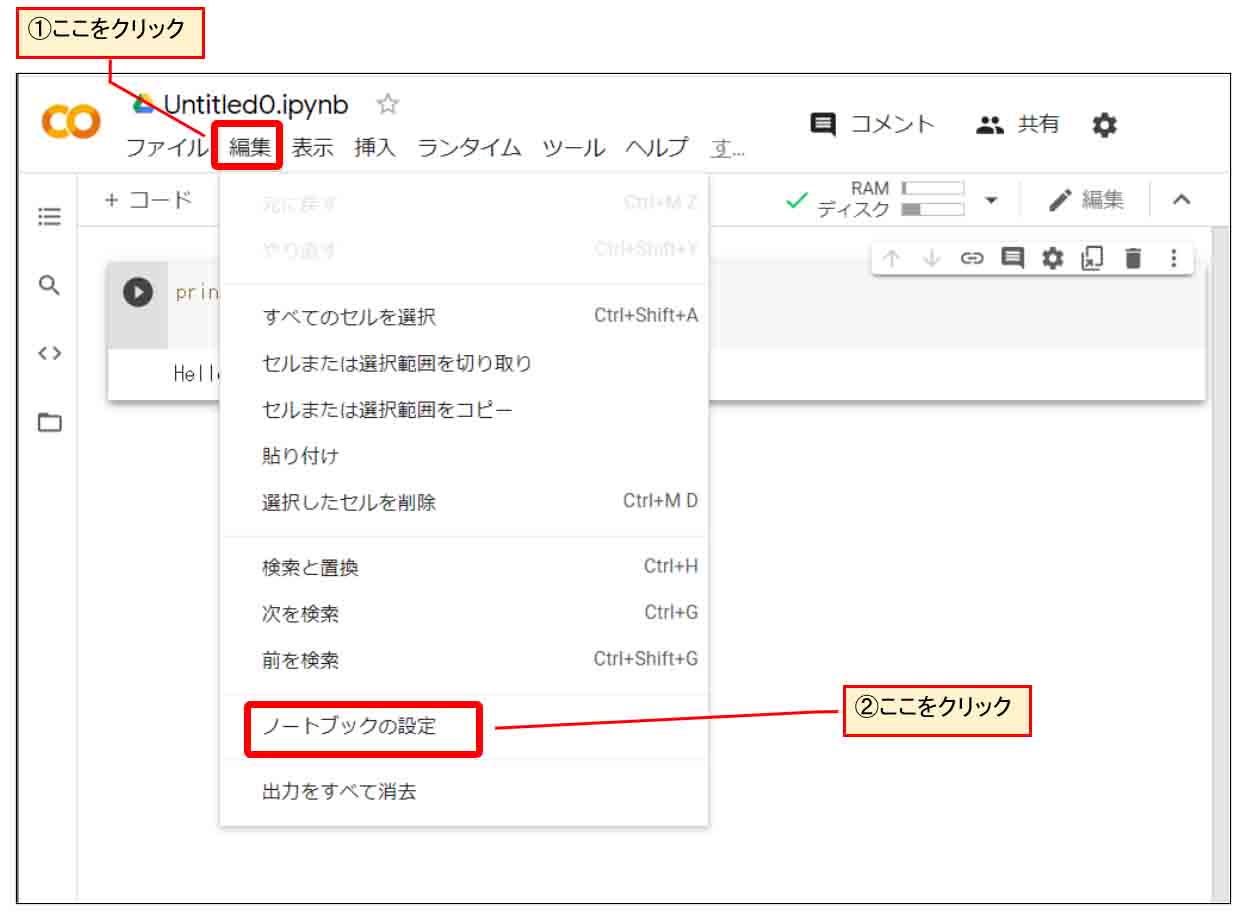
まず、下図のようにJupyter Notebook上の「編集」をクリックして、「ノートブックの設定」をクリックします。
(図02_05_01)
次に、下図のようにハードウェアアクセラレータでGPUを選択して「保存」をクリックすればクラウド上の高速GPUを無料で使うことができます。
(図02_05_02)
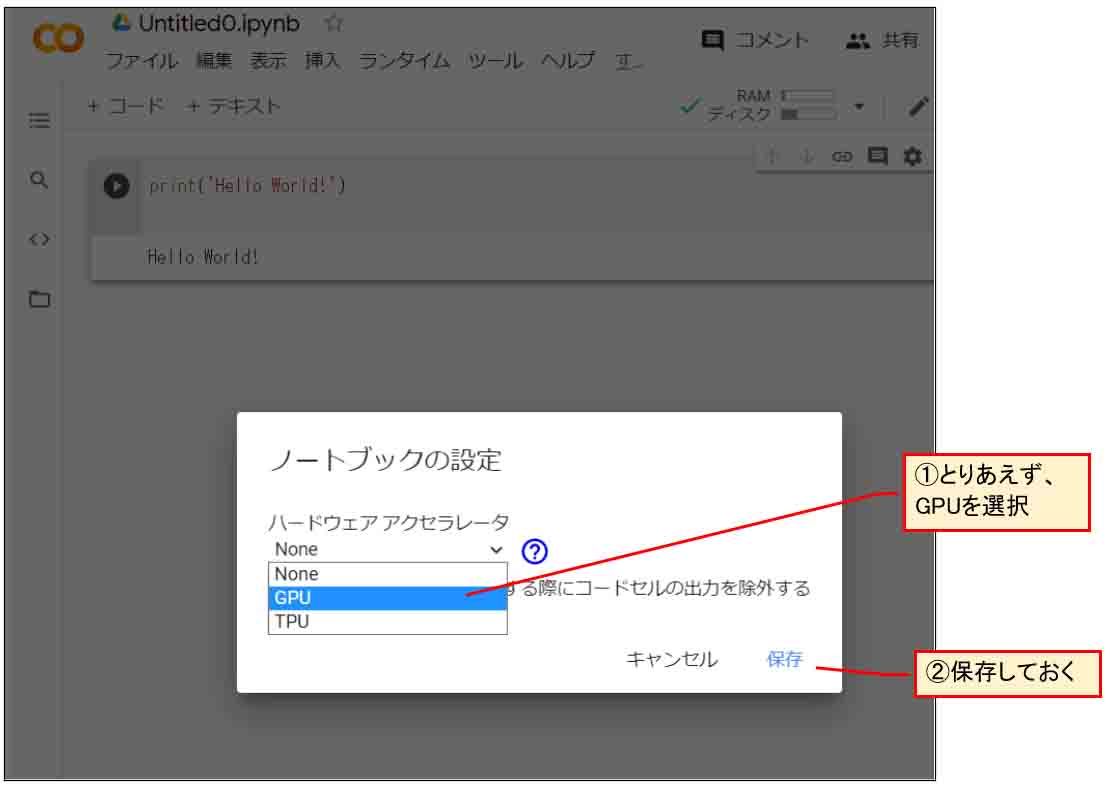
ただし、先ほど述べたように、連続12時間以上は使えないことと、その他に、断続的でも使用時間が長すぎると、翌日に使用制限がかかって丸1日使えなくなるので注意です。
3.Pythonを初めて使ってみた雑感
今回はじめてPythonでプログラミングしてみました。
今まで、ほとんどArduino IDEのC/C++くらいしか使ってこなかったので、Pythonがどんなものかというものは以前から興味はありました。
実際使ってみて大きなメリットを感じたのは、まず一つ目は変数の宣言が不要で、変数の型をあまり意識する必要が無いこと。
要するに、int とかcharとかいう型宣言不要ってことです。
そして、二つ目は、行列計算、つまり多次元配列の扱いがメチャメチャ簡単でやりやすいということでした。
これが一番大きいメリットかもしれません。
これは学者がデータ解析にPythonを使う理由がよくわかりましたね。
3-01. 変数の宣言が不要という手軽さ
例えば、以下のようにプログラミングして、その下に実行結果を表示させます。
x = 1 x1 = 0.1 s = "Hello World" array = [5, "テスト", 0.3] print(x) print(x1) print(s) print(array)
【実行結果】
1 0.1 Hello World [5, 'テスト', 0.3]
(図03_01_01)
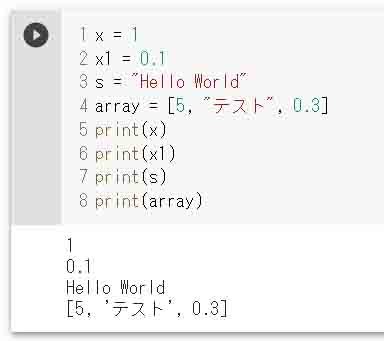
これ、ほんと手軽ですよね。
int x;
とか、C言語でお馴染みの型宣言が不要なんです。
そして、驚くべきは、配列にint型とchar型とfloat型が混在してもOKなんです。
こんなのC言語では有り得ないですね。
Pythonというのは、C言語などの面倒な部分を使い易くした高級言語なのでしょうか?
とにかく、最近のPython人気が分る気がしますね。
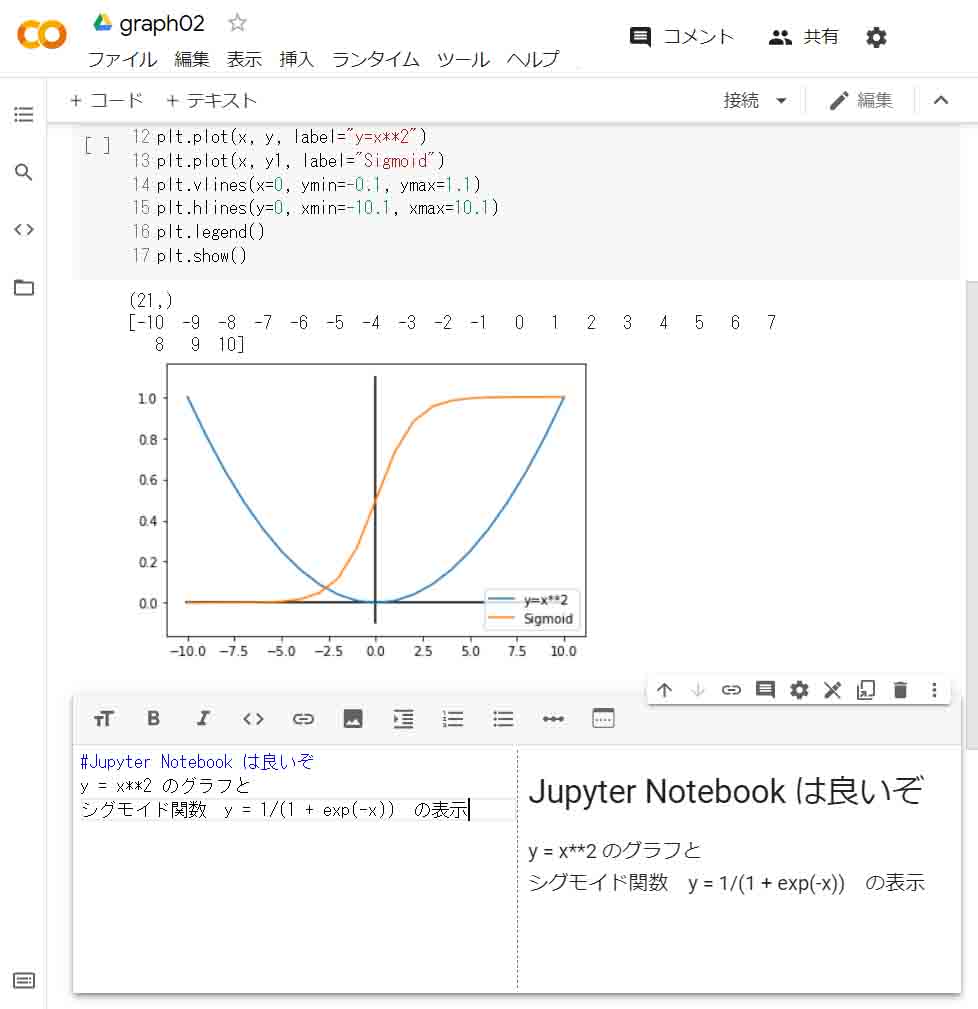
3-02. NumPyは行列の扱いがとっても便利だった
PythonにはC言語のように普通に配列を初期化したり、forループで多次元配列の値を代入したりすることができます。
ただ、NumPyというライブラリモジュールを使うと、多次元配列の行と列を入れ替えたり、要素数や次元数を変えたりすることが、めちゃめちゃ簡単にできるんです。
こんな感じです。
ary = [[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17]]
print(type(ary))
import numpy as np
nary = np.array(ary)
print(type(nary))
print(nary.shape)
nary1 = nary.reshape(3, 3, 2)
print(nary1)
print()
nary1 = nary.reshape(2, 9)
print(nary1)
print()
nary1 = np.transpose(nary, [1, 0])
print(nary1)
print()
【実行結果】
<class 'list'> <class 'numpy.ndarray'> (3, 6) [[[ 0 1] [ 2 3] [ 4 5]] [[ 6 7] [ 8 9] [10 11]] [[12 13] [14 15] [16 17]]] [[ 0 1 2 3 4 5 6 7 8] [ 9 10 11 12 13 14 15 16 17]] [[ 0 6 12] [ 1 7 13] [ 2 8 14] [ 3 9 15] [ 4 10 16] [ 5 11 17]]
(図03_02_01)

これは便利ですね。
配列の次元を入れ替えたり、列と行を入れ替えたり、簡単で自在です。
C言語でも、自作の関数を組んでライブラリ化すればできると思いますが、こういうものが標準で装備されているというのは、ディープラーニングにはありがたいですね。
また、配列の各要素の一括演算も、NumPy配列に変換すれば、とっても簡単です。
こんな感じです。
array1 =[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]] import numpy as np array1 = np.array(array1) array1 = array1 * 100 print(array1)
【実行結果】
[[ 100 200 300 400 500] [ 600 700 800 900 1000]]
(図03_02_02)

これは直感的な計算で良い感じですね。
C言語だと、こういう場合、ポインタのアドレス計算になってしまいますが、PythonのNumPyの場合は直感的な記法で全要素に100を乗算できてしまいます。
C言語に慣れていない学生や研究者ならば、こっちの方が断然理解し易いと思います。数学の行列計算みたいに扱えているのではないでしょうか。
実は、よくよく調べてみると、PythonのこういうライブラリはC言語やFortranで作られているらしいです。
Python自身はインタープリタ型なので、forループを組んでも計算速度が遅いのですが、このNumPyを使えば高速で処理できます。
これがC言語で出来ていると思うと納得しますね。
そんなこんなで、この行列の扱いが簡単なNumPyがあればこそ、Pythonがディープラーニングに多く使われるということは納得がいきます。
そして、先に紹介したJupyter Notebookの便利さも相まって、学者やデータサイエンスによく使われる意味もわかりますね。
3-03. Pythonの配列とNumPy配列の概念に戸惑った
Pythonでここまで簡単に多次元配列が扱えるとなると、逆に混乱する時があります。
意外と自分の頭の中にある概念と異なっていたんです。
例えば、Pythonで2次元配列を作って初期化して、NumPy配列に変換してshapeを表示してみるという単純な以下のようなコードを書くとします。
# 2次元配列初期化
ary = [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]]
# NumPyモジュールをインポート
import numpy as np
# リスト型配列をNumPy配列に変換
nary = np.array(ary)
print(nary.shape)
print(nary)
これを実行すると以下のように表示されます。
(2, 10) [[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19]]
このshape表示の(2, 10)という表示に最初はすごく悩まされました。
これは、2行10列という意味なのですが、個人的な感覚では、10が先に表示されて欲しいと思っていました。
なぜかというと、プログラミングが複雑化してくると、混乱してくるんです。
プログラミングで多次元配列にデータを入力する時は、まず1行目のデータを10個入力してから、2行目のデータ10個を入力しますよね。
Excelで表を作る時も、まず1行目を入力してから2行目を入力します。
データを出力する時もまず1行目のデータ10個を出力させてから2行目のデータ10個を出力させます。
ですから、私の頭の中では、(10, 2)という感覚なんです。
でも、このshape表示では私の感覚とは逆の表記(2, 10)となっています。
実は、よくよく考えてみると、C言語でプログラミングする時の2次元配列宣言を想像すれば、今まで親しんできた手法なので、混乱を避けることができました。
C言語の場合、
int ary[2][10] ;
と最初に定義しますよね。
この場合は、2が先で10が後です。
このようにイメージすれば個人的に理解し易いと思いました。
まぁ、これはあくまで個人的感覚なので、多くの人は特に混乱しないかと思われますけどね。
3-04. Pythonのforループの実行が字下げ(インデント)だった
Pythonのforループを使ってみたら、少々驚きでした。
例として、2行5列の二次元配列を用意して、各要素にそれぞれ100を掛ける二重forループを作ってみました。
以下の感じです。
array1 =[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]]
for j in range(2):
for i in range(5):
array1[j][i] = array1[j][i] * 100
print('.', end='') #改行しない
print('\n') #改行する
print(array1)
【実行結果】
..... ..... [[100, 200, 300, 400, 500], [600, 700, 800, 900, 1000]]
(図03_04_01)

このforループがArduinoなどのC言語と大きく異なるのは、{波括弧}が無いことです。
波括弧が無いということは、forループがどの行まで適用になるかが分かなくなると思いますよね。
実はPythonのforループは、インデント(字下げ)しているところまでがforループの適用行だそうです。
へぇ~!
って言う感じでちょっと驚きました。
インデントだけでforループをくくれるのは画期的だなと思いました。
さすが、最近の人気高級言語だと思いました。
インデントによるものはforループだけでなく、if文も同様です。
ということは、C言語に慣れた人は、Pythonで安易にインデントすると、思わぬトラブルに合いそうですね。
これは要注意です。
以上、Pythonを使ってみた簡単な雑感でした。
4.チュートリアルを参考にしてMNISTデータセットでCNNを組んでディープラーニングしてみる
では、いきなりディープラーニングをテストしてみたいと思います。
Google Colaboratoryでディープラーニングを始めるには、先ほど述べたように、Googleが開発したTensorFlowを使うわけですが、TensorFlowは扱いが難しいのでTensorFlowを使いやすくしたKerasを使うことになります。
まずは、TensorFlowの初心者のためのチュートリアルを参考にしながら進めていきます。
以下のリンクにあります。
https://www.tensorflow.org/tutorials/images/cnn?hl=ja
下図のように、テキストセルにはマークダウン記法で題名を入力し、コードにはプログラムソースコードをコピペして、それぞれのセルごとに実行させていきます。
(図04_01)
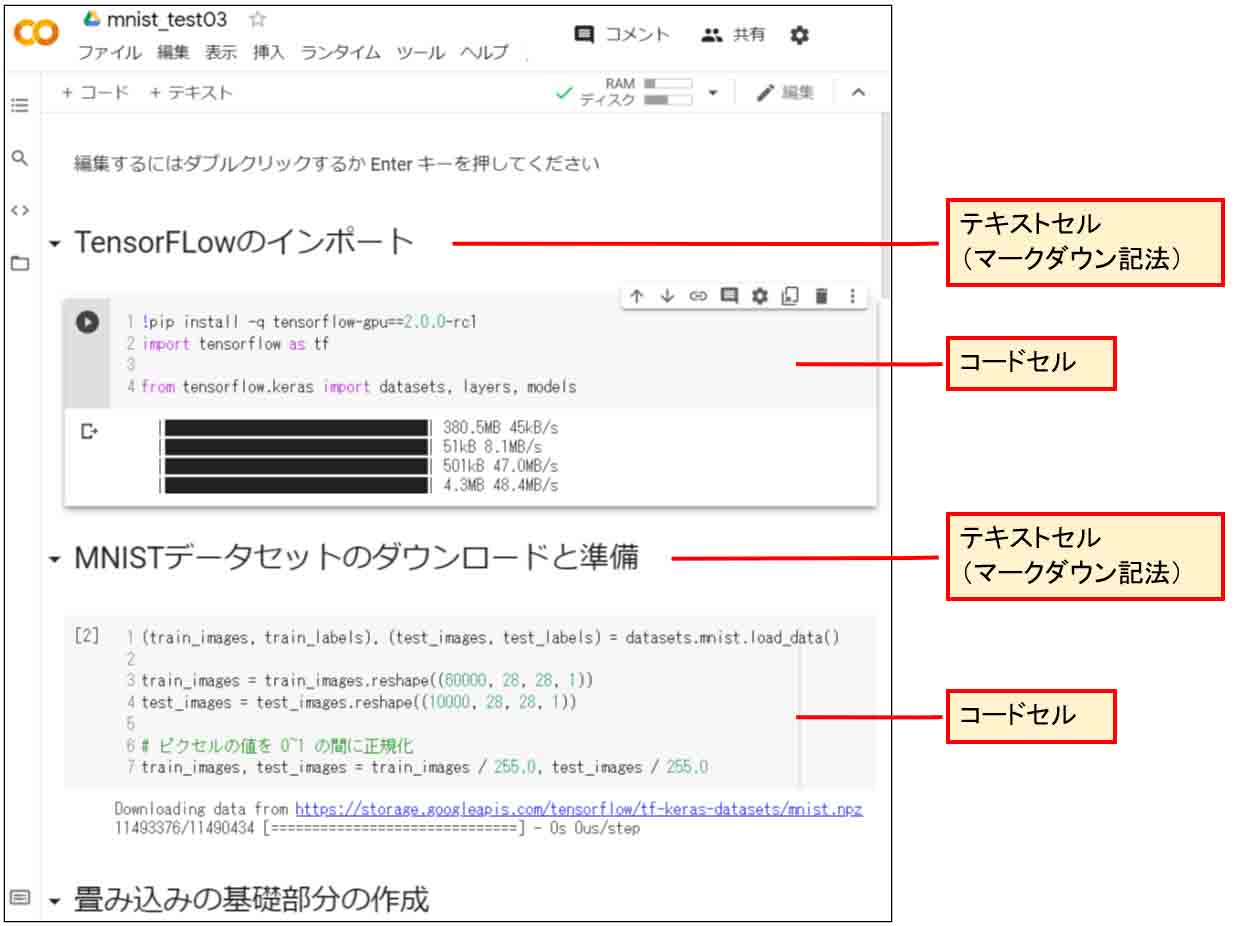
このように、Jupyter Notebookを使うと、コードを分割して間にテキストが入っても引数が引き継がれるというのは面白いですね。
そして、先ほどのチュートリアルからコピペして、下図のように最後までできたら、そのセルを実行させます。
すると、下図のようになりました。
(図04_02)
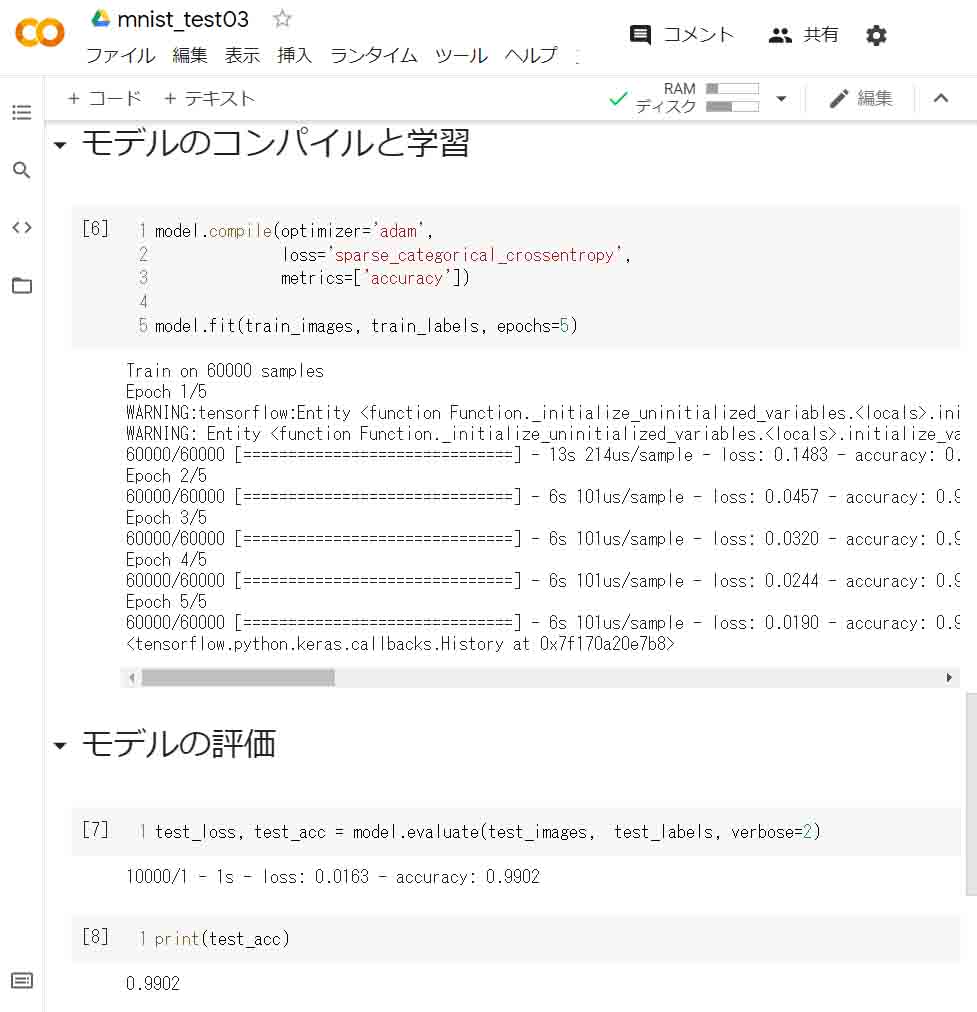
このように、たった5回だけ学習させただけなのに、99%以上の正解率を叩き出したのが分かると思います。
まぁ、これだけニューロン(ノードあるいはチャンネル)が多いと、重みフィルタの個数もとんでもなく多いので、正解率は上がるわけですね。
ただ、このデータ量だと、Arduino系組み込みマイコンには無理かもしれませんが…。
とりあえずはこれで手書き数字MNISTの手始めはOKです。
因みに、個々のセルごとに実行させなくても、後でまとめて全てのセルを実行させたい場合は、下図のように、「ランタイム」をクリックして、「すべてのセルを実行」をクリックすると一括して実行できます。
(図04_03)
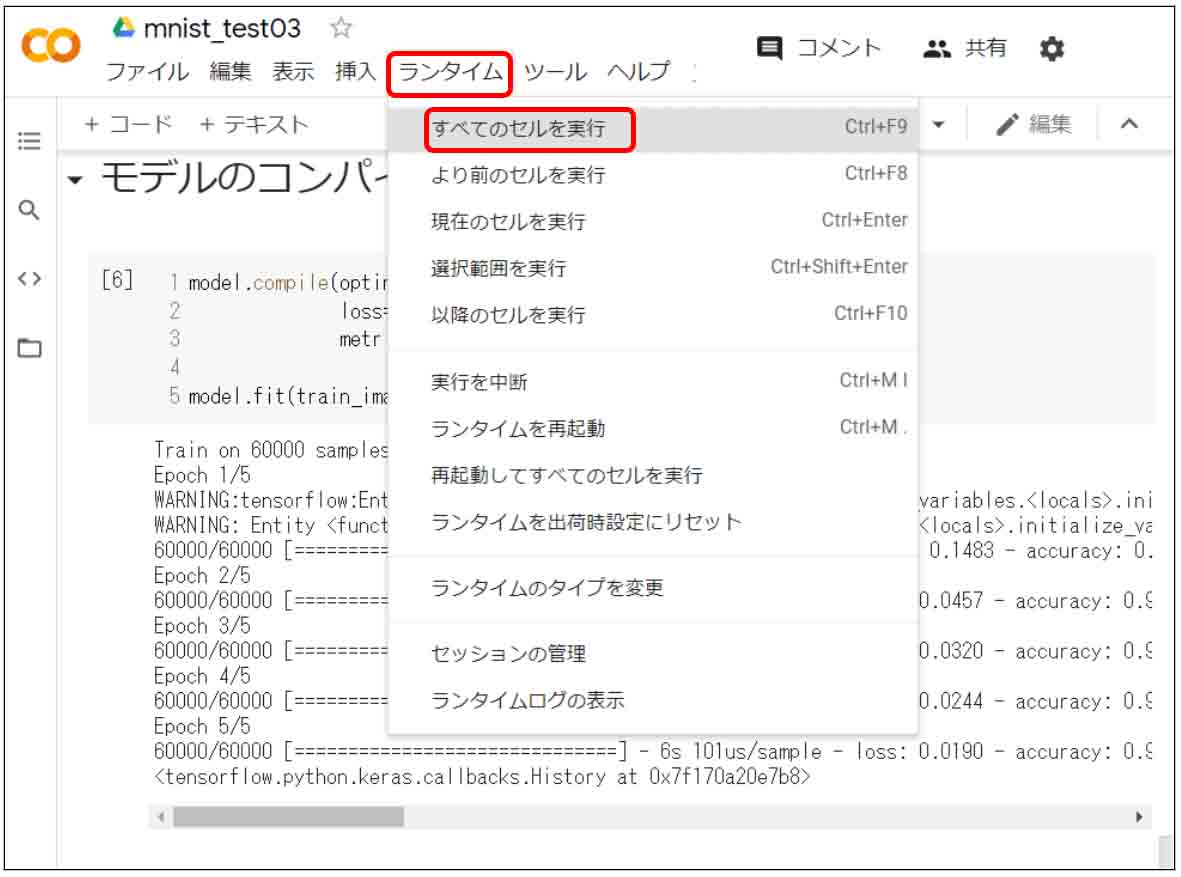
以上が手始めのチュートリアルでした。
次回に上げる記事で、自作の畳み込みニューラルネットワークをKerasで作成してみて、機械学習させる実験をしたいと思います。
その時にKerasのレイヤーパラメータの詳しい設定方法について述べてみたいと思います。
5.まとめ
ざっとGoogle Colaboratoryを使った感じでは、個人的にはとても新鮮でしたね。
Jupyter Notebookのセルごとの実行で、変数が引き継がれるっていうところは面白かったです。
また、PythonのNumPyライブラリの行列計算の手軽さには恐れ入りました。
それに、いろいろ制限はありますが、クラウドのGPUを無料で使えるのは嬉しいですね。
そんなこんなで、少々欠点はありますが、ディープラーニングで多くの人がGoogle Colaboratoryを使う理由が分かった気がします。
実は、Kerasを使ってディープラーニングして、この他にもいろいろと発見がありました。
記事がとても長くなったので、今回はGoogle Colaboratoryの雑感だけを紹介してみました。
近々、Kerasのパラメータ設定等を具体的に紹介してみたいと思います。
ではまた。
Amazon.co.jp 当ブログのおすすめ












コメント