こんばんは。
ゼロからディープラーニングを勉強してみる第4弾として、今回はいよいよディープラーニング専用ツールを使ってみます。
そのツールはSONY製のNeural Network Console というものです。
これを使うようになった切っ掛けは、YouTube動画のチュートリアルを見て興味を持ったわけです。
実際に使ってみると、凄く使いやすくて、直感的に操作できるので、ビギナーにはとっても良いツールだと思いました。
個人的には超おススメです。
ただ、クラウド版で使う場合は無料枠の計算時間が10時間しかないため、Windows版アプリを使って試用した方が良いですよ。
残念ながら2020年11月時点でMac版はありません。
その他のツールにコマンドラインで使う無料の物がありますが、私はまだディープラーニング初心者なので、使い方が良くわからず断念しました。
その点、このNeural Network Consoleはとても使い易かったのです。
ただ、いくら使いやすいと言っても初心者には難しいと思います。
PDFマニュアルや、YouTube動画チュートリアルを見ても、意味不明なことが多々ありました。
ビギナー向けとはいえ、ある程度専門用語を理解していないとまともに使えません。
私の場合は、以下の過去の記事でExcelを使ってある程度仕組みを理解していたので、導入はすんなり行きました。
●ゼロからディープラーニングを勉強してみる ~Excel編その1。自己流計算式の限界とバイアス、シグモイド関数について~
●ゼロからディープラーニングを勉強してみる ~Excel編その2。ニューラルネットワークと学習~
●ゼロからディープラーニングを勉強してみる ~Excel編その3。畳み込みニューラルネットワーク~
ただ、それでも良くわからない用語の解釈には、オライリー・ジャパンの以下の書籍も参考にしました。
【題名】
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
【著者】
斎藤 康毅














































































































最初はこの参考書が全く理解できなかったんですが、今回も含めこの4回シリーズの記事でようやく少しは理解できるようになってきましたよ。
ところで、Excelだけでディープラーニングしていた時は、たかが1000件程度の学習に30時間も費やしたことがあって、しかもCPUフル稼働でパソコンが占有されてしまったので、他の作業が全然できませんでしたが、Neural Network Consoleの場合はGPU学習することができるので、超便利です。
ディープラーニング熟練者ならば当たり前のことですが、私にはとても新鮮でした。
何しろ、学習しながら他のパソコン作業が難無くできるんですよ!(当然ながらある程度メモリを積んでいる必要があります。)
私はゲームを殆どやらないので、GPU搭載パソコンを持っていながらあまり恩恵を受けていませんでした。
でも、今回はGPUの素晴らしさがよーく分かりましたよ!
ということで、SONYのNeural Network Consoleの使い方を自分流の視点で説明してみたいと思います。
何しろド素人ですから、間違えていたらスミマセン。
何かお気づきの点がありましたら、コメント投稿等でご連絡いただけると助かります。
- Neural Network Console (Windowsダウンロード版) のインストール
- 学習エンジンをGPUに設定する
- 手書き数字MNISTデータセットのダウンロード
- ニューラルネットワークを組んでみる
- 学習させる(Training)
- 評価する(Evaluation)
- Max Epoch を変えてみる
- まとめ
【目次】
Neural Network Console には、クラウド版とWindowsアプリ版がある
Neural Network Console には、クラウド版とWindowsアプリ版がある
以下、2020年10月時点の情報で書きます。
SONY の Neural Network Console のサイトを開くと、クラウド版の紹介にまず目が行くと思います。
これだけ見ると、クラウド版の無料枠は10時間だけで、あとは有料となっています。
そして、そのサイトの一番下の方を見ると、目立たないですが、Windows版というリンクがあり、そこでアプリをダウンロードすると、無料で時間無制限に使うことができます。ただし、自分のパソコンのCPUとGPUの計算に限定されます。
パソコンにGPUを積んでなければ、学習計算にCPUを占有されてしまいますが、MNISTデータセットのディープラーニング実験程度でしたら、Excelで計算するよりは遥かに良いと思います。
入門用には最適だと思いました。
残念ながら2020年10月時点ではMac版はありませんでした。
ディープラーニングに熟練してきて、もっと多量で複雑な映像を扱うようになって、自分のパソコン環境では難しくなってきた場合に、クラウド版を使うと良いと思います。
1.Neural Network Console (Windowsダウンロード版)のインストール
まず、以下のサイトを開きます。
Neural Network ConsoleWindowsアプリ
すると、下図の様に Neural Network Console アプリをダウンロードするところがありますので、そこをクリックしてダウンロードします。
(図01-01)
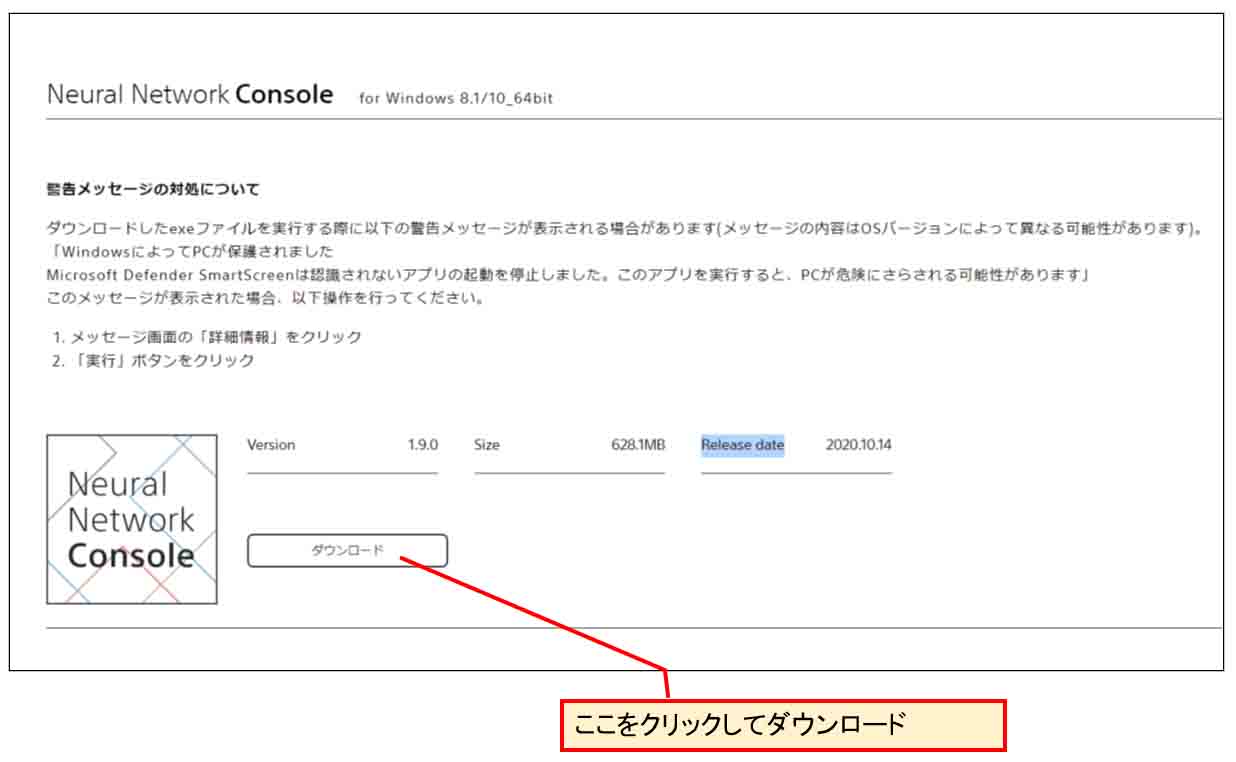
すると、下図の様に neural_network_console_○○○.exe というファイルがダウンロードされます。
(図01-02)
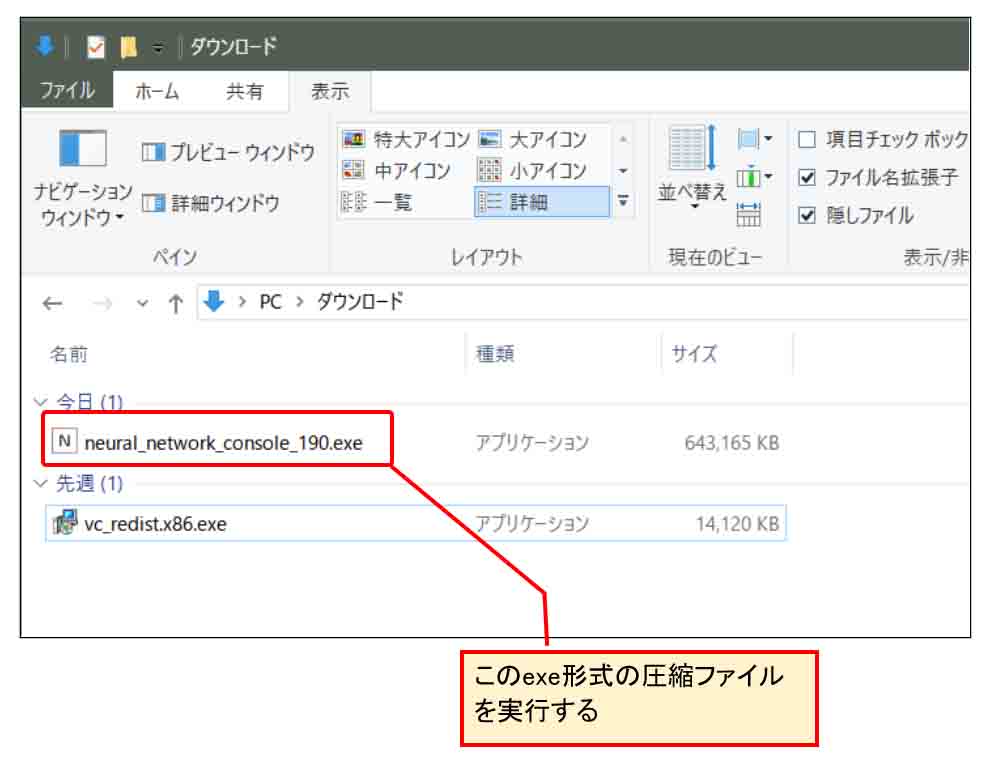
これは、exe形式の圧縮ファイルになっています。
これを実行すると、解凍アプリが起動すると思います。
私の場合は7-Zipをインストールしていたので以下のような画面が出ました。
(図01-03)
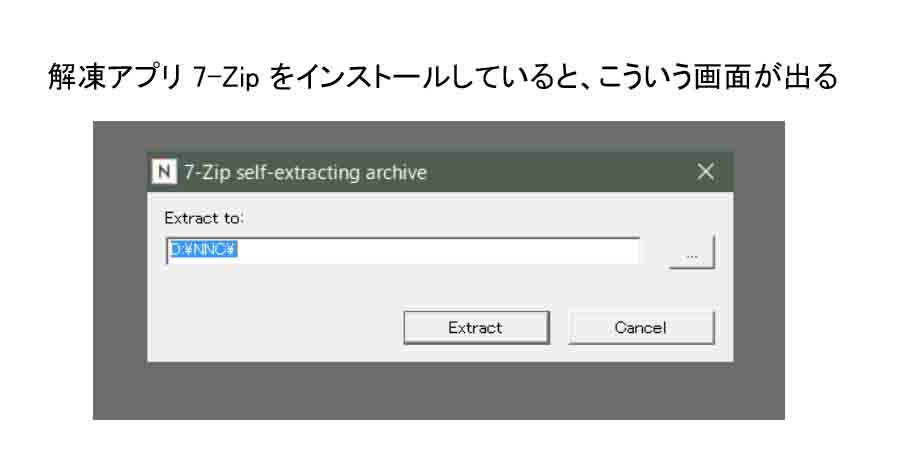
そこで、解凍先のドライブとフォルダを入力して、「Extract」をクリックして、解凍開始します。
私の場合はDドライブに解凍しました。
すると、下図の様に解凍中の画面になります。
(図01-04)
解凍が終ると、指定したフォルダに下図の様なファイル群ができていると思います。
インストーラファイルは無いです。
neural_network_console.exe がアプリそのもので、シンプルですね。
では、それを実行します。
(図01-05)
すると、下図の様なメッセージウィンドウが開きますが、この注意文については後で説明しますので、ここではとりあえず「OK」をクリックします。
(図01-06)
すると、インターネットのクラウド環境にアクセスして、アカウントのログイン状態を調べるので、下図の様な画面になってしばらく待ちます。
(図01-07)
その後、自動的にブラウザが起動し、SONYのNeural Network Consoleのアカウントサインイン画面が現れます。
(図01-08)
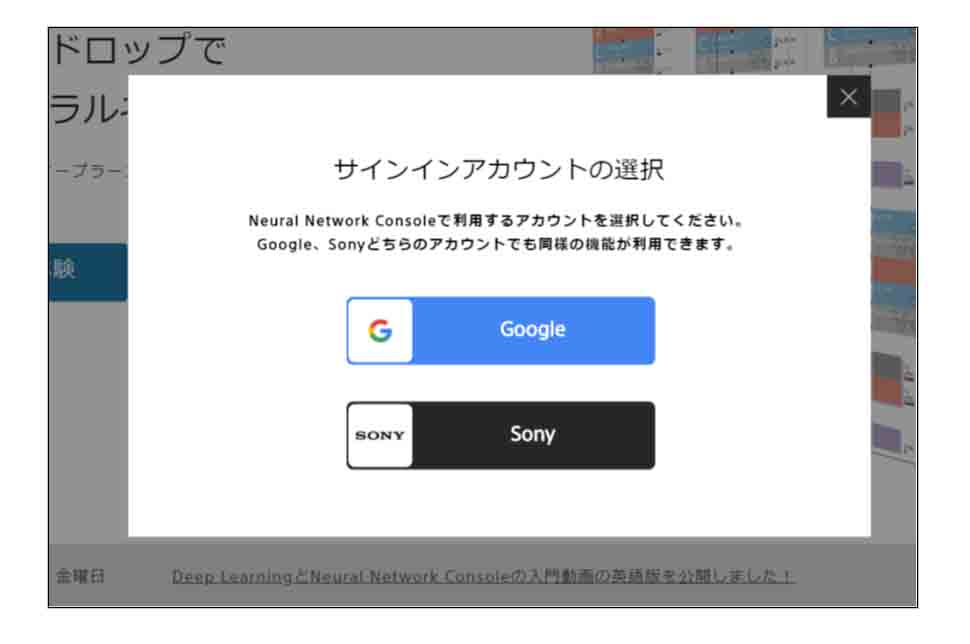
Googleアカウントを持っていればそれでサインインできますし、Sonyアカウントを作っても良いと思います。
サインインが完了すると、以下のような画面になります。
(図01-09)

今度は、(図01-06)で表示されたメッセージが気になったので、先ほど解凍したフォルダの中のPDF形式の日本語マニュアルを開きます。
(図01-10)
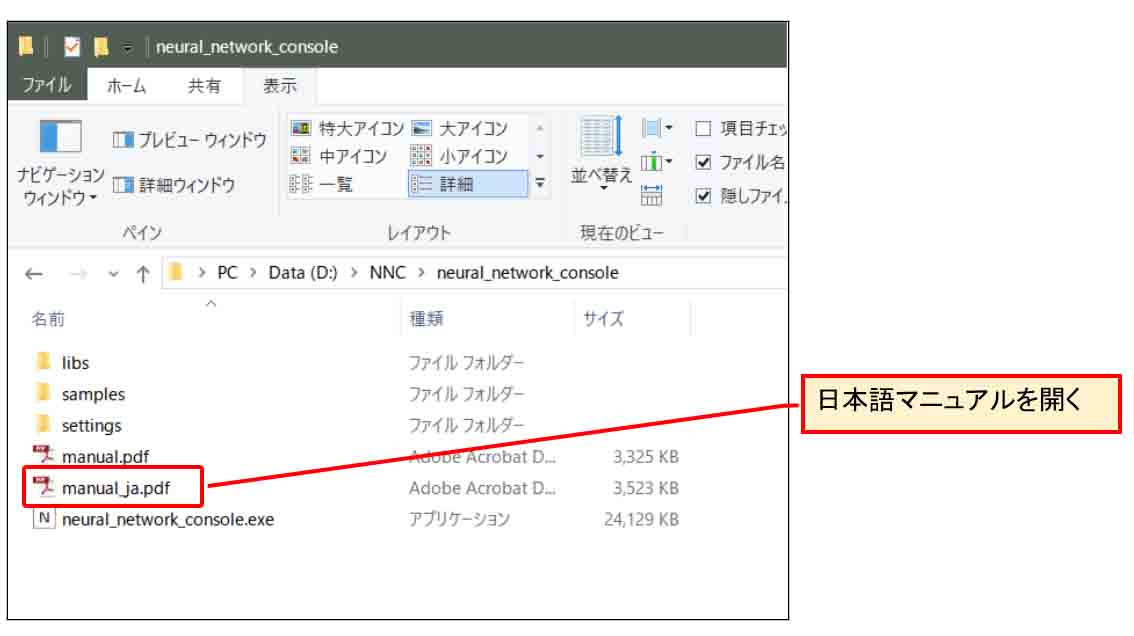
すると、セットアップのところを読むと、
「Visual Studio 2015 Visual C++ の再頒布パッケージがインストールされていない場合は、インストールせよ」
と書いてあります。
(図01-11)
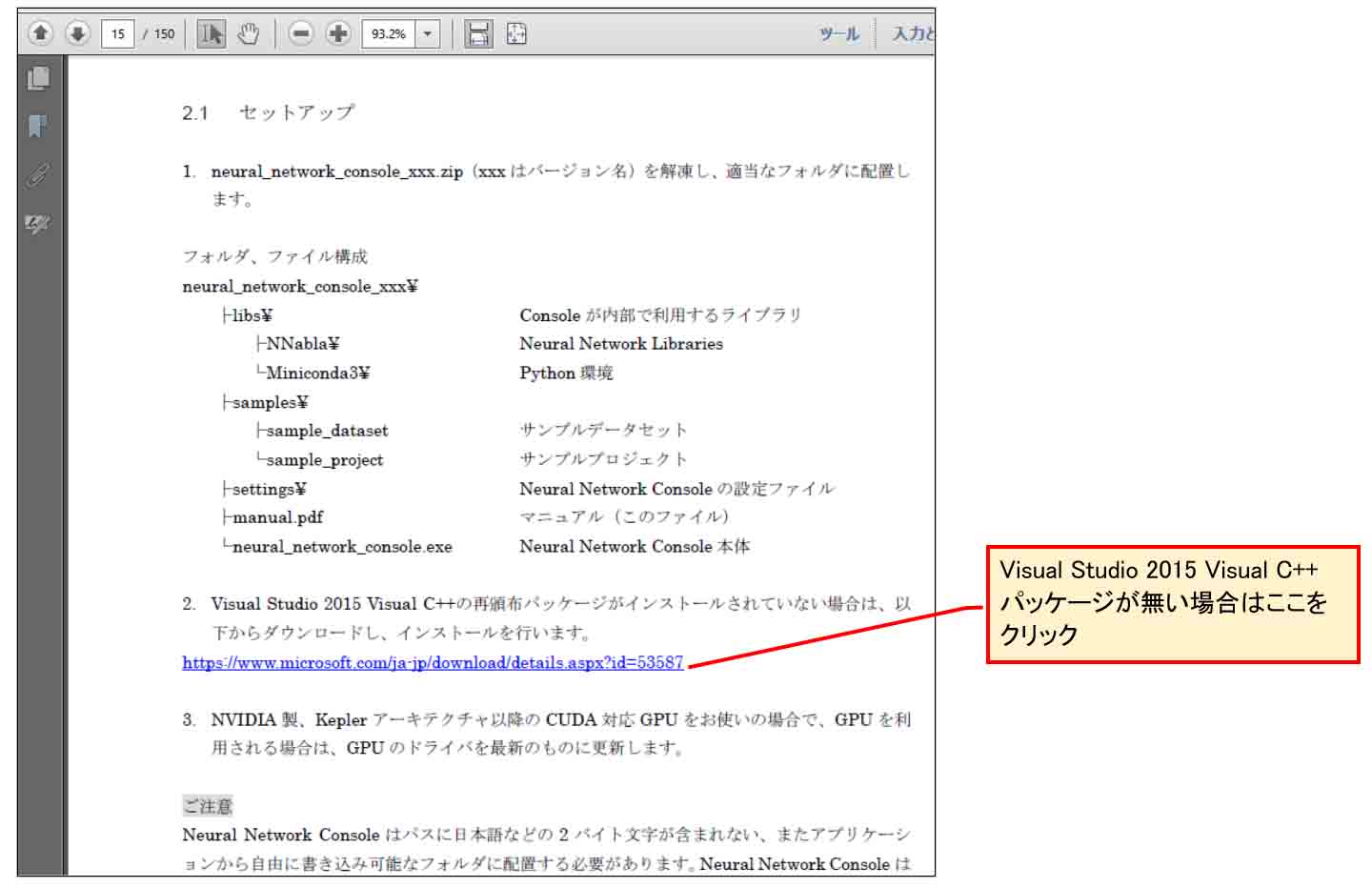
そこのリンクをクリックしてブラウザを開くと、下図の様な画面になるので、日本語バージョンのダウンロードをクリックします。
(図01-12)
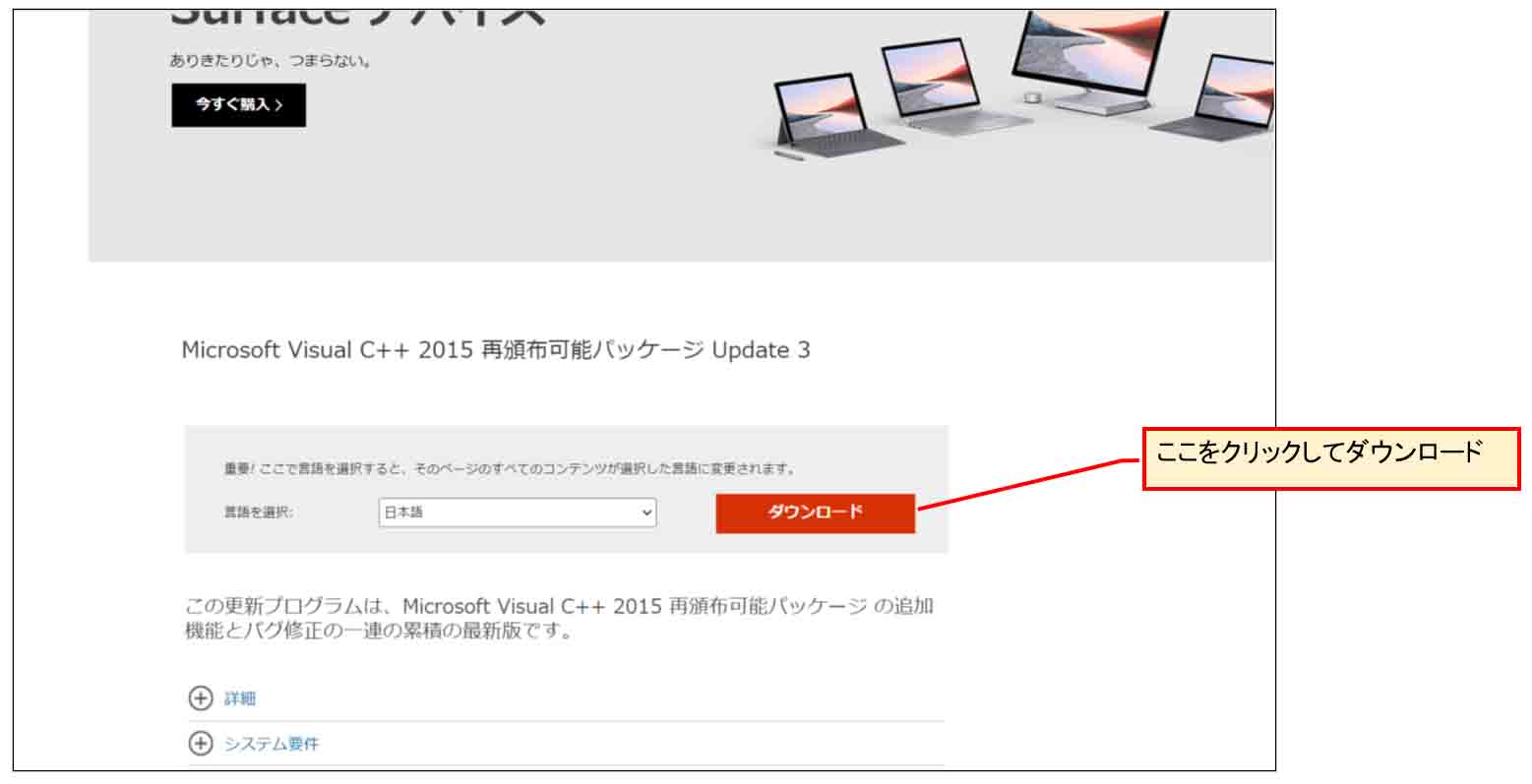
すると、下図の様な画面になるので、自分のPC環境に合ったプログラムにチェックを入れます。
私の場合は、64bitパソコンなので、vc_redist.x64.exe を選択しました。
32bitパソコンならばvc_redist.x86.exe です。
(図01-13)
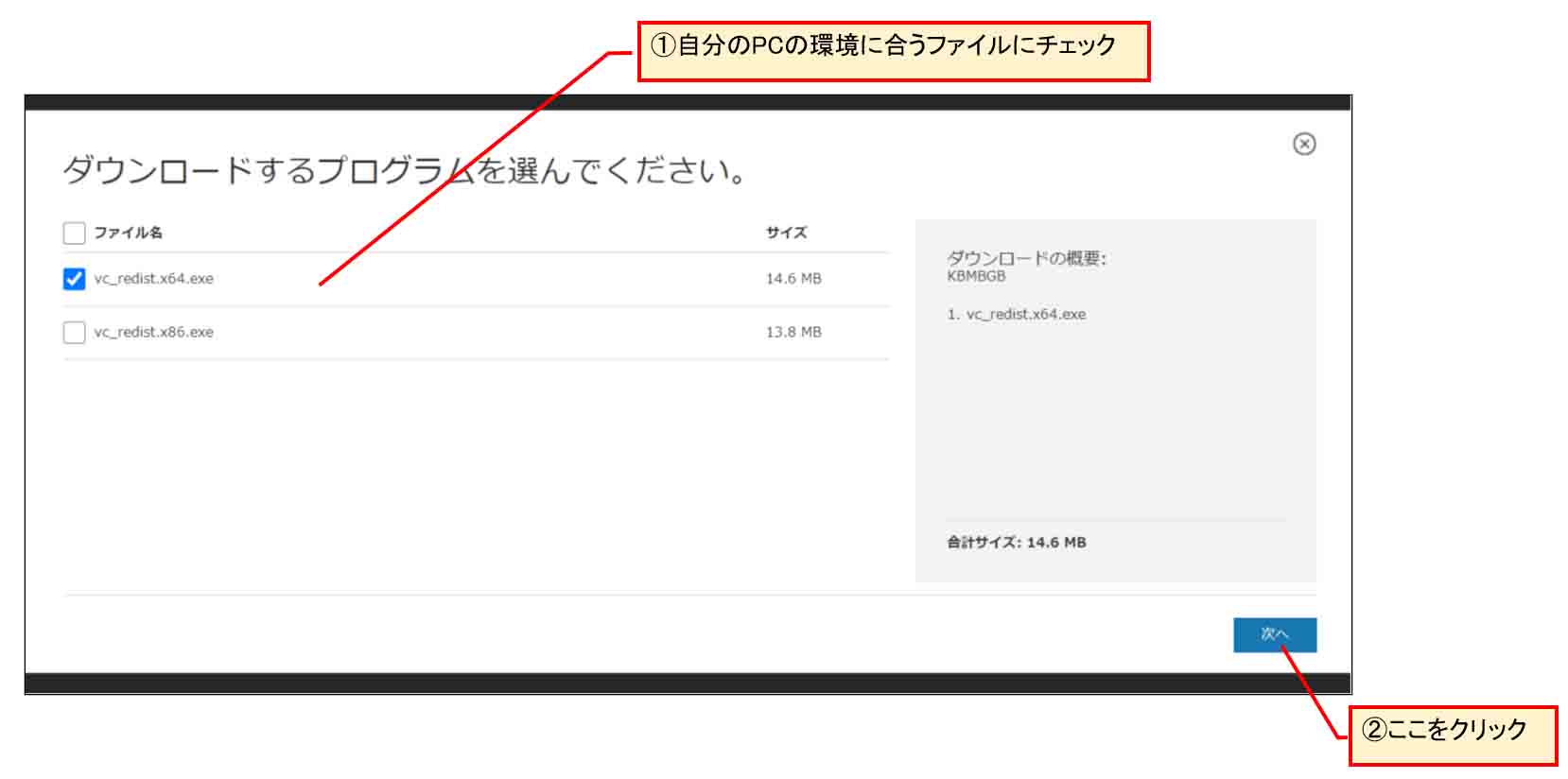
「次へ」をクリックするとダウンロード始めます。
すると、以下のようにダウンロードフォルダにダウンロードされますので、そのファイルを実行します。
(図01-14)
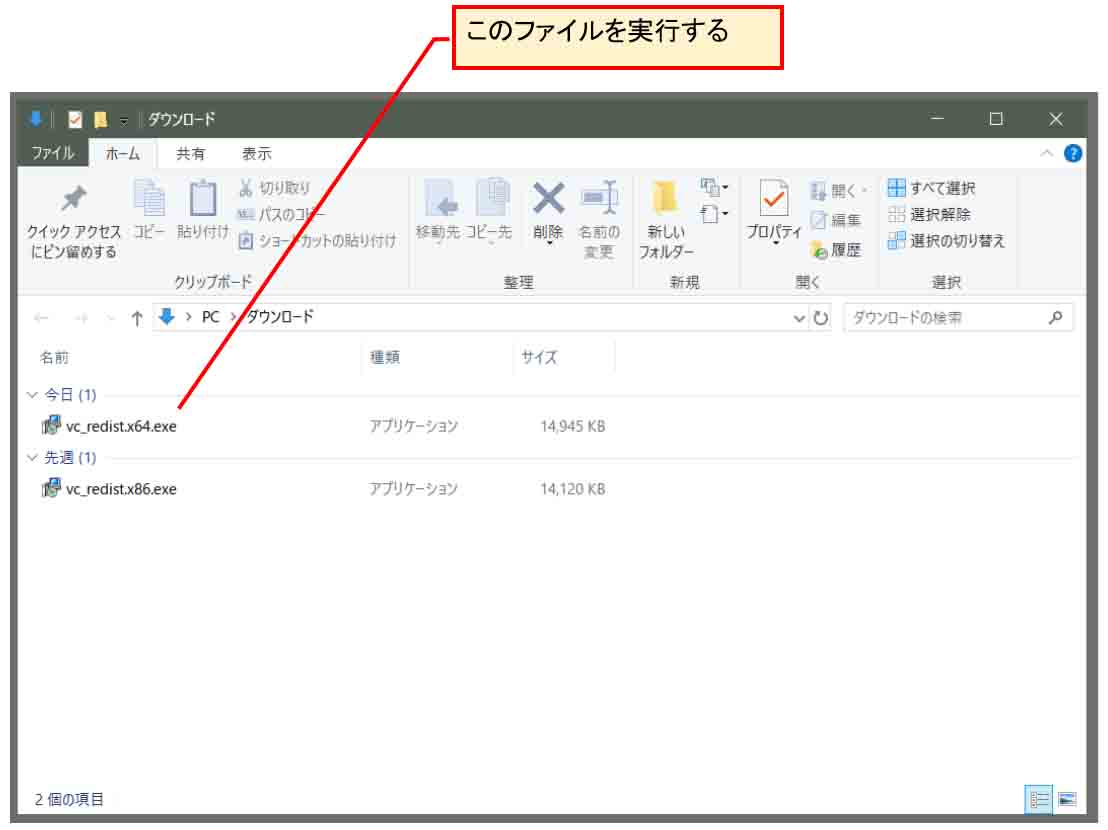
すると、下図の様な画面になるので、同意するにチェックして、インストールをクリックします。
(図01-15)

その他、先ほどの日本語マニュアルに書いてあるように、NVIDIA製、Keplerアーキテクチャ以降のCUDA対応GPUを使っていたら、GPUのドライバを最新のものに更新しておくと良いと思います。
インストールが終ったら、Neural Network Console を起動します。
すると、以下の画面になるので、「I Agree」にチェックを入れて、「Apply」をクリックします。
(図01-16)
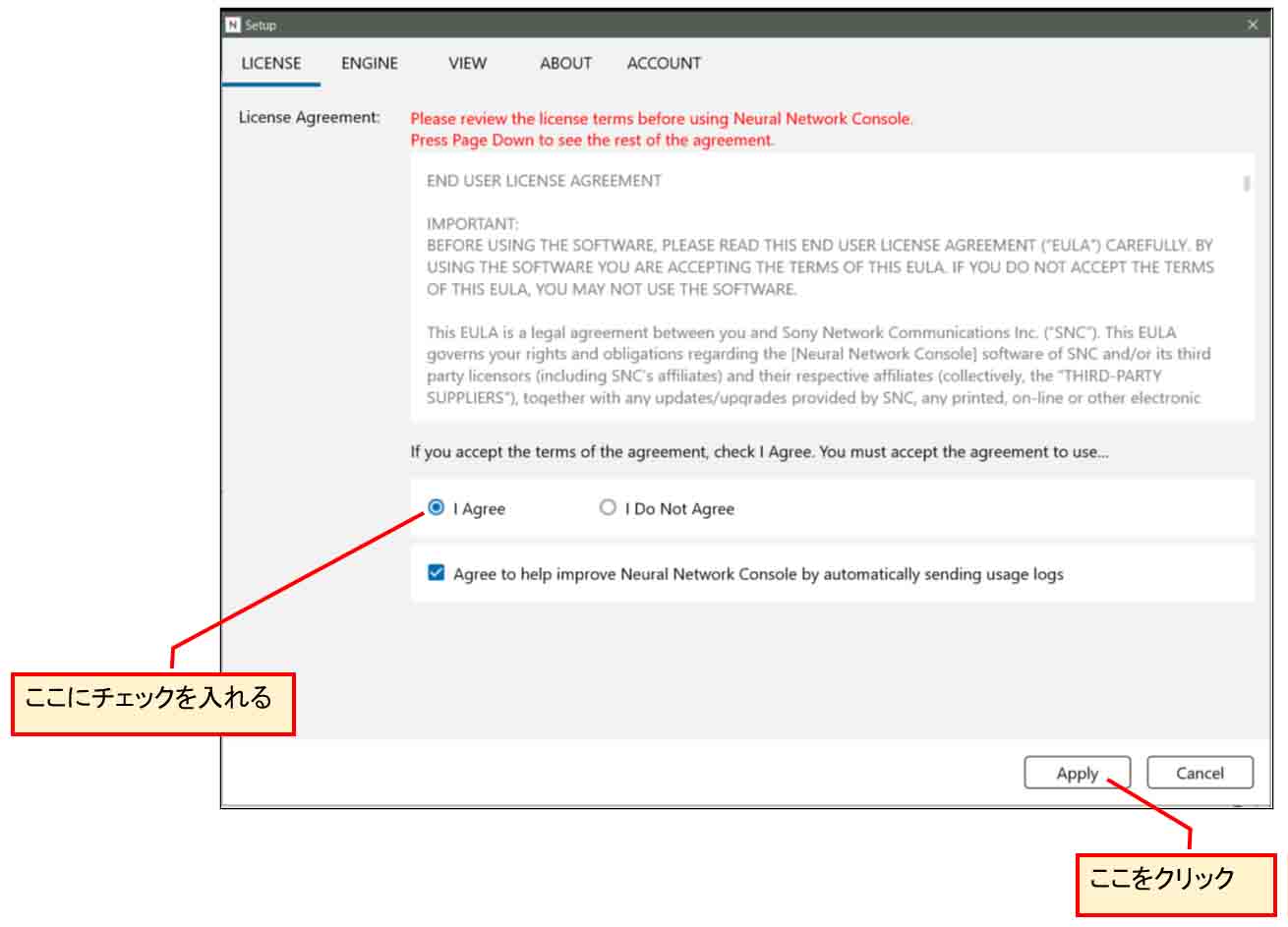
すると、以下のような画面になり、プラグイン等がアップデートされて、Neural Network Consoleが使えるようになります。
(図01-17)
以上で、Windows用アプリ、Neural Network Console のインストール完了です。
2.学習エンジンをGPUに設定する
では、今度はNewral Network Consoleの学習計算をパソコンのCPUではなく、GPUで計算させる設定にします。
前提として、パソコンにGPUが積まれていなければなりません。
GPUが積まれていなければ、CPUのみの計算になるので、ここは読み飛ばしてください。
なぜCPUではなく、GPUにするかというと、CPUを使ってしまうと、深層学習をやっている間、CPUを占有されてしまって他の処理が遅くなってしまう為、学習計算はGPUに任せた方が圧倒的に良いと思います。
私の場合は、GPUを積んでいてもゲームやコンピュータグラフィックスをやらないので宝の持ち腐れでしたが、今回ようやく稼働することができました。
まず、下図の様に、右上端のところのアイコンをクリックして、「Setup」を開きます。
(図02-01)
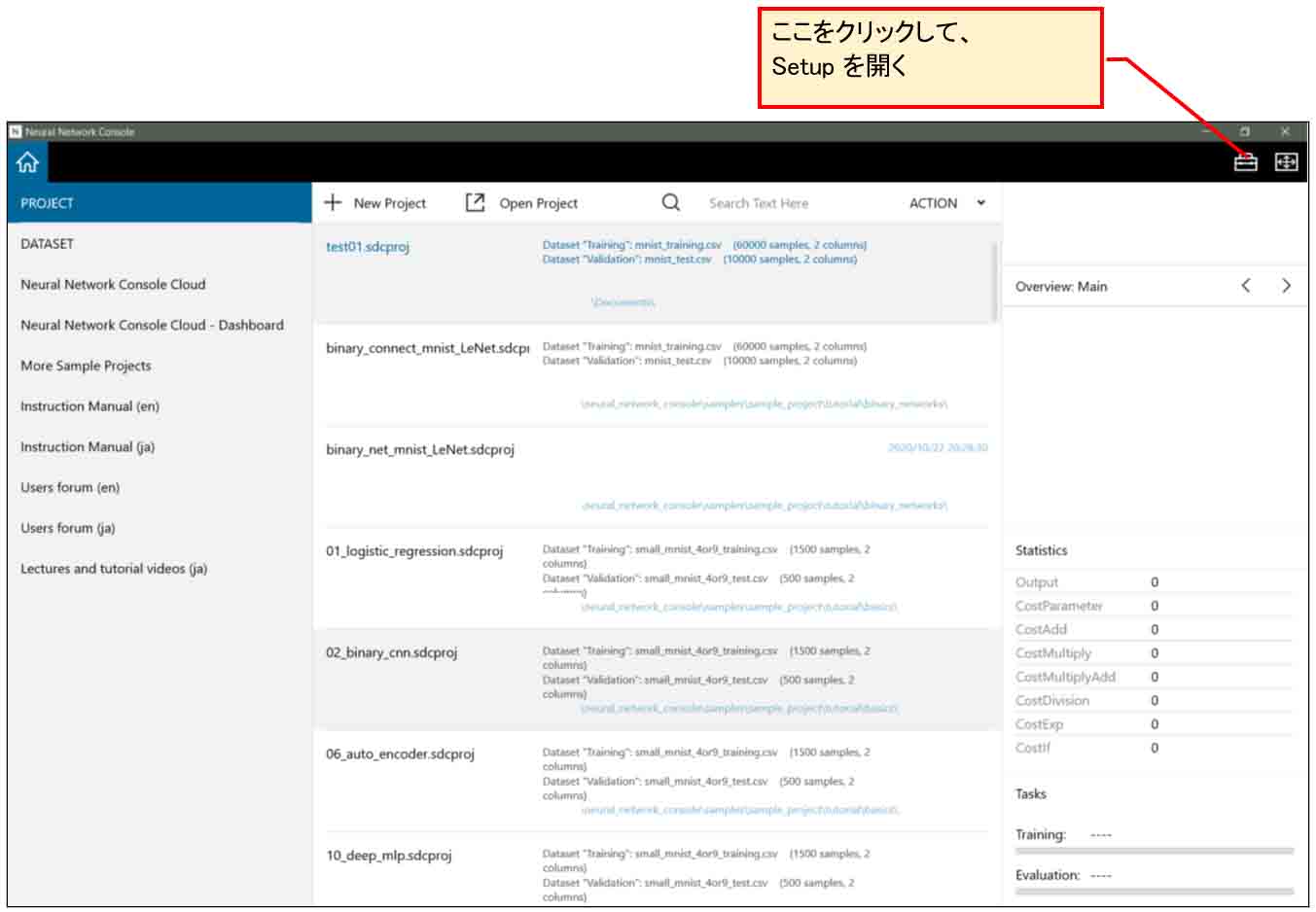
すると、下図の様なウィンドウが開くので、「ENGINE」タブをクリックし、自分のパソコンのGPUを選択して、「Apply」をクリックします。
(図02-02)
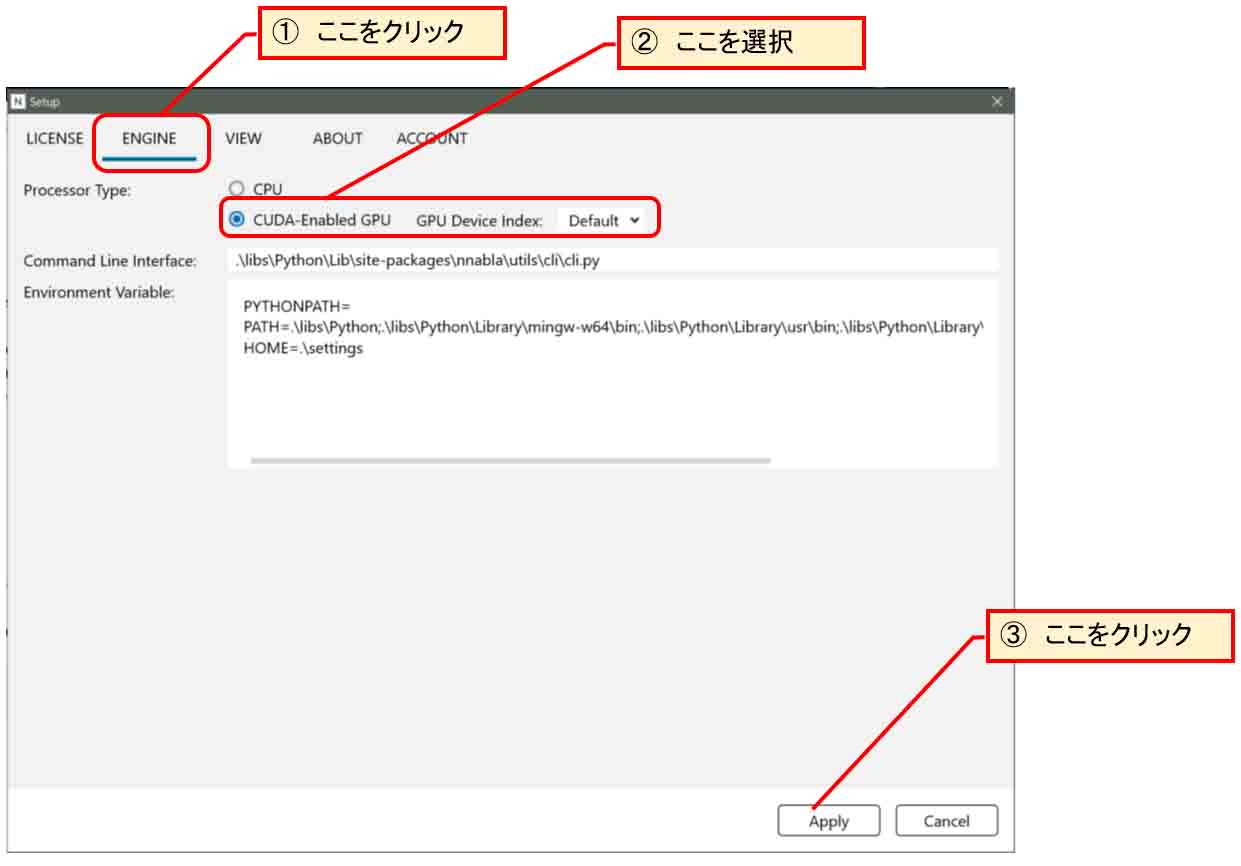
これで学習計算がGPUに設定されました。
3.手書き数字MNISTデータセットのダウンロード
まず、ディープラーニングを始める前に、手書き数字画像のデータセットMNISTをNeural Network Consoleに取り込みたいですね。
幸いなことに、Neural Network Consoleのサンプルファイルを使えば、簡単にダウンロードして取り込むことができることが分かりました。
学習用のデータセットとテスト評価用のデータセットをダウンロードします。
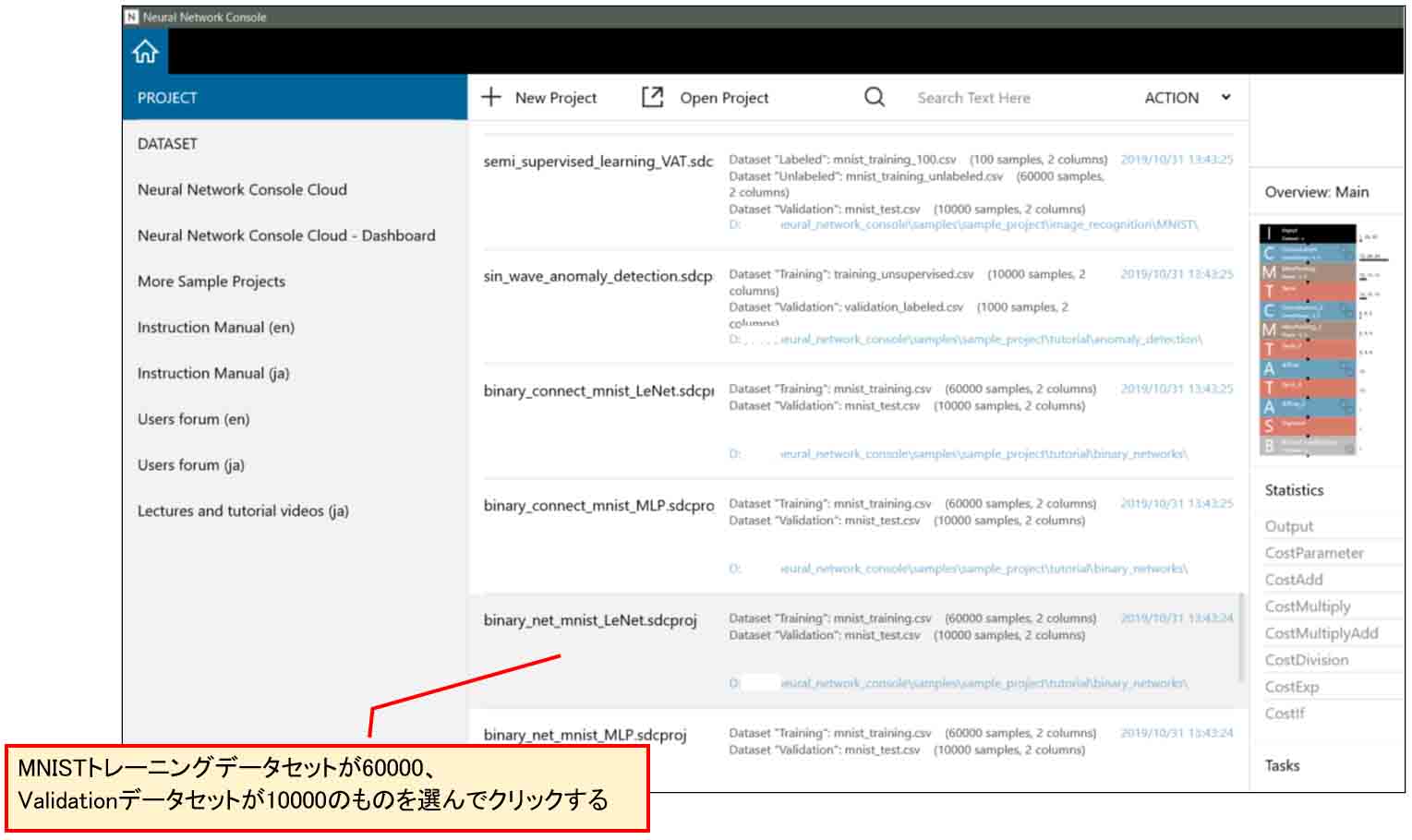
まず、下図の様にサンプルプロジェクトの中のMNISTトレーニングデータセットが60000個、テストデータが10000個のものを選びます。
例えば、
binary_connect_mnist_LeNet.sdcproj
をクリックします。
(図03-01)
すると、下図の様なMNISTデータセットをダウンロードしても良いか?みたいなメッセージが出るので「はい」をクリックします。
(図03-02)
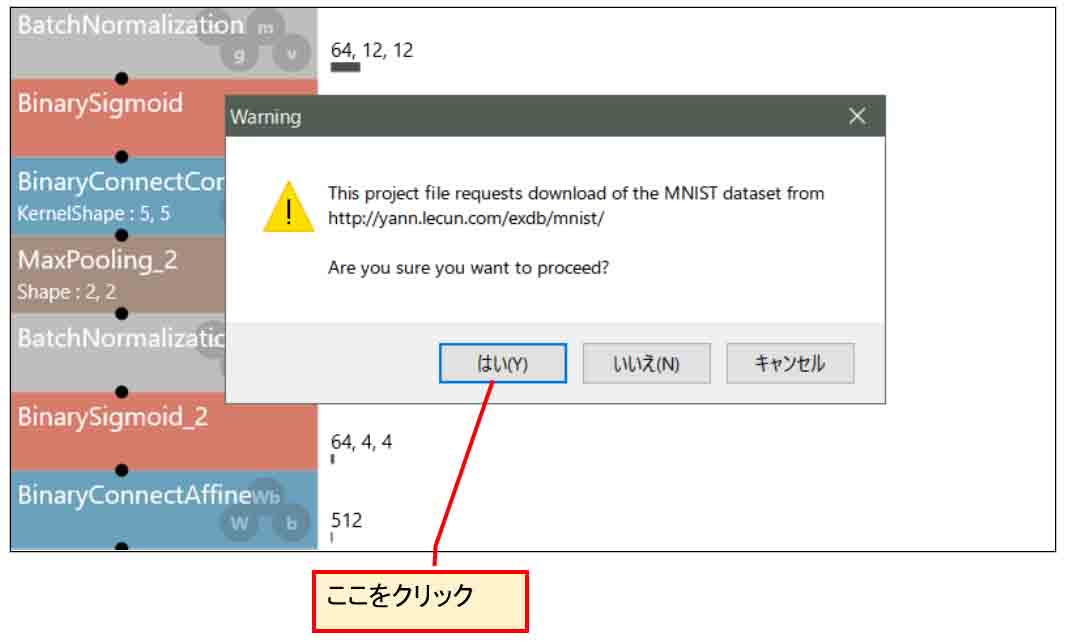
すると、下図の様にダウンロードし始めます。
(図03-03)
ダウンロードが終ったら、下図の様に上部の「DATASET」をクリックします。
(図03-04)
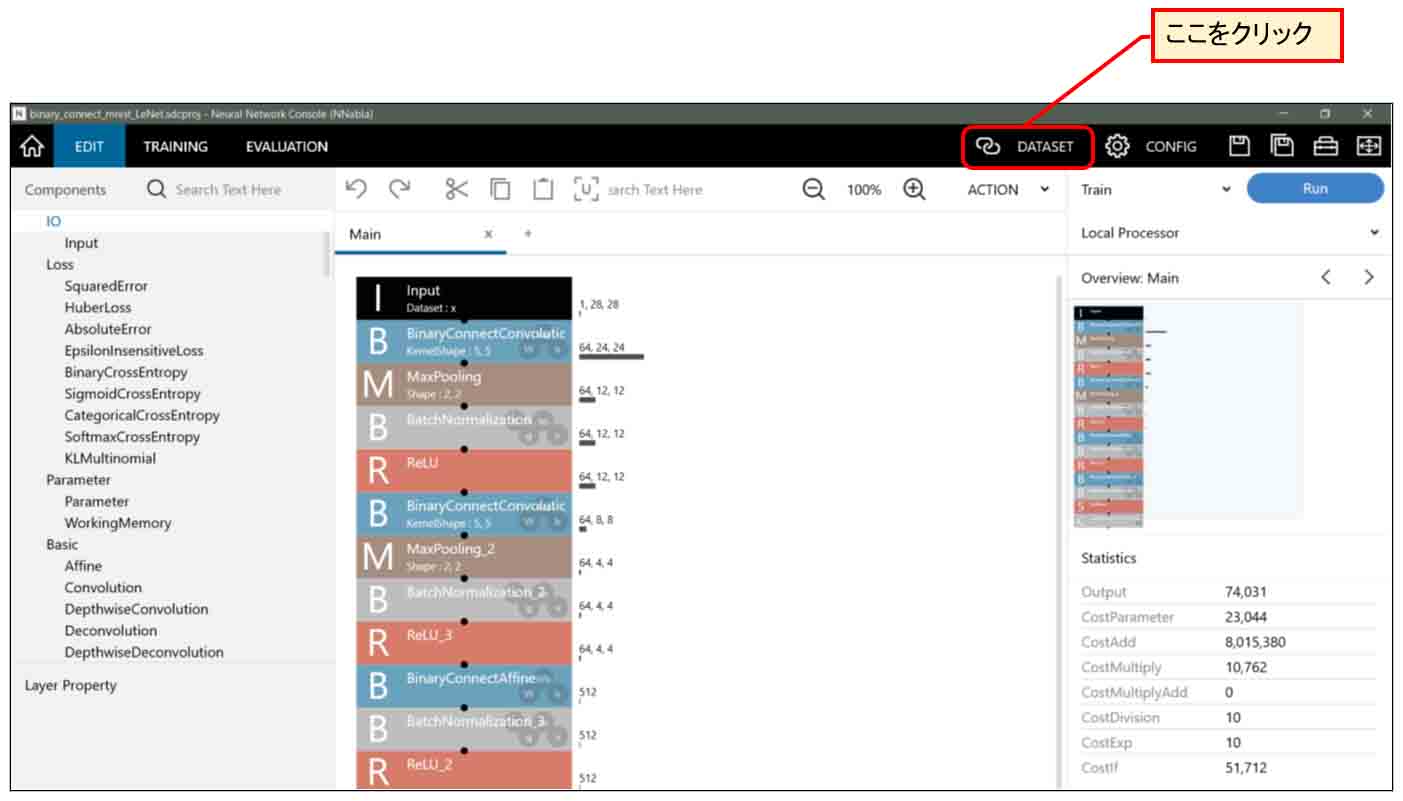
すると、ダウンロードされた手書き数字データセットのTraining(学習用)60000個の一覧が見られます。
そして、Shuffleにチェックが入っているか確認しておきます。
これは、学習させる時に画像データをシャッフルしてランダムに抜粋して学習させるためです。
「Image Normalization」のチェックは、MNIST画僧データが0~255という値なので、前回記事で紹介したように学習計算しやすいように255で割って0~1の範囲の値に収めるためのものです。
(図03-05)
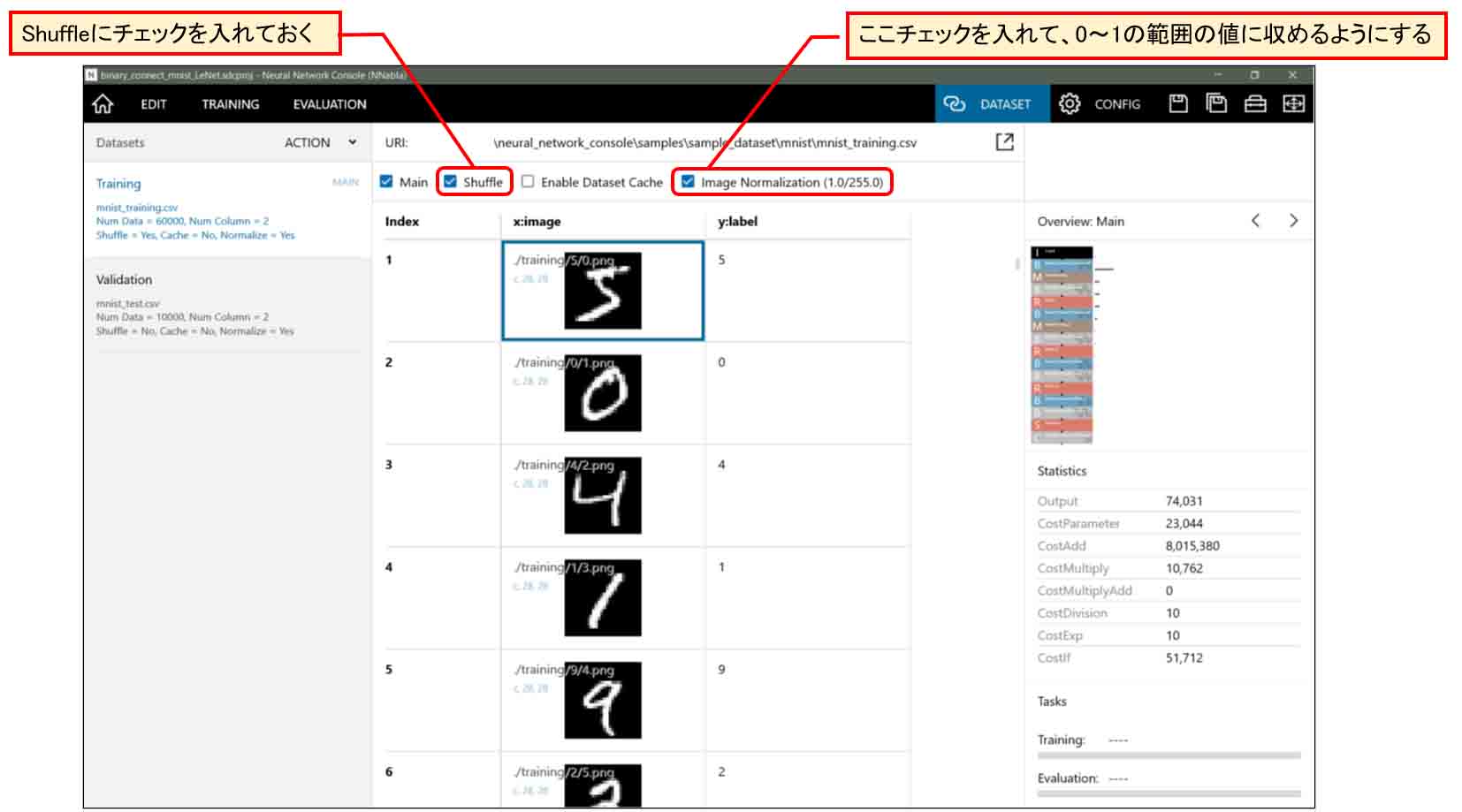
また、下図の様に左側の「Validation」をクリックすると、テスト評価用の10000個のデータセットを見ることができます。
同じように、「Image Normalization」にチェックが入っているか確認しておきます。
ここは、Shuffleのチェックは入っていなくて良いです。
(図03-06)
これで手書き数字MNISTデータセットのダウンロードが完了です。
4.ニューラルネットワークを組んでみる
では、サンプルファイルを使わずに、前回記事の8章で行った畳み込みニューラルネットワークに習って、白紙の状態からニューラルネットワークを組んでいきます。
4-01. 新規プロジェクトを作成する
まず、Neural Network Console のホームアイコンをクリックすると、下図の様な画面になるので、「New Project」をクリックする。
(図04-01-01)
すると、下図の様に白紙のプロジェクト画面になるので、名前を付けて保存しておけば新規プロジェクトができます。
(図04-01-02)
この状態から新たにニューラルネットワークを組んでいくことになります。
4-02. Input(入力層)の設置
まず、左側の欄に様々なニューラルネットワーク用の層モジュールが並んでいると思います。
「Input」をダブルクリックすると、下図の様に入力層がセットされます。
(図04-02-01)
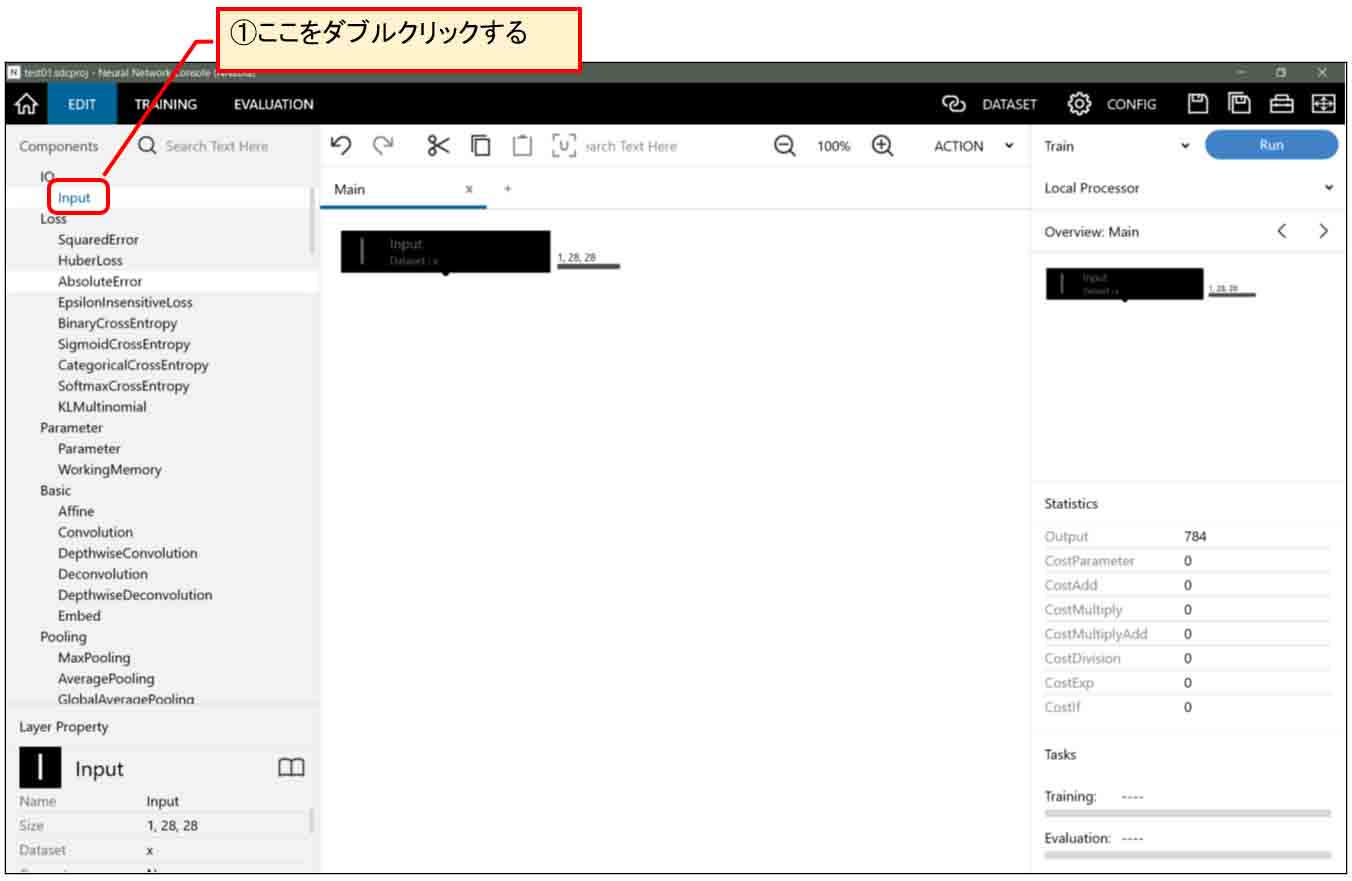
2章でMNISTデータセットはダウンロード済みなので、これだけで28×28個入力層ができました。
簡単ですね。
次に、Input層が選択されている状態と選択されていない状態をマウスでクリックして確かめます。
下図の上の状態は選択されていない状態で、下の方は選択された状態です。
Input層が黒いのでちょっと分かりにくいですね。
(図04-02-02)
とにかく、マウスでクリックしてInput層を選択した状態にしておきます。
4-03. 前処理としての画像圧縮用MaxPooling層設置
次に、Input層の下に画像圧縮のためのMaxPooling層を設置してみます。
Input層を選択した状態で、下図の様にMaxPooling層をダブルクリックします。
(図04-03-01)
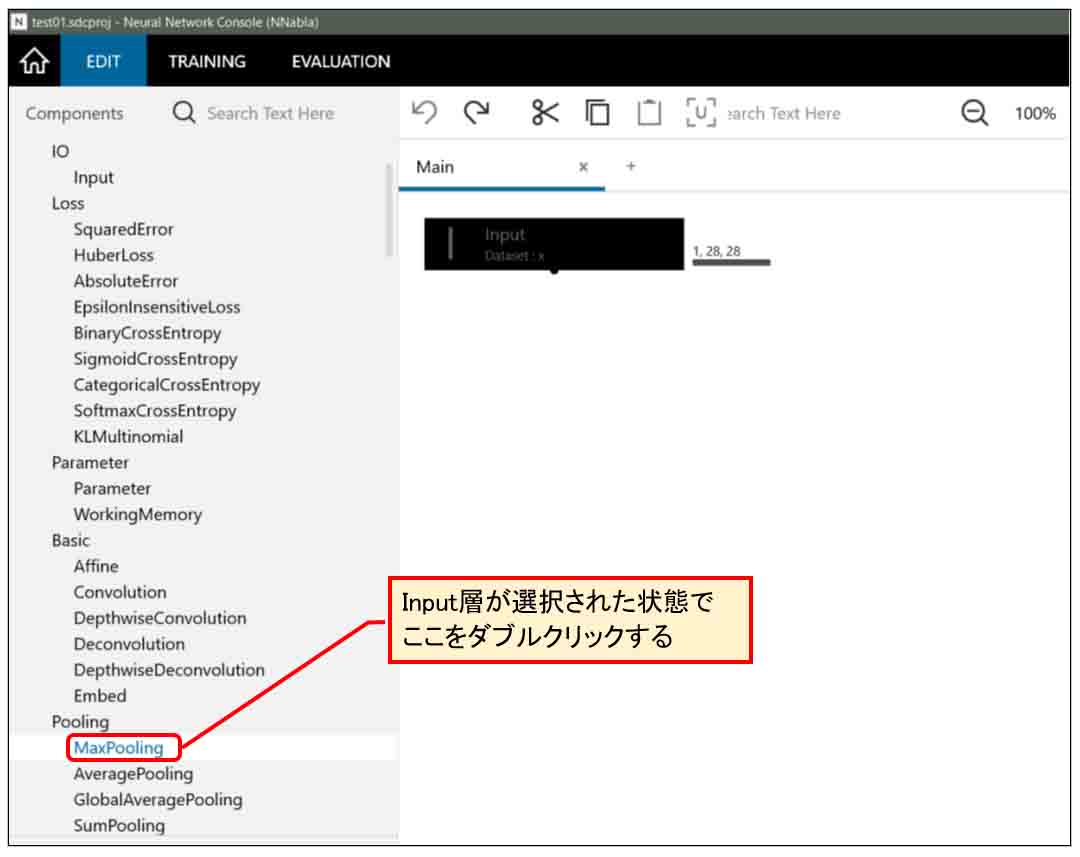
すると、下図の様にInput層のすぐ下に自動的にMaxPooling層がセットされます。
(図04-03-02)
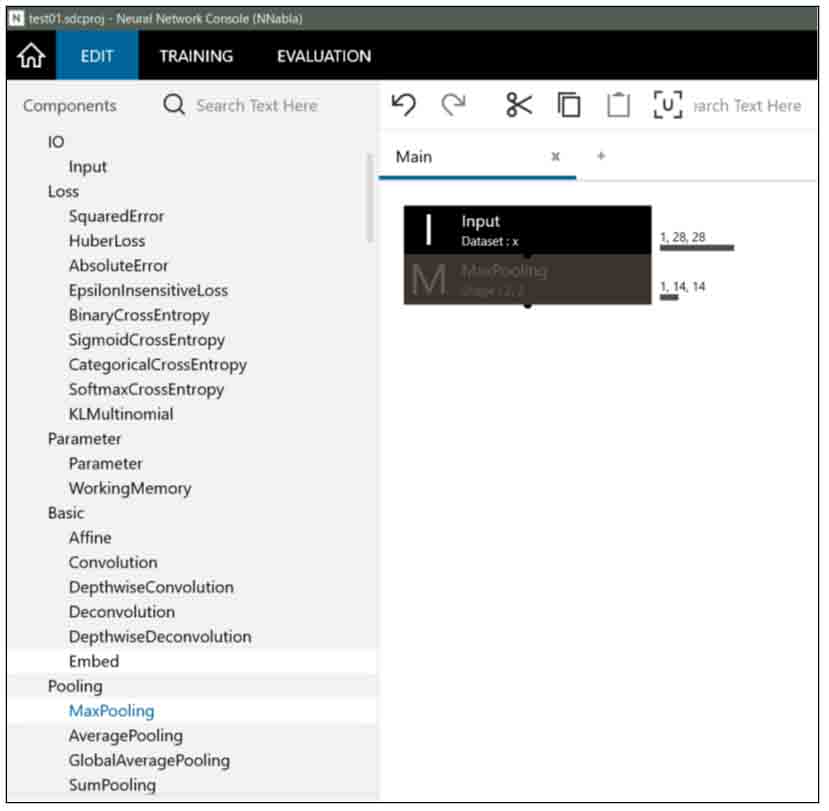
試しに、下図の様にMaxPooling層をマウスでドラッグして移動してみると、線で接続されていることが分かります。
(図04-03-03)
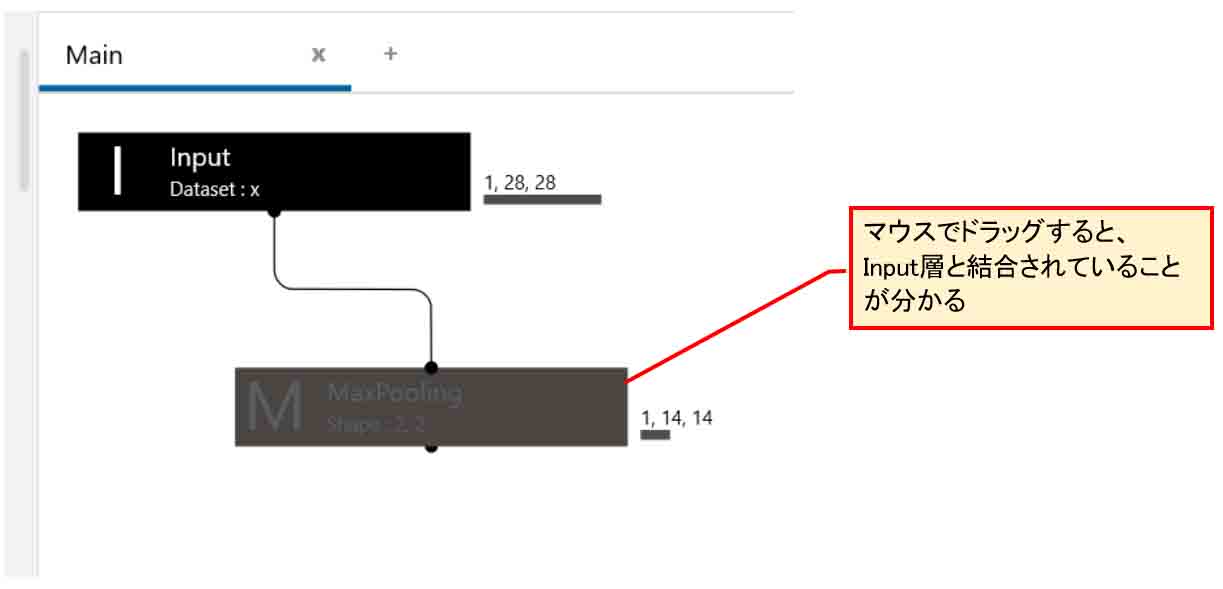
ということで、Input層が選択された状態でMaxPooling層をダブルクリックすると、自動的に結合されるということです。これは便利で簡単ですね。
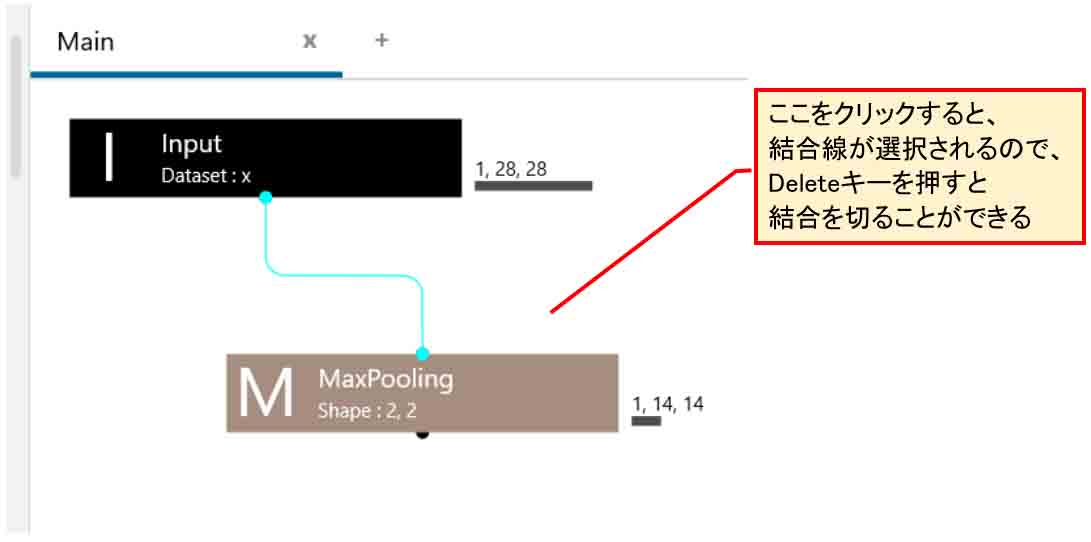
因みに、その線をクリックすると、下図の様に水色になり、Deleteキーを押すと切断することができます。
(図04-03-04)
切断されると、下図の様にMaxPooling層のところでビックリマークのアイコンが出ますので、そこは結合できていないことが一目瞭然です。
(図04-03-05)
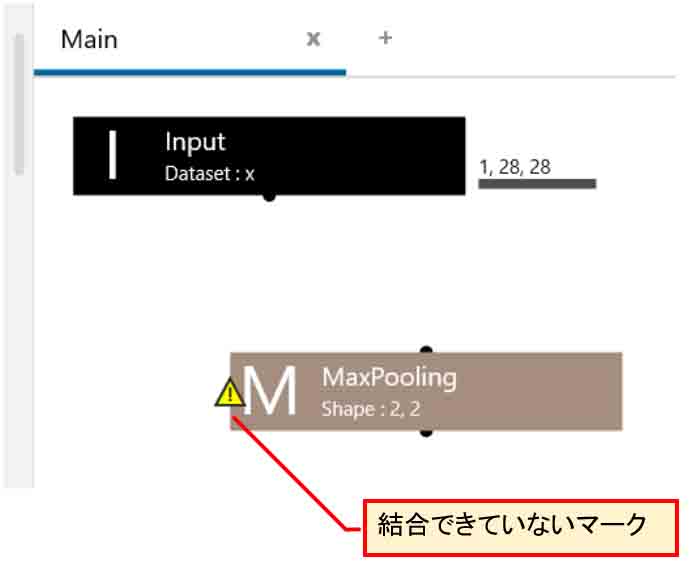
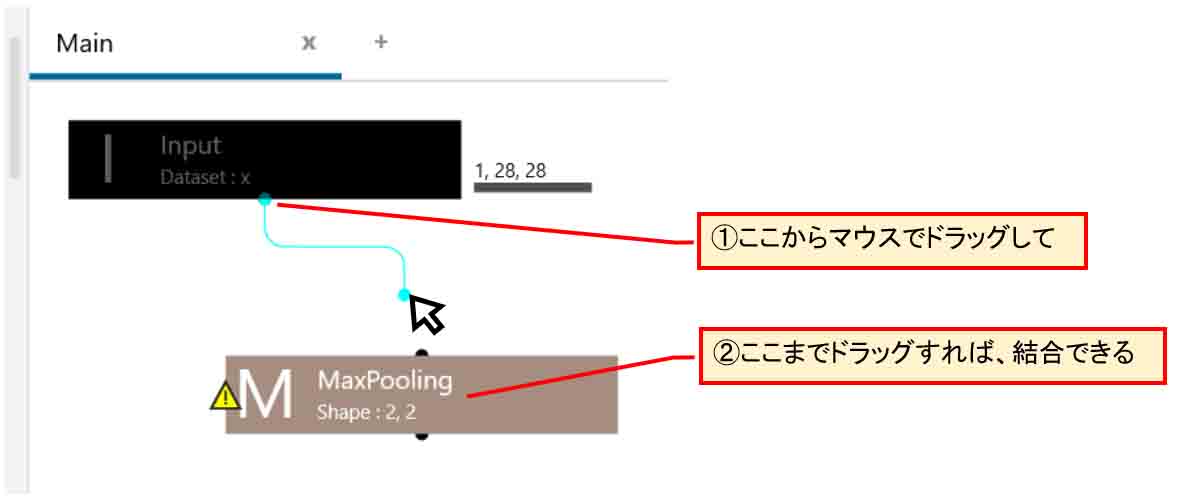
再度、結合させたい場合は、下図の様にInput層の下の方の黒い●印からマウスでMaxPooling層までドラッグすれば結合できます。
(図04-03-06)
次に、下図の様にMaxPooling層をクリックして選択状態にすると、左下部分にMaxPooling層のパラメータを見ることができます。
(図04-03-07)
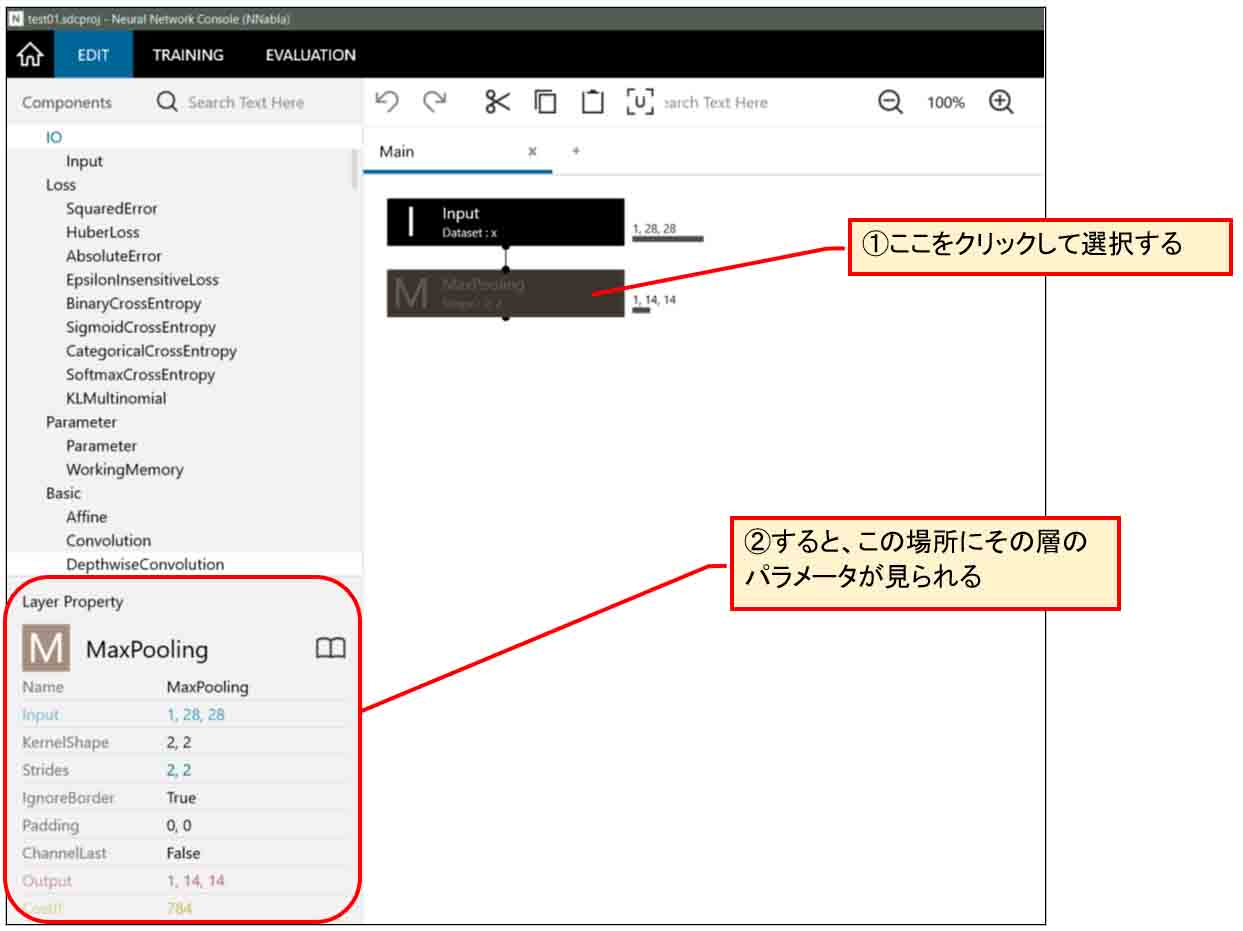
このパラメータの意味は、前回記事で勉強したのである程度わかったのですが、それでも謎なところがありました。
これはある程度ちゃんと理解していないと、意図した結果にならないので注意した方が良いです。
まず、前回記事を見ればわかるのですが、MaxPooling層はデフォルトで2×2マスで抽出していきます。
この2×2マスのことをKernelShape(カーネルシェイプ)と言います。
因みに、この2×2マスのことを畳み込みニューラルネットワーク界隈では一般的にカーネルと呼ばれているそうです。
そして、ストライド(Strides)は2がデフォルト設定です。
ストライドは、前回記事にあるようにマス目のズラし幅です。
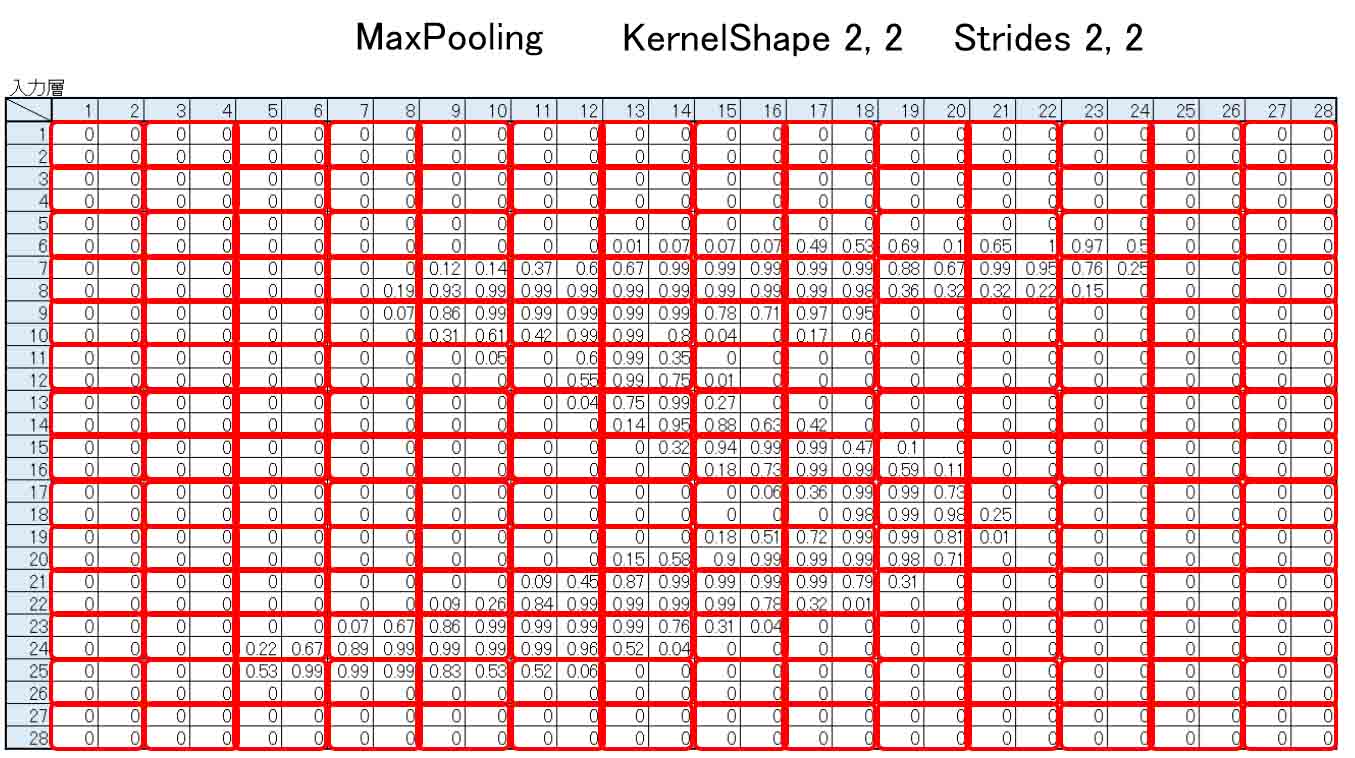
MNISTデータセットは28×28 pixel なので、下図の様にMaxPoolingするとピッタリ割り切れて、出力は14×14となります。
Excelで見るとこんな感じです。
(図04-03-08)
このKernelShapeとStridesは任意に変えられます。
KernelShapeを3×3にすると、自動的にStridesは3,3になり、下図の様に割り切れなくなります。
余った28行と28列の数値は、IgnoreBorder をTrueにすると捨てられてしまいます。
(図04-03-09)
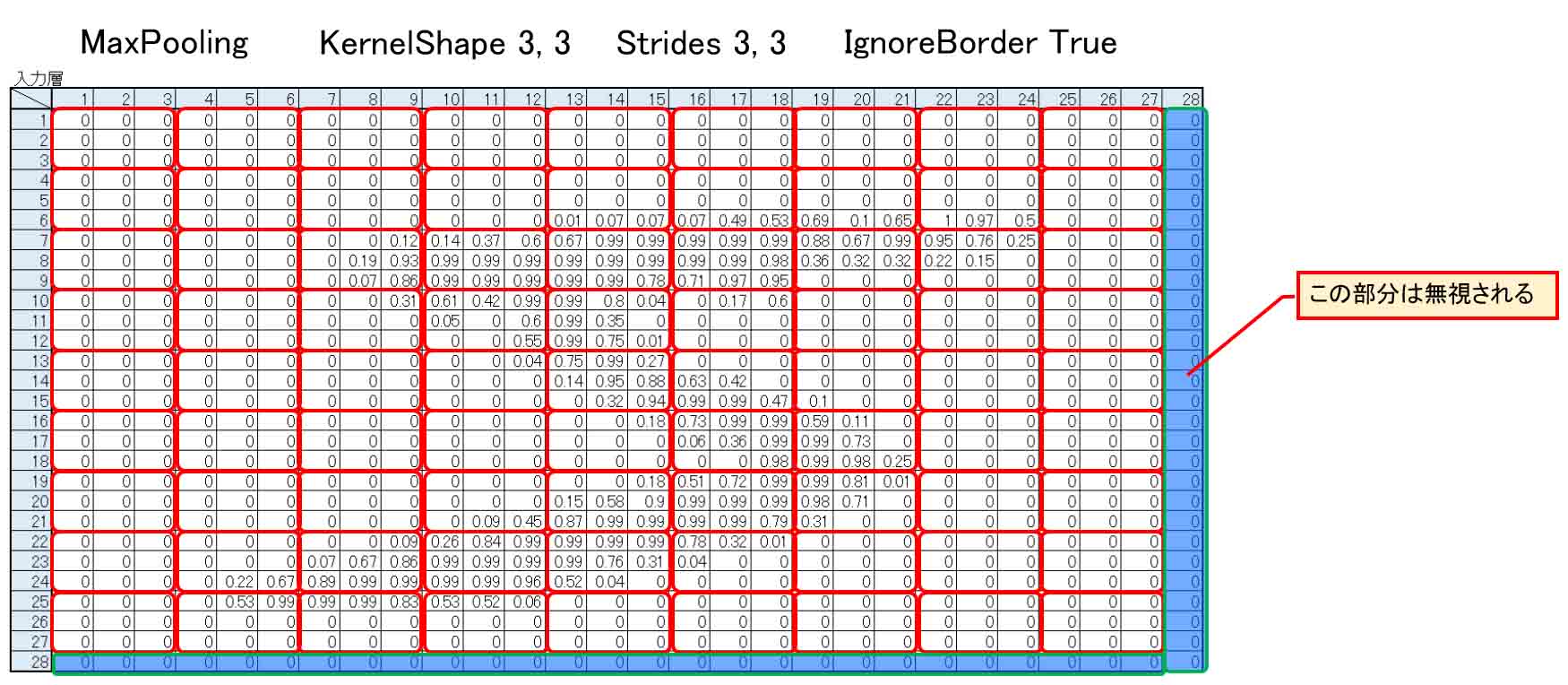
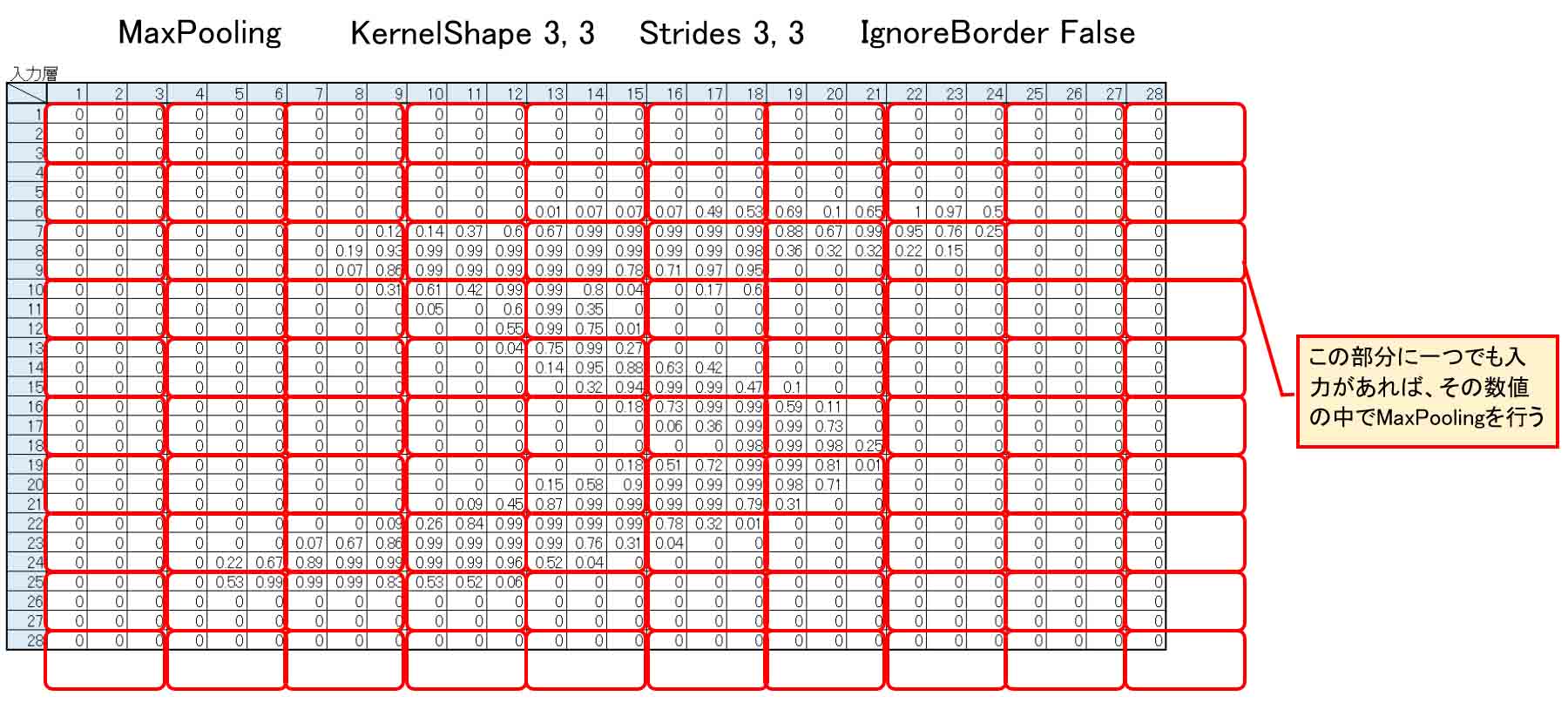
逆に、IgnoreBorderをFalseにすると、下図の様にKernelShapeが28×28のマスからみ出る形になりますが、その中に一つでもデータが入っていれば、その中のうちからMaxPoolingします。
ゼロでも値が入っていることになります。
すると、出力は10×10となるわけです。
(図04-03-10)
次に、パディング(Padding)ですが、これはとても勘違いし易いので要注意です。
私は思い込みで理解していて、しばらく誤っていることに気付きませんでした。
Paddingの最初の項が1、つまり Padding 1, 0 ならば、入力層の上下に1列ゼロを挿入するとのことです。
下図の様な感じです。
(図04-03-11)
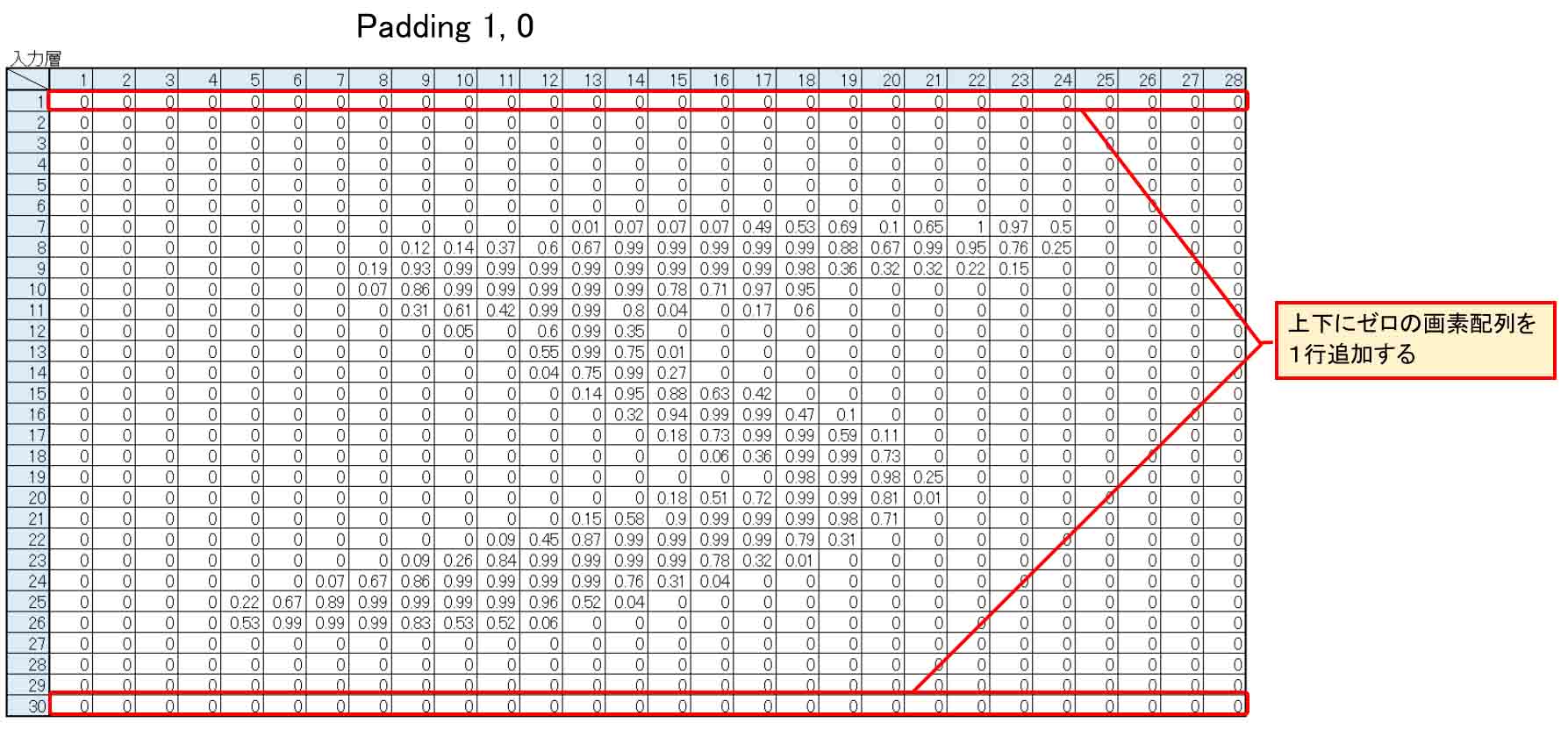
つまり、28×30 pixel となり、2行増えることになるわけです。
私は下の列だけ挿入されるのかと思い込んでいました。
上下に挿入されるという所がポイントで、要注意です。
同様に、Paddingの2番目の項が1、つまり、Padding 0, 1 の場合には、下図の様に左右に1列ゼロが挿入されます
(図04-03-12)
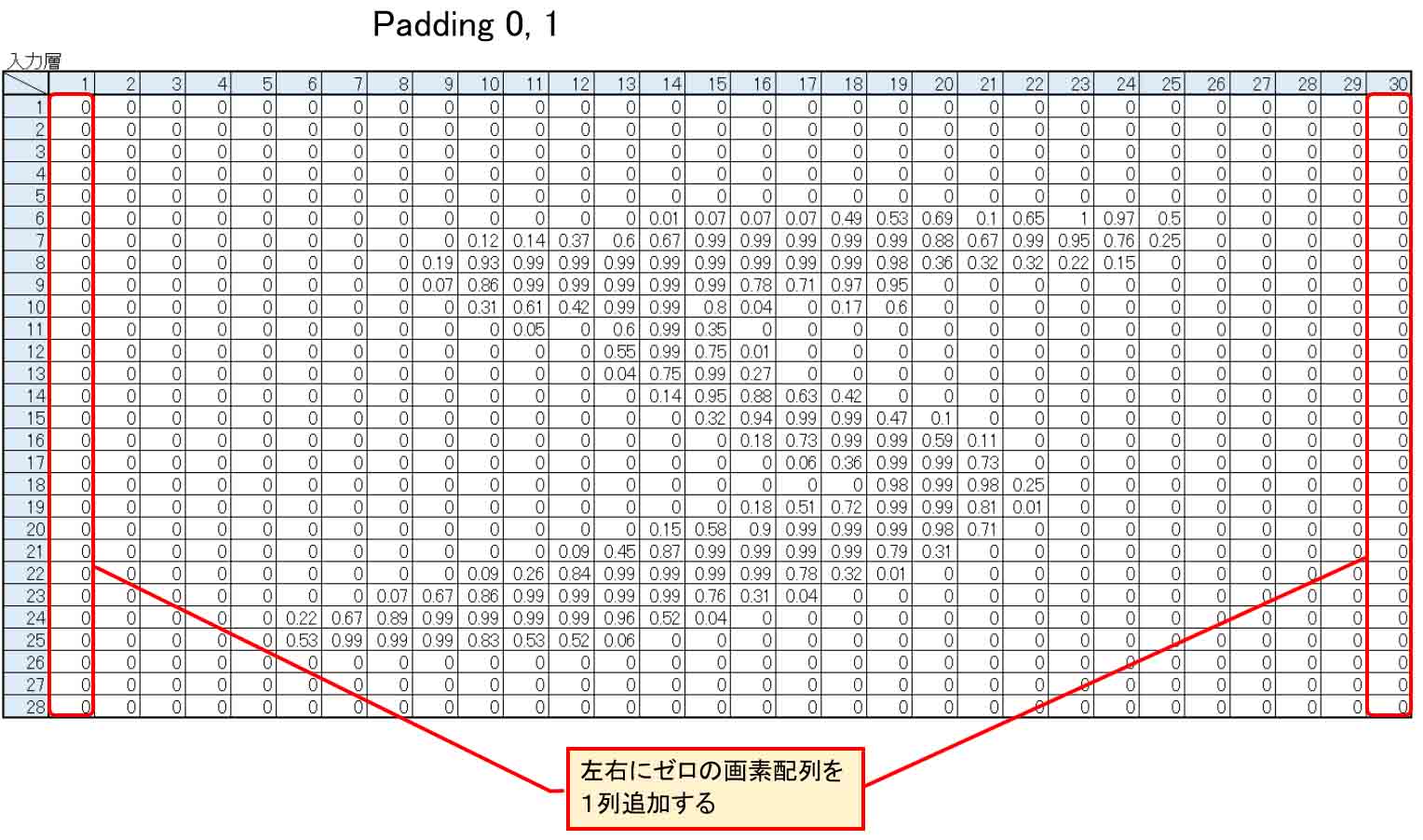
つまり、30×28 pixelになります。
ここはとても勘違いし易いので、間違えない様にしたいですね。
因みに、Padding 1, 1 ならば下図の様に30×30 pixel になり、KernelShape 3, 3 でも割り切れて、出力が10×10になるわけです。
(図04-03-13)
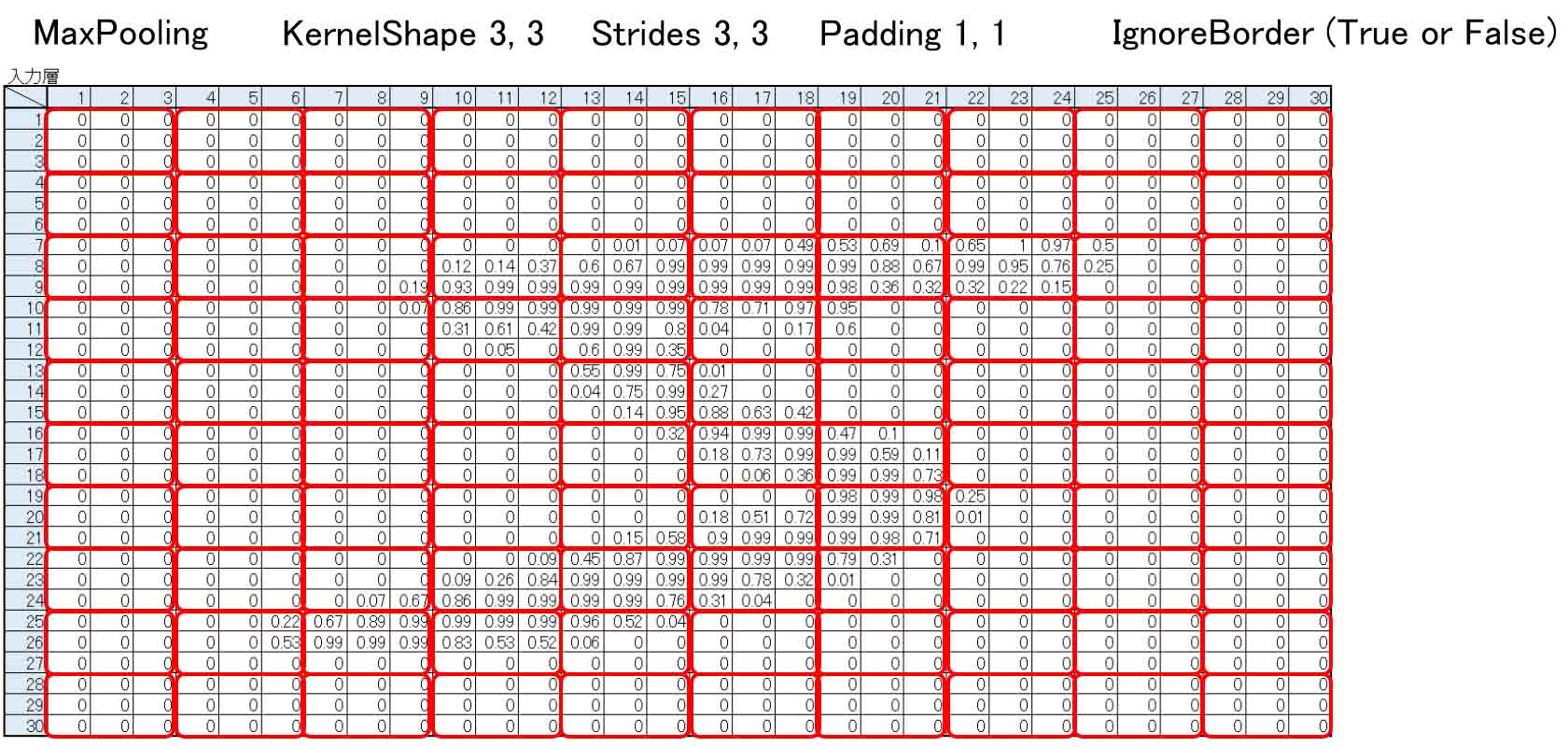
この場合は、IgnoreBorderはTrueでもFalseでもどちらでも良いということになります。
その他、ChannelLast というものがありますが、私には意味が分かりませんでした。
これをTrueにすると、出力が14×28になってしまって、全く意味不明です。
PDFマニュアルには「入力の最後の次元を無視する」とありますが、それも意味不明です。
わかる方がいらっしゃったら教えてください。
とりあえず、Falseにしておけば使えるのではないかと思います。
以上より、MaxPooling層のパラメータの意味が大体わかったところで、
KernelShape 2, 2
Strides 2, 2
IgnoreBorder True
Padding 0, 0
ChannelLast False
としておきます。
因みに、前回記事ではこの後にReLu関数を使っていましたが、あまり精度が上がらないので、ここでは使わない事にします。
4-04. Convolution(畳み込み層)を設置する
次に、Convolution(畳み込み層)を設置してみます。
MaxPooling層をクリックして選択した状態にして、左側のConvolutionをダブルクリックすると、下図の様にセットされます。
(図04-04-01)
そうしたら、先ほどと同じように左下のレイヤープロパティーを見て、編集していきます。
前回記事の8章に習って、下図の様にパラメータを決めます。
(図04-04-02)
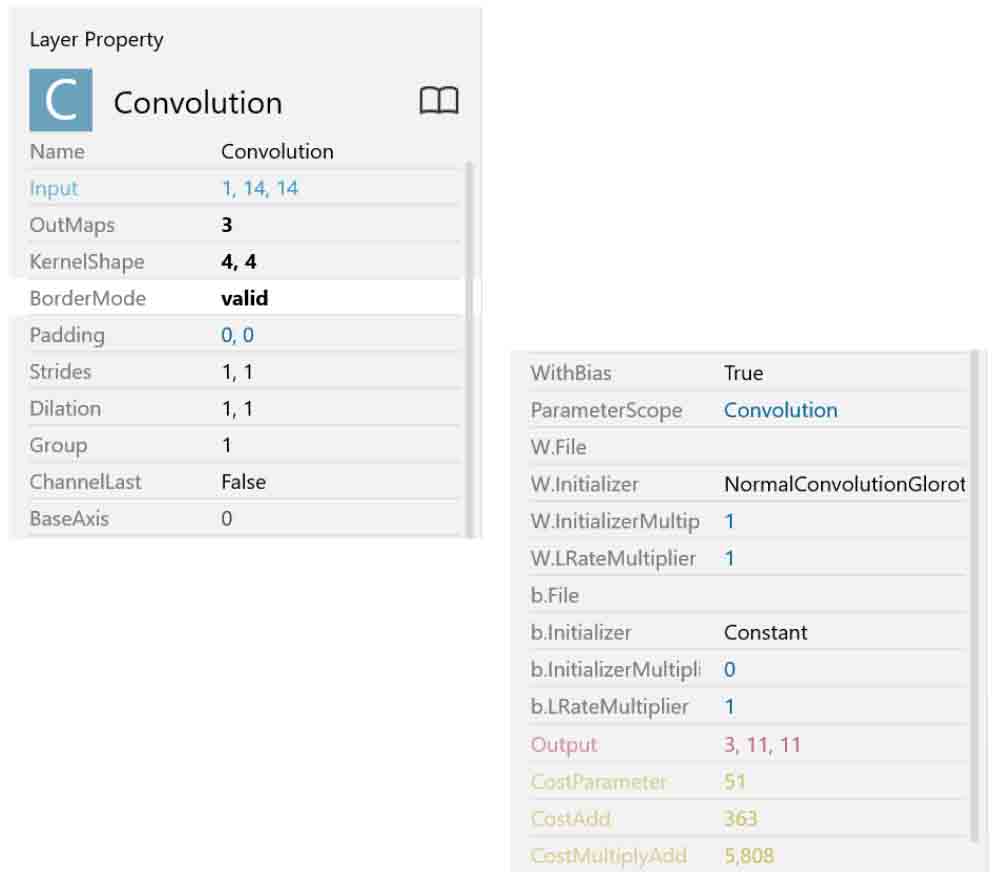
OutMaps の数値は3にします。
それはKernelShapeの数です。
つまり、4×4の重みフィルターが3つあるということです。
その数は、出力ニューロン(ノード)数にもなります。
BorderMode は、validにするとKernelShapeで畳み込みが可能な範囲まで行い、それ以外は無視するというモードです。
この場合、Stridesが1,1の為に範囲にピッタリ収まるので、validで良いと思います。
Stridesが2以上になると、ここをtrueにする必要があるかと思います。
sameはしばらく使う機会が無いように思います。
Paddingは先ほど説明したとおりで、ここでは0,0で良いです。
Dilation、Group、ChannelLast、BaseAxis はよくわからないので、図のようにすれば良いかと思います。
WithBias は、重みの結合計算の閾値であるバイアスを使うかどうか、ということなので、ここではTrueにします。
W.Initializer は、学習計算前に、重み(W)に事前に入力しておく初期値のことです。
前回記事のExcelで畳み込みニューラルネットワークディープラーニングをやった時、ソルバー計算の前の重み(W)にRAND関数を使って事前に入力して置きましたが、そのことです。
この初期値のデフォルトは、NormalConvolutionGlorotとなっていますが、それは、ガウス乱数にXavier Glorot氏の提案の係数を掛けたものだそうです。
ディープラーニングでは、Xavier Glorot氏の論文による提案の初期化が良いとされているそうです。このあたりは私は素人なので正直良くわかりません。
b.Initializer は、同じく学習計算前のバイアス値の初期化です。
これはデフォルトでConstantとなっていて、全て1.0で初期化するとのことです。つまり、出力値が最大値から学習スタートするということだと思われます。
その他もデフォルト設定で上図のようにしておけば良いと思います。
これで、1層目のConvolution(畳み込み層)はOKで、出力は11×11が3ノードとなります。
4-05. MaxPooling層を作る
4-03節でMaxPooling層を作りましたが、今度はConvolutionの後のMaxPoolingを作ります。
Convolution層を選択した状態で、MaxPoolingをダブルクリックすると、以下のようになります。
(図04-05-01)
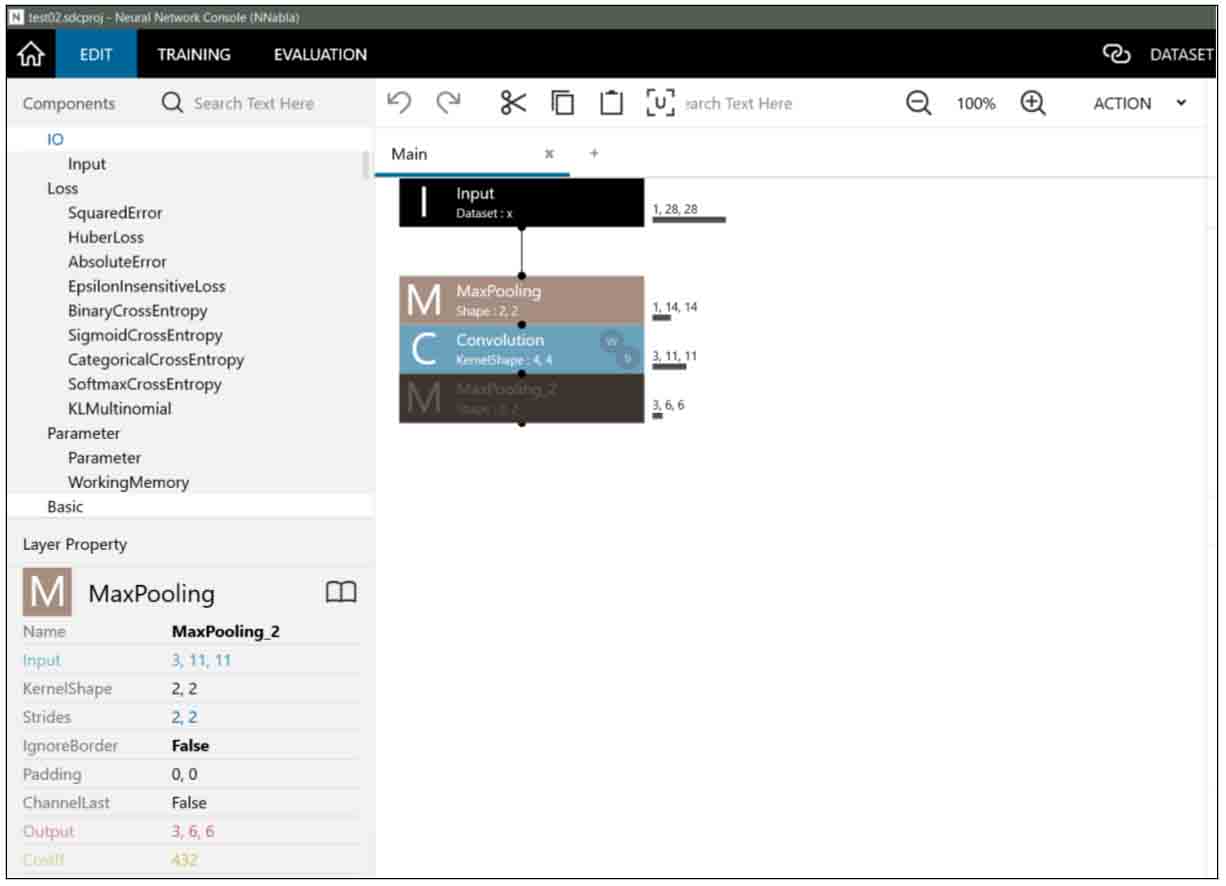
見て分かる通り、4-03節と違うところは、入力が11×11で、KernelShapeが2×2、ストライドが2では割り切れないところです。
割り切れない場合はPaddingを使いたくなりますが、そうすると誤った使い方になってしまいますので、注意が必要です。
例えば、Padding 1, 1 とすると、下図の様に上下左右に0の列と行が挿入されます。
負の値があった場合、その状態でMaxPoolingすると、出力値は最大値の0となってしまいます。
(図04-05-02)
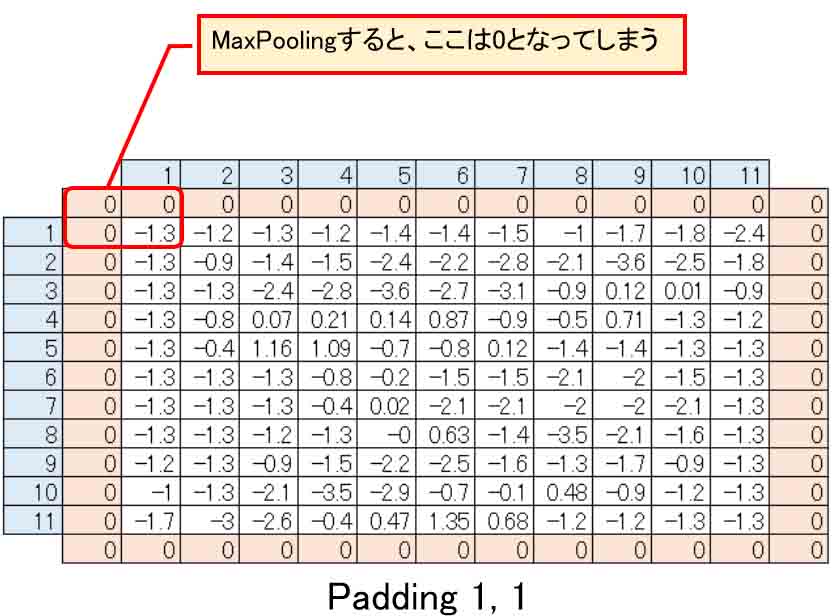
そうなると、入力段階で全て正の値に限定する処理をしなければなりません。
しかし、ここでは負の値を許容するので、Paddingは0, 0とすることが正解だと思います。
そして、IgnoreBorderはFalseにして、はみ出た部分の値が一つでも入っていればMaxPoolingするという設定にします。
よって、MaxPooling層のパラメータは以下のようにします。
(図04-05-03)
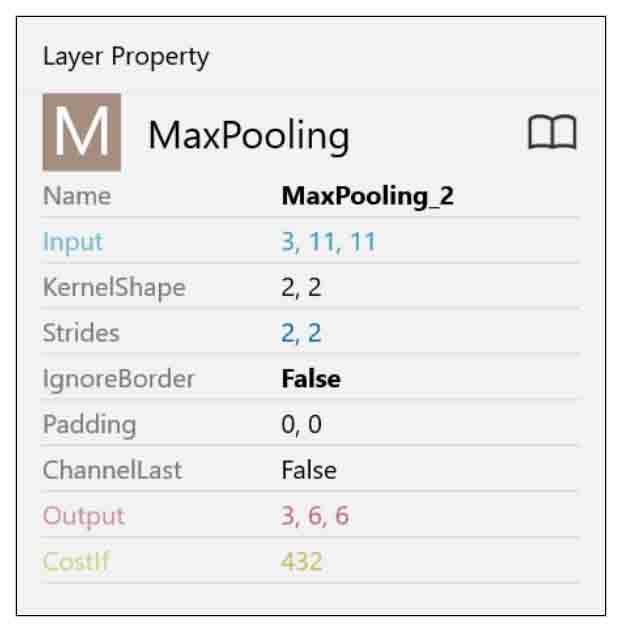
これで、出力は6×6の3ノードとなります。
4-06. Tanhを追加する
次に、前回記事に習って、出力の値を-1.0~+1.0の間に収めるためにTanh関数を追加します。
下図の様な感じです。
(図04-06-01)
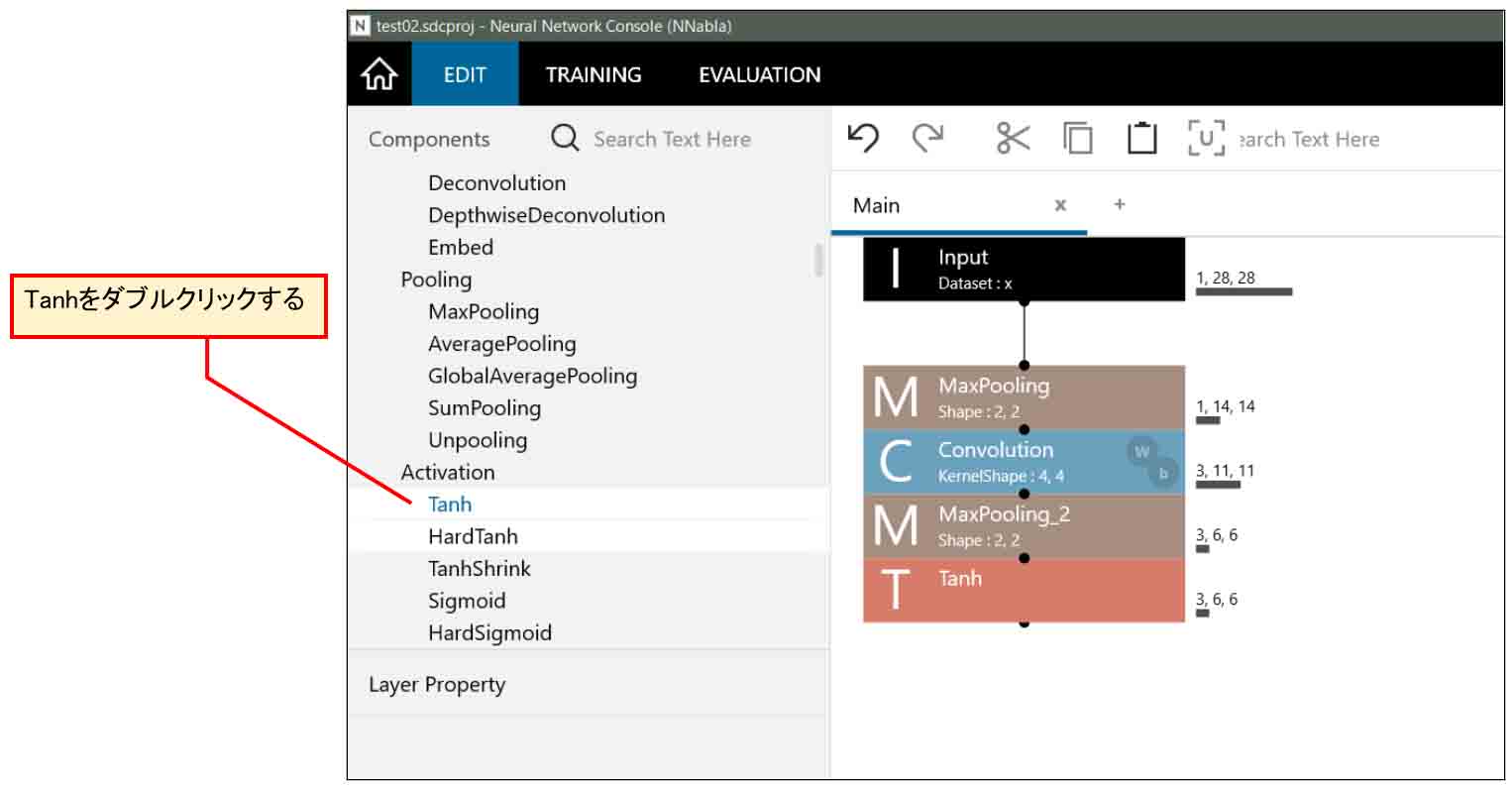
これは特にパラメータの設定は無いので、そのままでOKです。
4-07. 2回目のConvolution、MaxPooling、Tanhを作る
次に、前回記事の8章のネットワークに習って、2層目のConvolution(畳み込み層)、MaxPooling層を作ります。
実は、前回記事の8章の2層目畳み込みは通常のConvolutionではなく、Depthwise Convolutionというものだったのです。
Depthwise Convolutionについては次回の記事で詳しく述べたいと思います。
ここでは通常のConvolutionで話を勧めます。
では、2つ目の通常のConvolutionを設置すると、下図のようになります。
(図04-07-01)
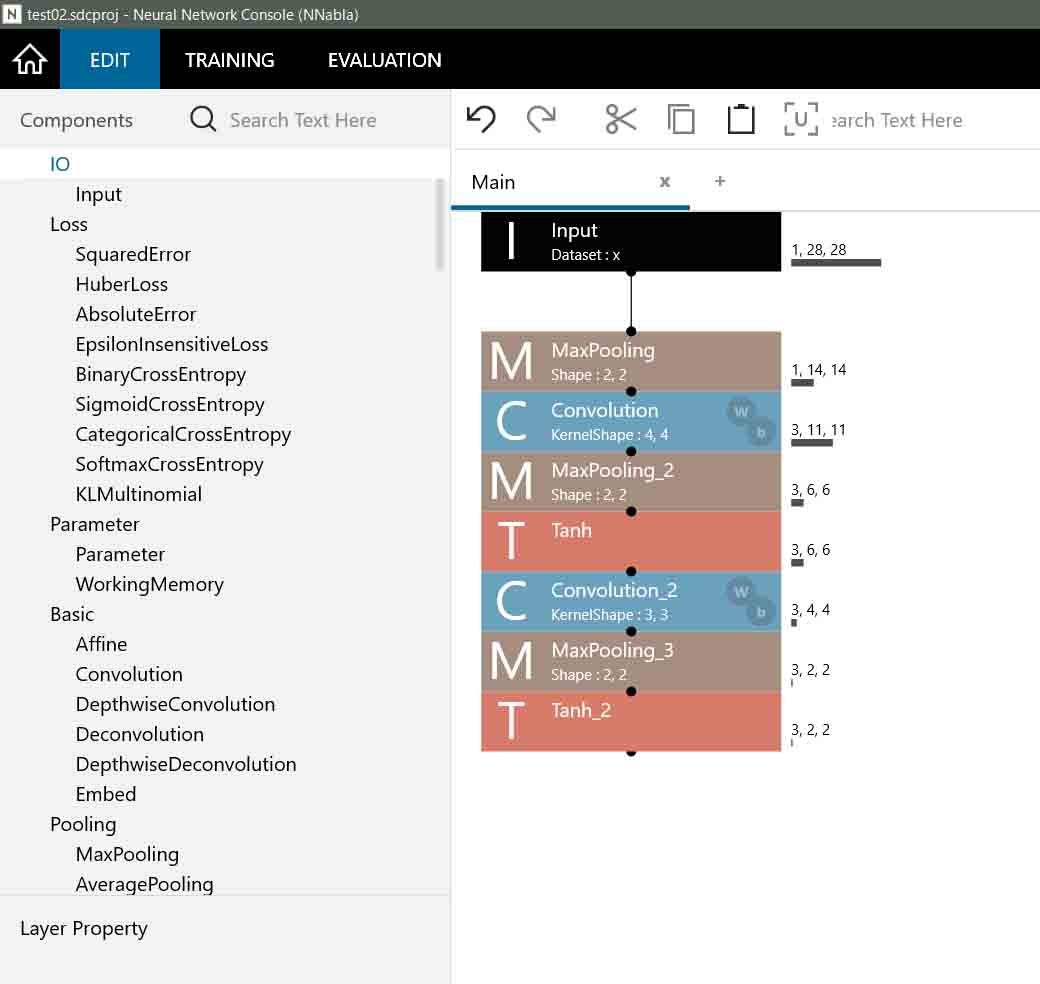
Convolution(畳み込み層)とMaxPooling層のパラメータは下図の通りです。
(図04-07-02)
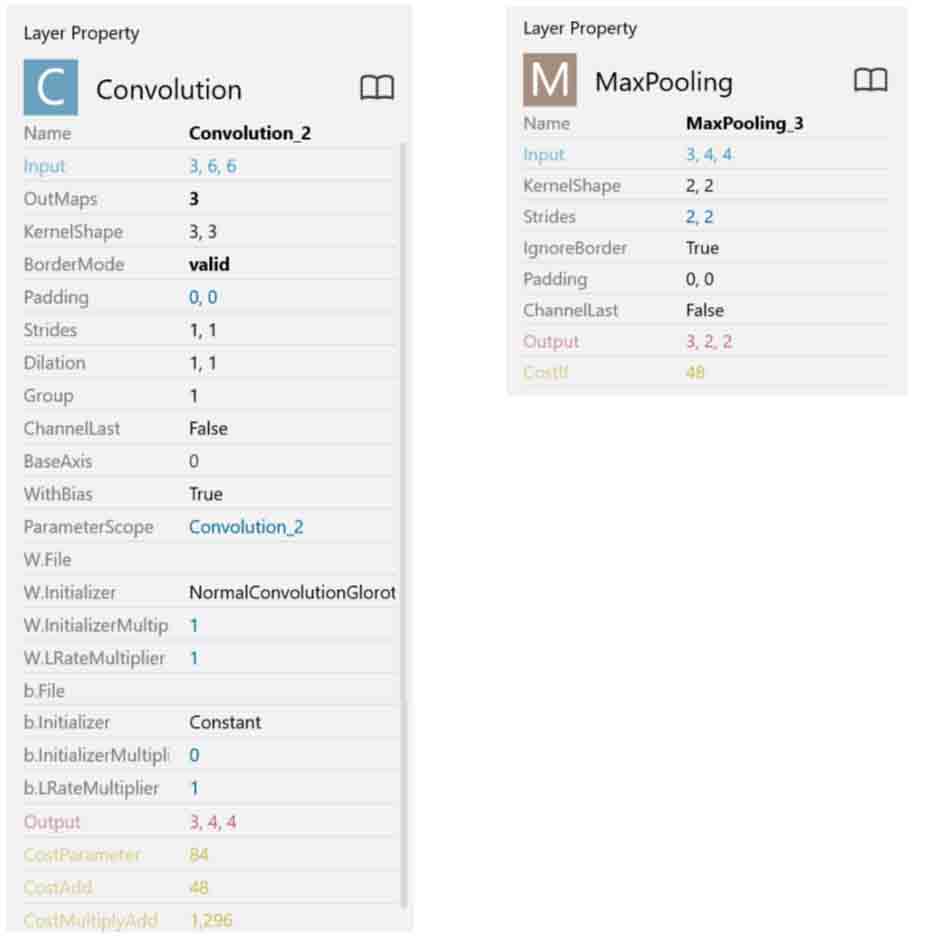
入力が6×6マスの3ノード(ニューロン)なので、Convolution(畳み込み層)は、
OutMaps: 3
KernelShape: 3, 3
Strides: 1, 1
Padding: 0, 0
とすると、出力は4×4マスの3ノード(ニューロン)となります。
続いて、MaxPooling層は、
KernelShape: 2, 2
Strides: 2, 2
IgnoreBorder: True
Padding: 0, 0
とすると、出力は2×2マスの3ノード(ニューロン)となります。
ここまで畳み込めれば次のAffineの重みパラメータが少なくて済むので充分です。
あとは、Tanhを追加して、-1.0~+1.0の範囲に収めればOKです。
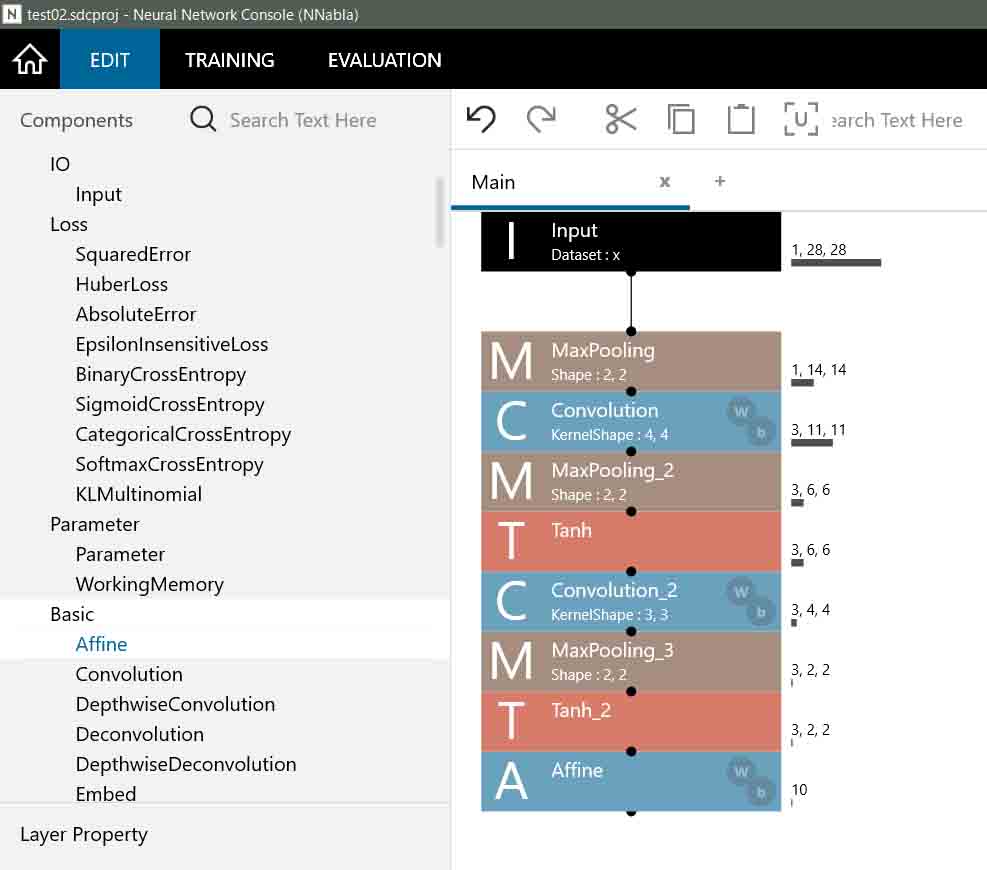
4-08. Affine(全結合層)を追加
では、出力層へ向けて、Affine(全結合)層をセットします。
すると、下図のようになります。
(図04-08-01)
各パラメータ設定は以下のようにしました。
(図04-08-02)
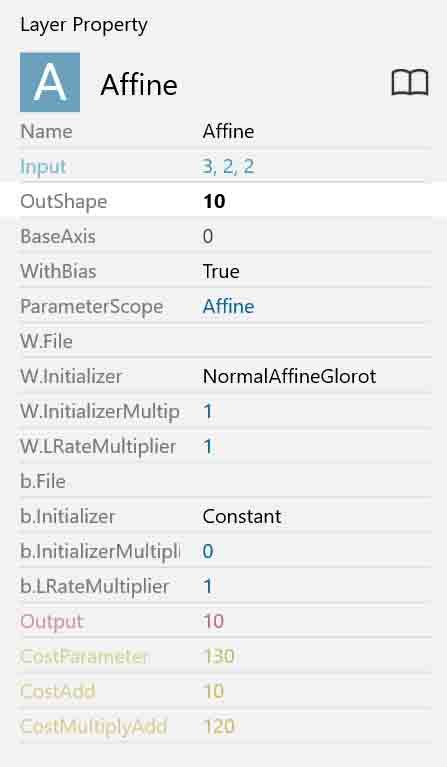
出力層は手書き数字0~9の10種類の判定なので、10ノード(ニューロン)となり、OutShapeは10にします。
その他は上図の設定で良いと思います。
4-09. SoftmaxおよびCategoricalCrossEntropyをセットする
さて、最後の出力層の前に、前回記事の8章のようにまずSoftmax層をセットします。
Softmaxは前回記事で紹介したように、2値を超える分類の場合はSoftmax関数を使うべきです。
ただ、前回記事ではSoftmax処理の後に平方誤差を使っていました。
すると、Neural Network Console上ではSquaredErrorになるのかなと思って使ってみました。
しかし、どうもうまく行きませんでした。これについては後で詳しく述べます。
Deep Learning では一般的にSoftmaxの後の多値分類判別は、SquaredErrorではなく、CategoricalCrossEntropyというものを使うようです。
実際、それを使ってみると、Neural Network Consoleでは期待通りの動作になりました。
どうやら、Softmax と CategoricalCrossEntropyは一体として考えておけば、Neural Network Console上では無難なようです。
CategoricalCrossEntropyについては、ネットの情報を見ても正直よくわかりませんでした。
ということで、SoftmaxとCategoricalCrossEntropyを設置すると下図のようになります。
(図04-09-01)
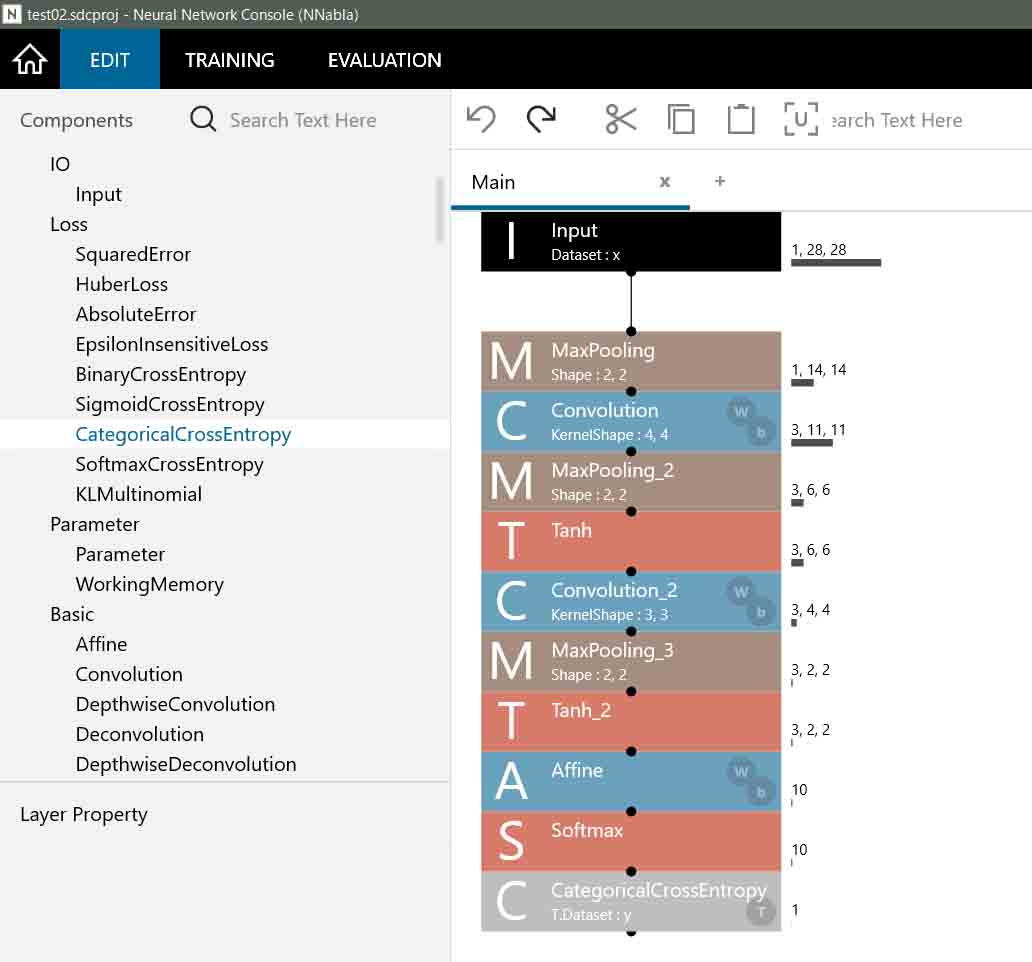
実は、SoftmaxとCategoricalCrossEntropyは別々にしなくても、既に一体化したSoftmaxCrossEntropyというものがあるのですが、ここでは自分自身が理解しやすいように別々の層にしました。
各々のパラメータは下図のようになります。
(図04-09-02)
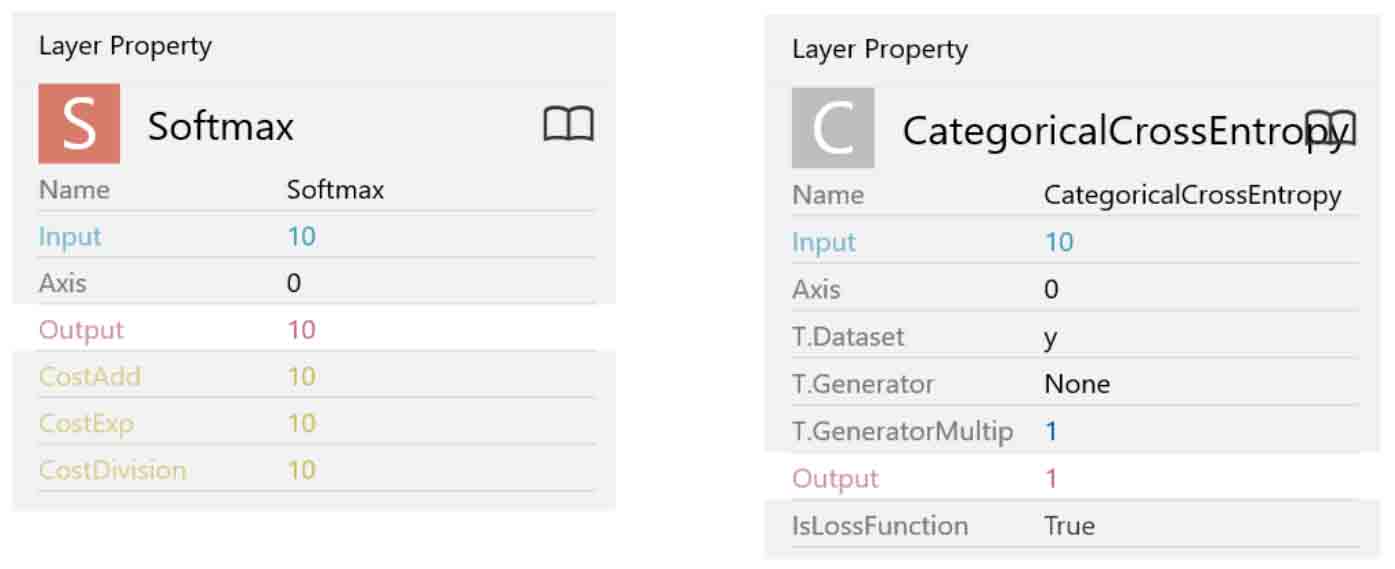
パラメータはこのままで特に変更する必要は無いです。
ただ、CategoricalCrossEntropyのOutPut(出力)が1というところが謎で、私の様な初心者には気になってしまいます。
考えてみれば、前回記事8-2で勉強していた時は平方誤差でしたが、出力10個の合計を算出して、その値を最適化対象としているので、出力が1に相当するのかなと個人的に理解しました。
いずれにしても、私自身、CategoricalCrossEntropyという物の計算式を全然理解できていないので、あくまで想像の範囲ですが、、、。
以上で、前回記事8章に習ったニューラルネットワーク作成は完了です。
5.学習させる(Training)
では、いよいよDeep Learning(深層学習)させてみます。
まずはデフォルト設定のままいきなり学習させてみます。
前回記事ではExcelのソルバーを使いましたが、Neural Network Consoleの場合はとっても簡単です。
下図の様に、EDIT画面で右上の「RUN」ボタンをクリックするだけです。
(図05-01)
すると、「TRAINING」画面に移り、下図の様なグラフになりました。
(図05-02)
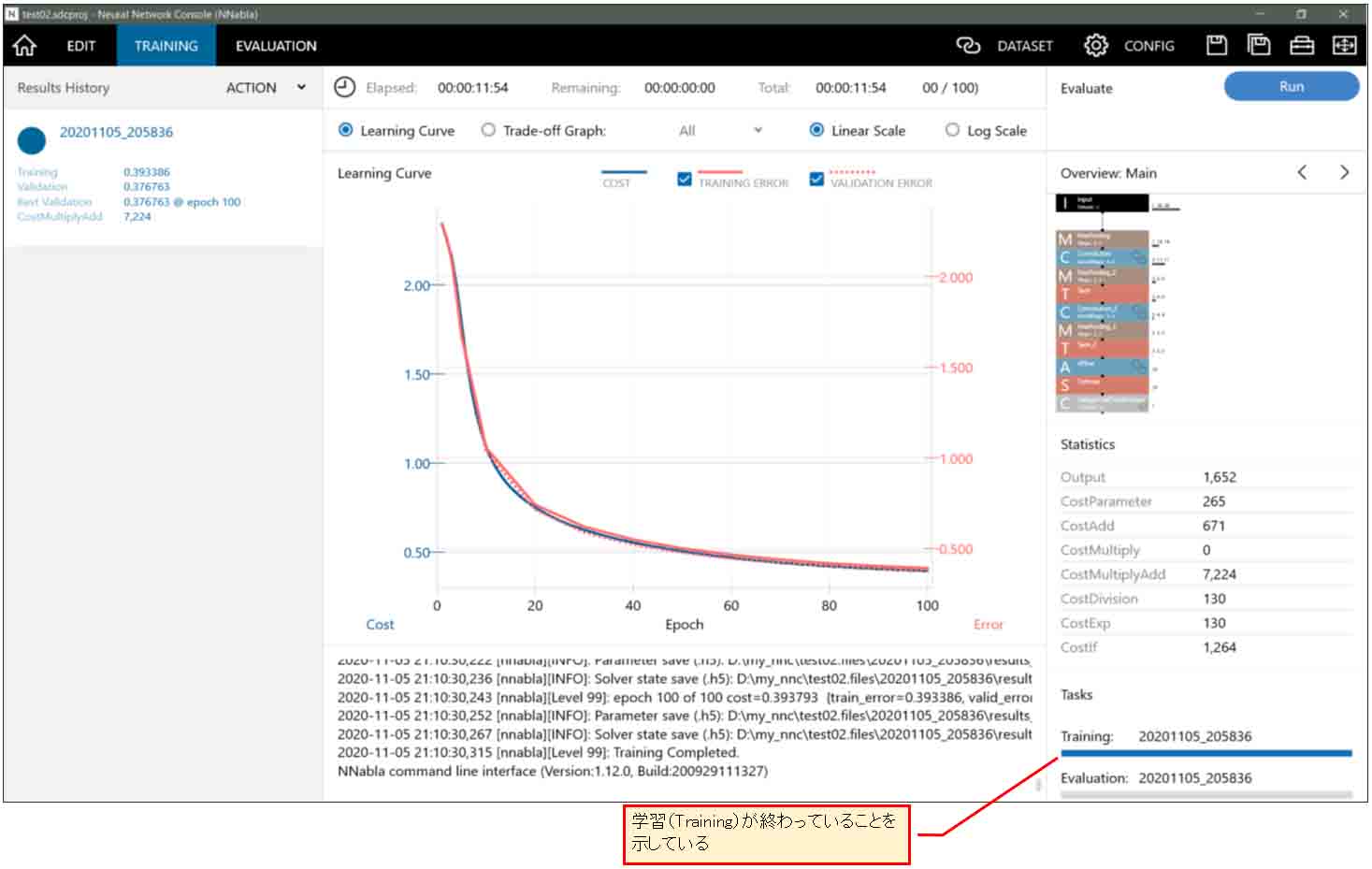
計算時間は私のパソコン環境では約11分程度で済みました。速い!
この赤い線がErrorと表示されていますが、これは失敗ではなく、誤差という意味の値です。初めて見ると紛らわしいですね。
下の欄のログでもErrorと出るので、一瞬失敗したのかと思ってしまいます。
プログラミングをやったことがある人にとって、これは勘違いし易いので、この用語は正直やめて欲しいですね。
因みに、この学習曲線が上図のように滑らかに下がっていれば学習が成功しているということです。
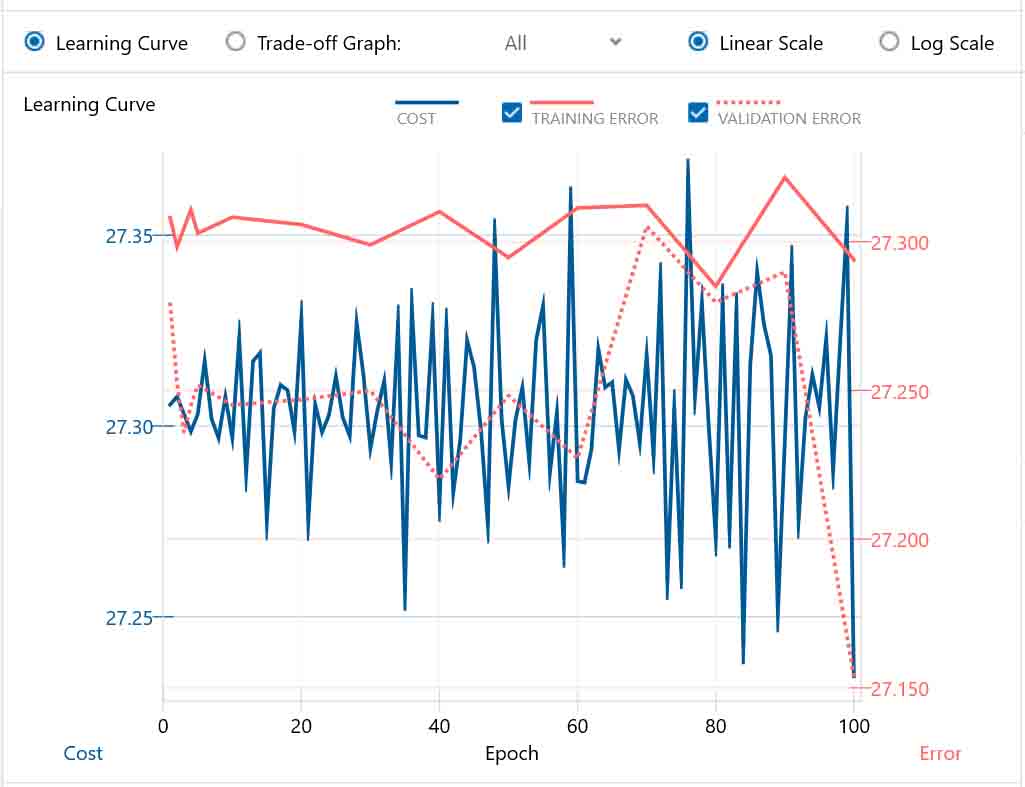
これが、下図の様に上がったり下がったりしていたら、何かが確実に誤っているということです。
(図05-03)
このグラフには、CostやEpoch(エポック)など、見慣れない用語があります。
これについて理解するには、まず、下図の様に右上の「CONFIG」をクリックします。
(図05-04)
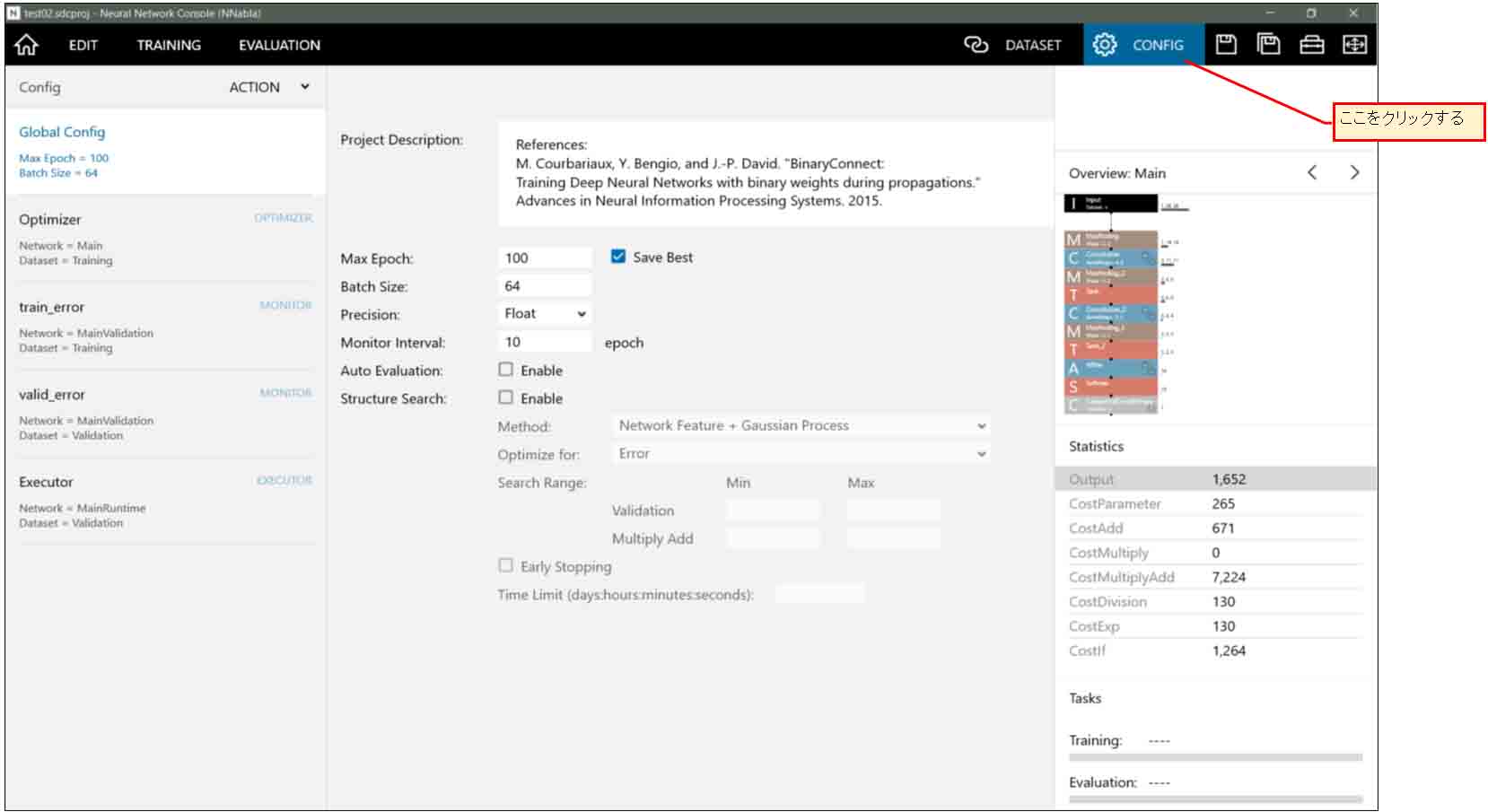
そこに「Batch Size」が64とありますが、これはMNISTデータセット60000個の中からランダムに64個ずつ抽出して学習を行い、それを60000個分学習し終えたところで、1Epochという単位になるみたいです。(ここはちょっと自信無いので間違えていたら教えてください。)
「Max Epoch」はそれを100回繰り返すということです。
Monitor Interval が10ということなので、グラフでは10Epoch毎にプロットされているということです。
グラフのCostは誤差(ロス)関数の出力値です。
前回記事で言えば平方誤差の総合計値に相当するものと思えば分かり易いかと思います。
赤い実線は、学習後に重みとバイアス値が書き換えられ、その状態でネットワークに学習データを入れ込んだ場合の誤差(ロス)関数出力値だと思われます。(たぶん、、、。)
赤い破線は、同じように学習後に評価用データを入れ込んだ場合の誤差(ロス)関数出力値だと思われます。(たぶん、、、。)
この辺は私もいまいちよく分かっていないところもあるので、PDFマニュアルを参照してください。
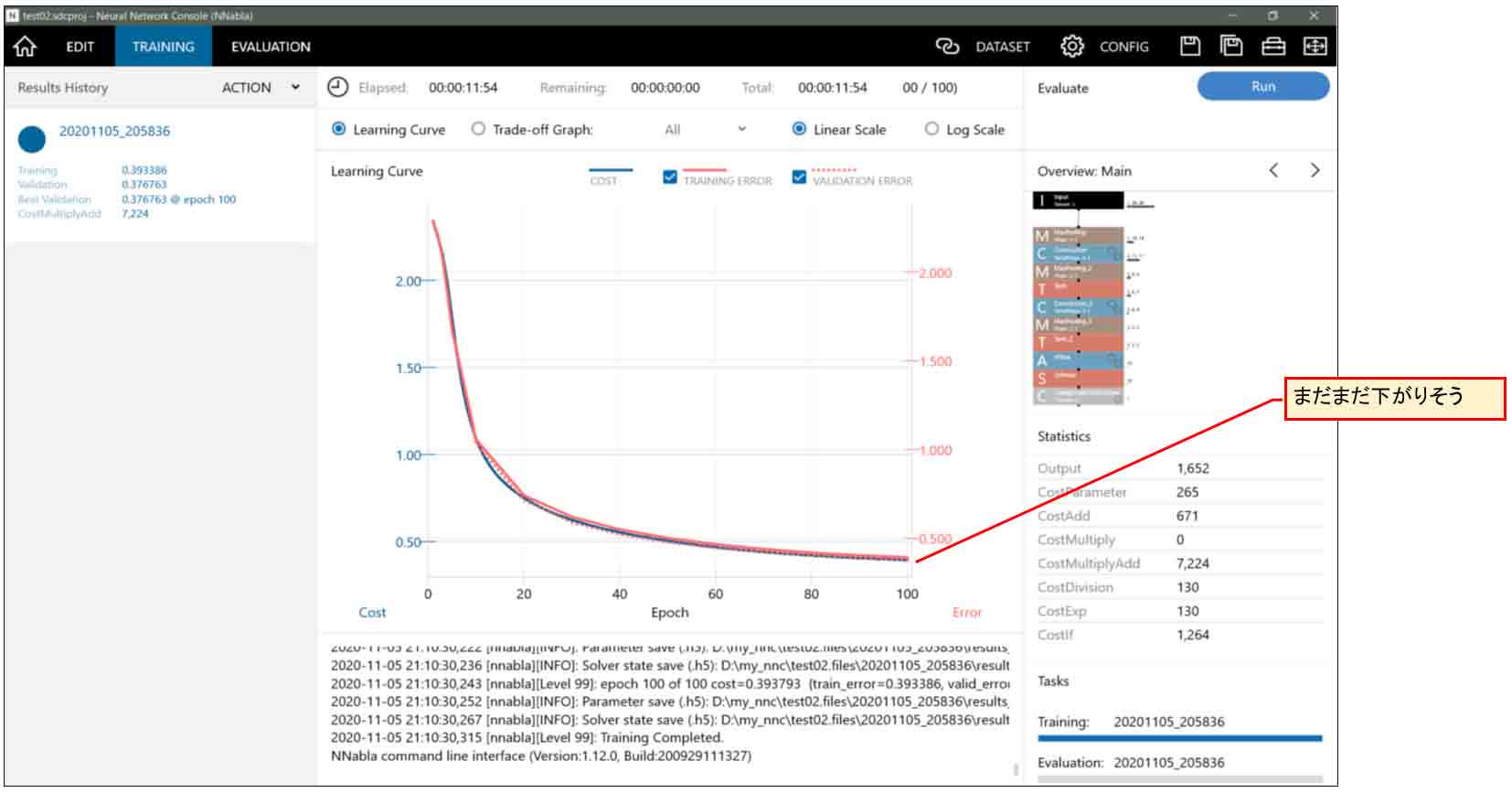
さて、(図05-02)のグラフを良く見てみると、100epochになってもまだCostの値が下がりそうに見えますね。
実は、Max Epochの値を増やせばまだまだ下がります。それについては7章で説明します。
6.評価する(Evaluation)
前節の学習が終わると、このニューラルネットワークの重みとバイアスの値が内部で最適化されているはずです。
そうしたら、次に、テスト用の手書き数字MNISTデータセット10000件を使ってこの学習済みニューラルネットワークを評価してみます。
この操作も簡単です。
学習(Training)が終わった段階で、下図の様に右上の「RUN」ボタンの左側が自動的に「Evaluate」に切り替わっているはずです。つまり、そのまま「RUN」ボタンを押せば、MNISTのテスト用データをこのニューラルネットワークに入れ込んで評価してくれます。
(図06-01)
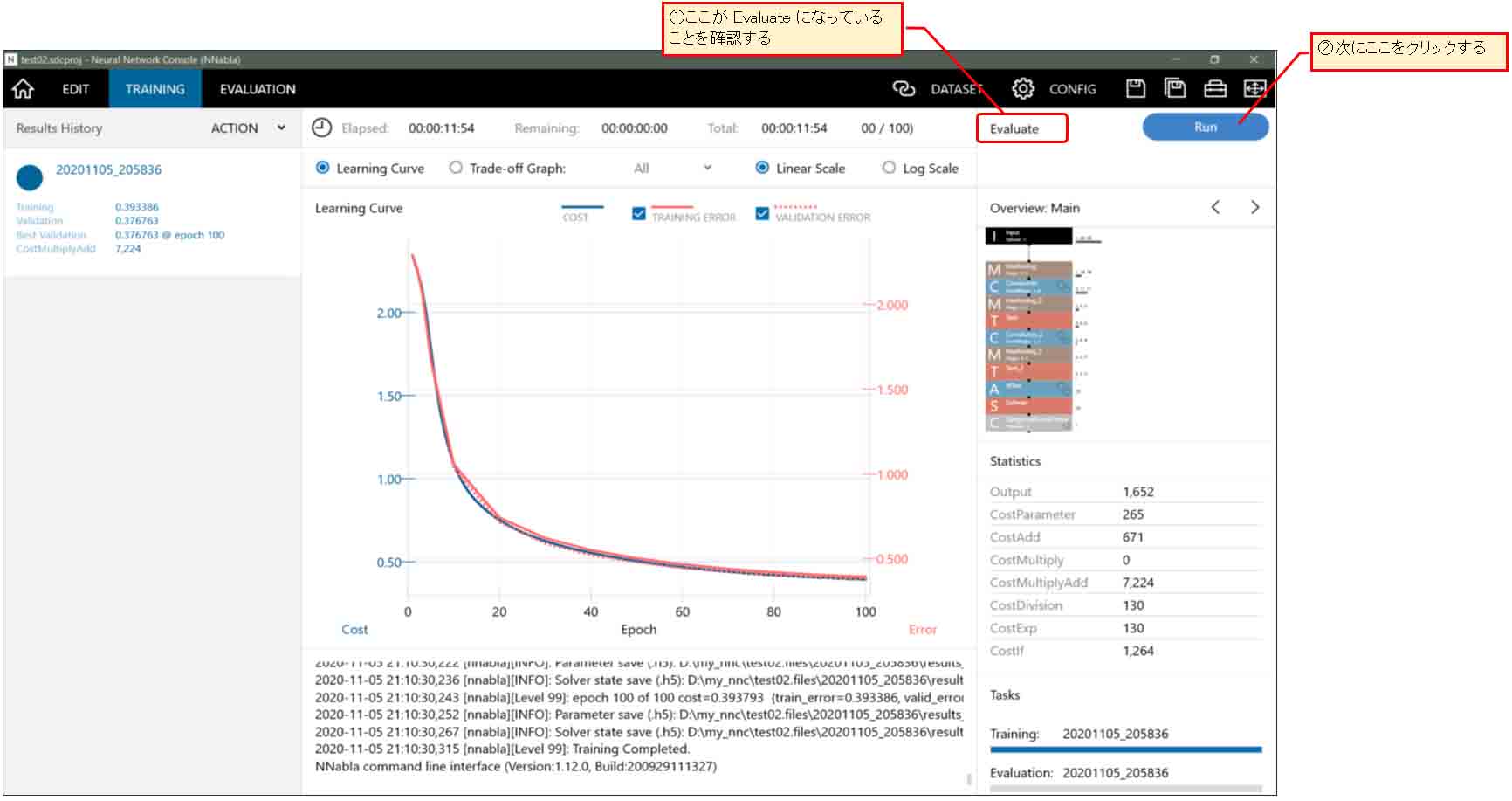
評価は結構高速で終了しました。30秒ほどで済みました。
単に決定したデータを計算するだけなので速いわけです。
すると、下図の様な画面になりますので、「Confusion Matrix」を選択します。
(図06-02)
すると、下図の様な画面になります。
(図06-03)
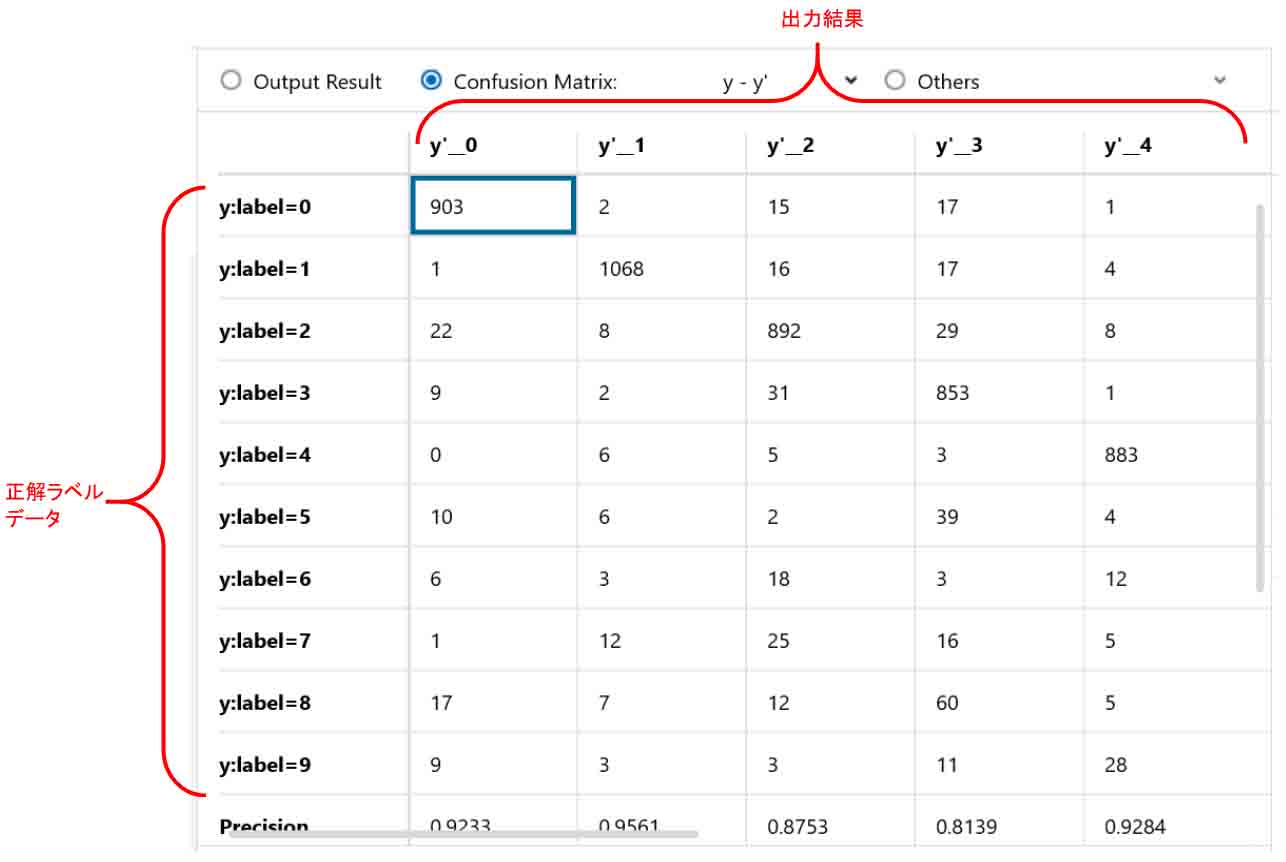
これを見ると、正解ラベルが0の所の出力結果は10000件中903件だったことがわかります。
ただ、正解ラベルが2の所に22件のデータが0と判定されてしまっていることがわかると思います。
そして、この表を下にスクロールさせると、下図のようになります。
(図06-04)
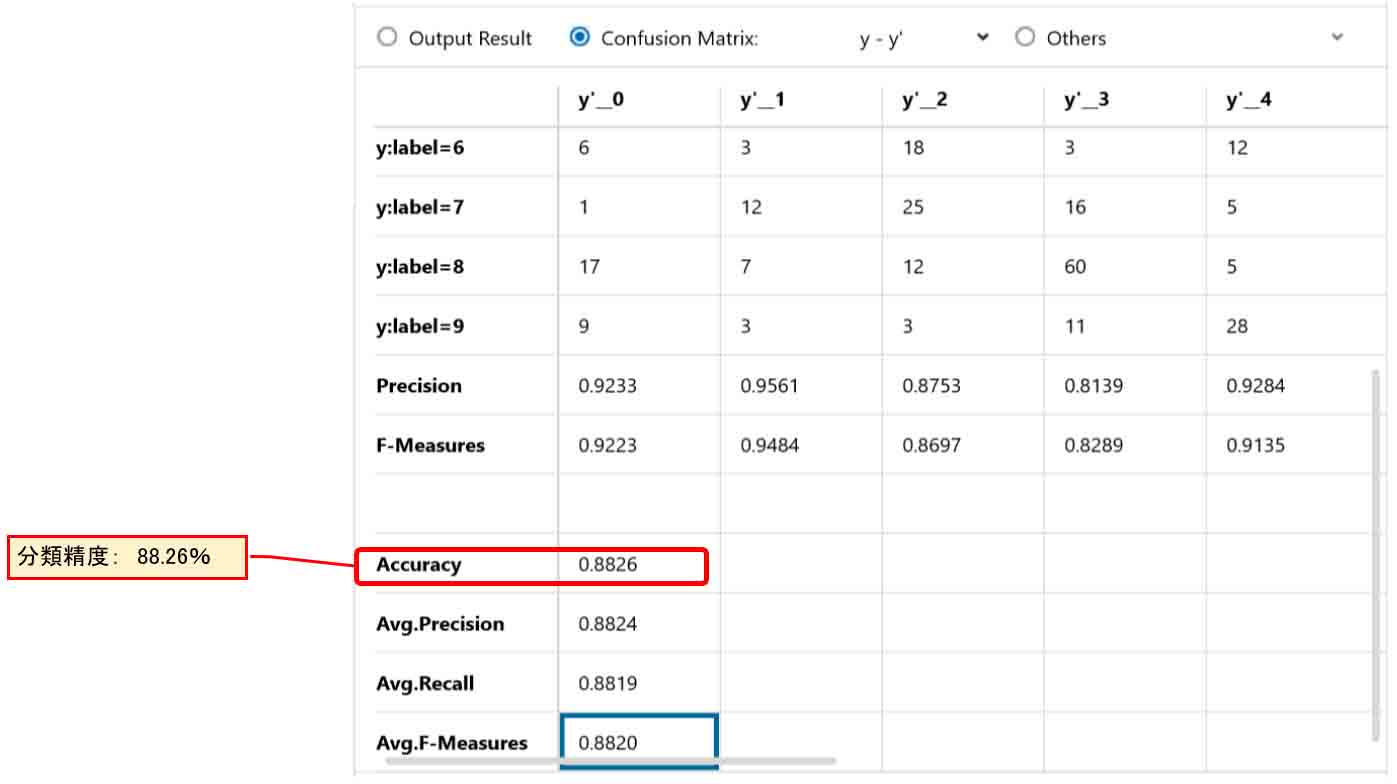
ここでは、「Accuracy」という項目だけ見れば良いと思います。
これは分類精度という指標で、正答率が88.26%ということを示しています。
おやおや?
Excelで学習させた前回記事8章の結果が約92%だったので、これでは低すぎますね。
では、次ではこれを検証してみます。
7.Max Epoch を変えてみる
まず、気になったのが、(図05-02)の曲線を見ると、まだまだCostの値が下がりそうだと読み取れます。つまり、Epochの最大値を上げればもうちょっと下がりそうですね。
(図07-01)
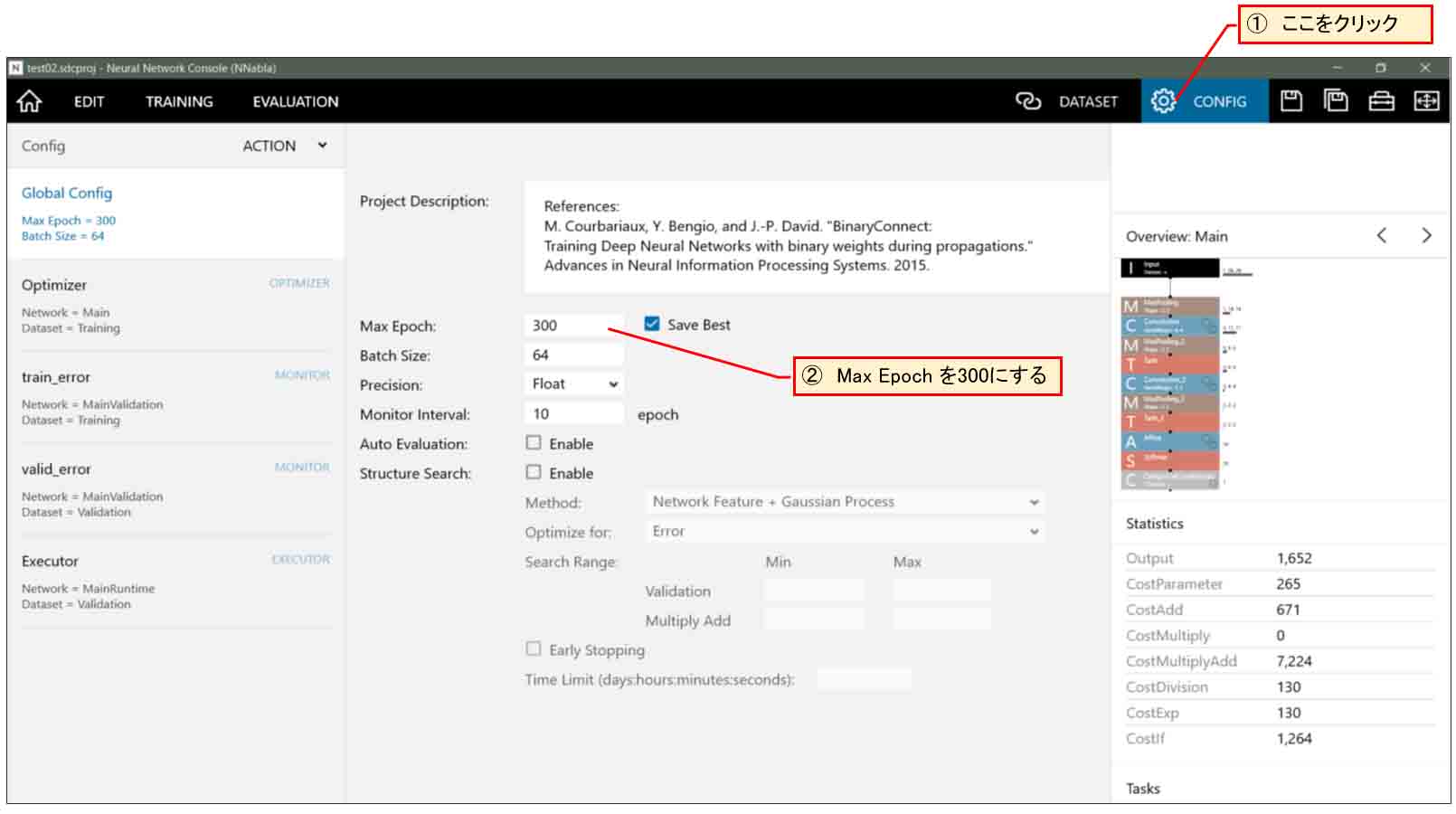
では、下図の様に右上の歯車アイコン「CONFIG」をクリックして、Max Epoch を300にしてみます。
(図07-02)
それで、5章と同様にEDIT画面で「RUN」ボタンを押して、学習スタートさせてみます。
すると、下図のようになりました。
私のパソコン環境で約25分かかりました。
(図07-03)
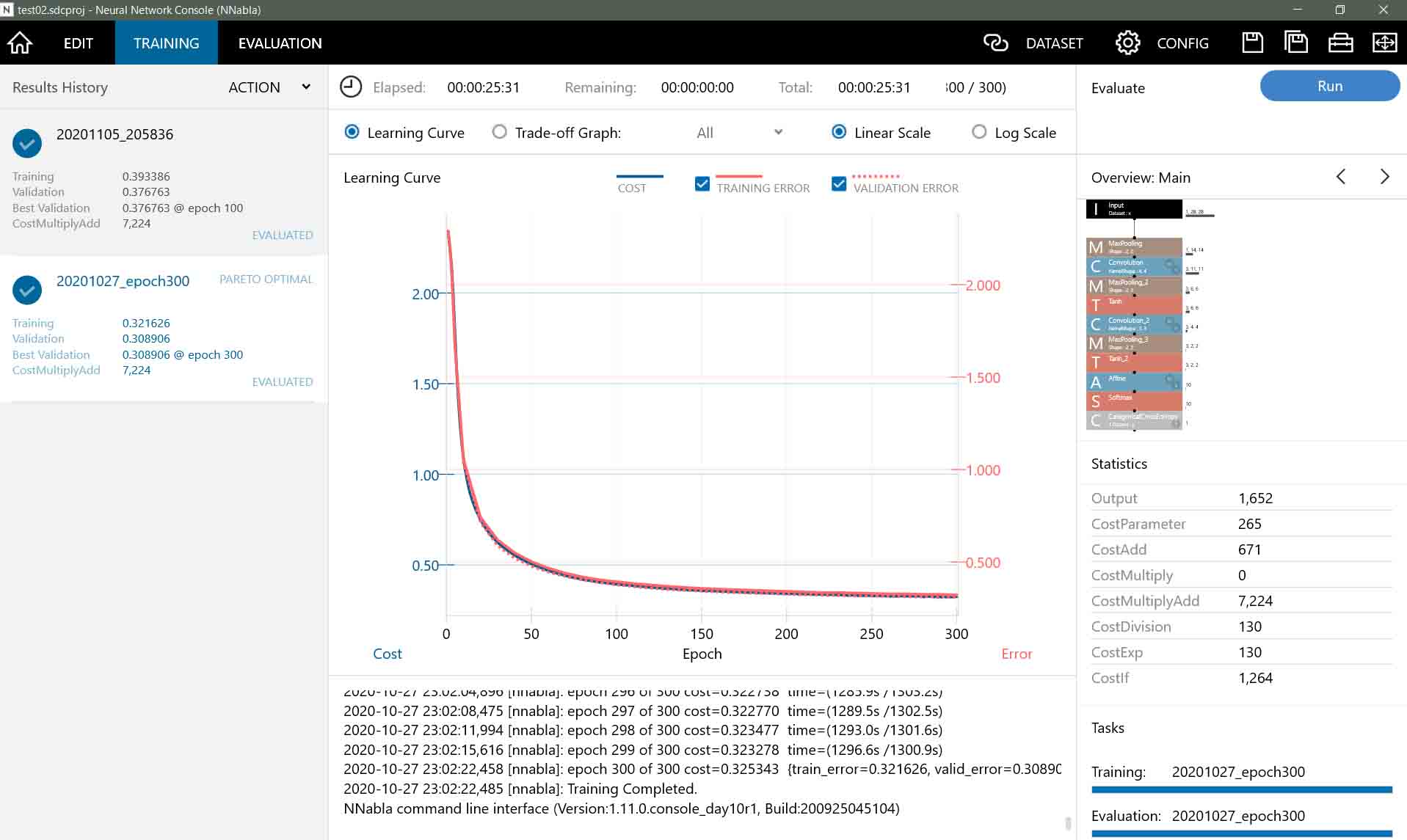
(図07-01)の場合はCost値が約0.39で終っていますが、Max Epochを300にすると、Cost値が約0.32にまで下がりました。
この学習曲線を見ても、300epoch付近はまだ傾きが水平になっていないので、まだまだ値が下がりそうです。
では、Max Epochを1000にしてみると、下図のようになりました。
(図07-04)
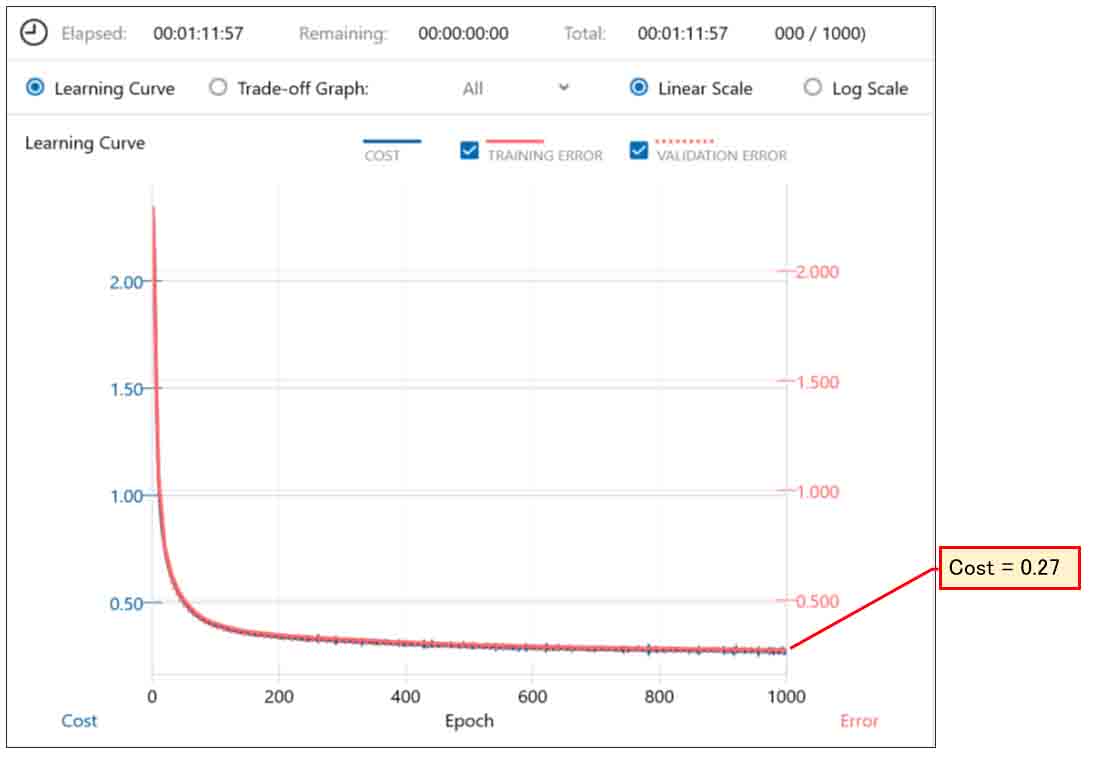
最終的にCost値は0.27まで下がりました。
もう少し下がるような気がしましたが、計算時間が1時間11分もかかったので、これくらいにします。
続いて、EVALUATION(評価)でRUNしてみて、「Confusion Matrix」を見てみると、下図のようになりました。
(図07-05)
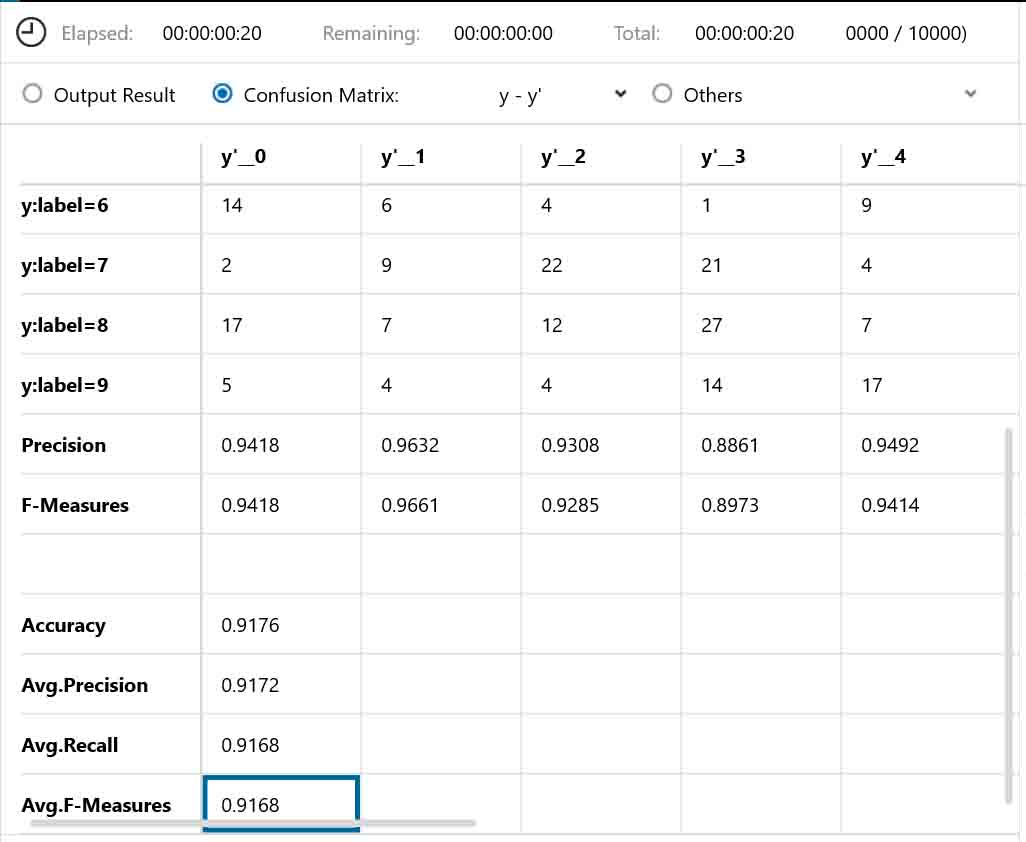
Accuracy = 0.9176 となっています。
やった!
前回記事の8-3節の正答率92.5%にかなり近づきました。
前回記事が1~9までの9種類の手書きデータセットしか判定していなかったので、今回の10種類としてはほぼ同等の成果が上げられたのではないでしょうか。
さて、これでほんとにCostが最小値になって最適解を得られたのでしょうか?
次に、このグラフを拡大してみます。
下図の様に、グラフ上をマウスで右クリックするか、マウスホイールを動かすとグラフの縦軸が拡大できます。
(図07-06)
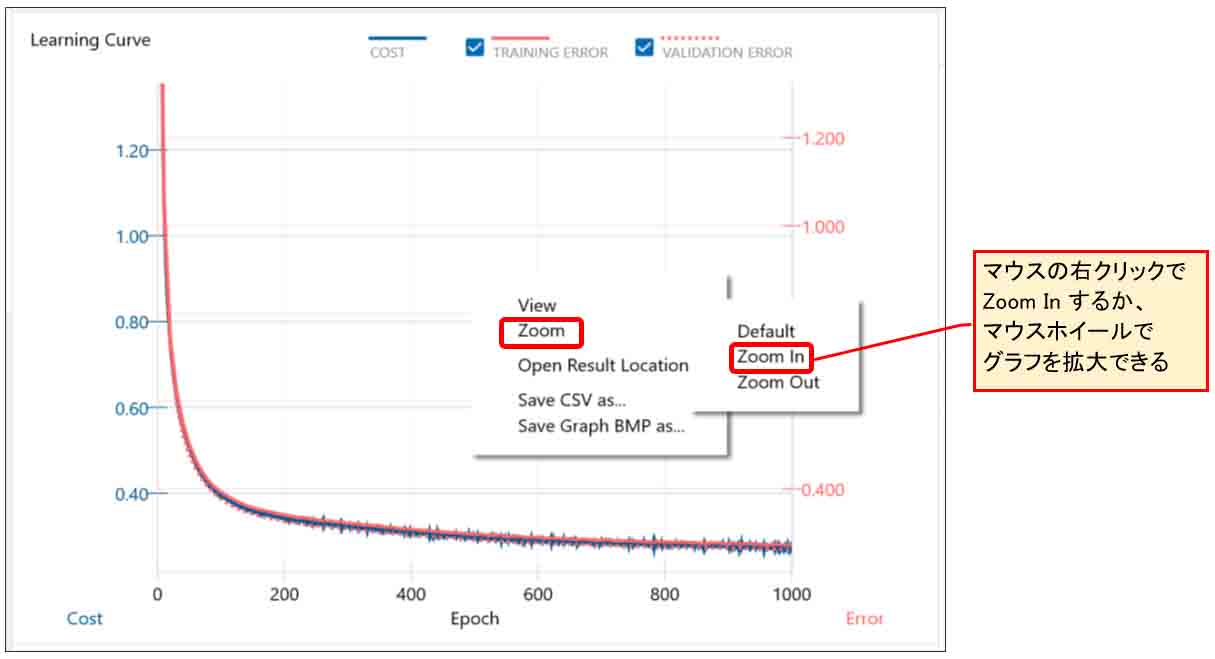
すると、下図のようになりました。
(図07-07)
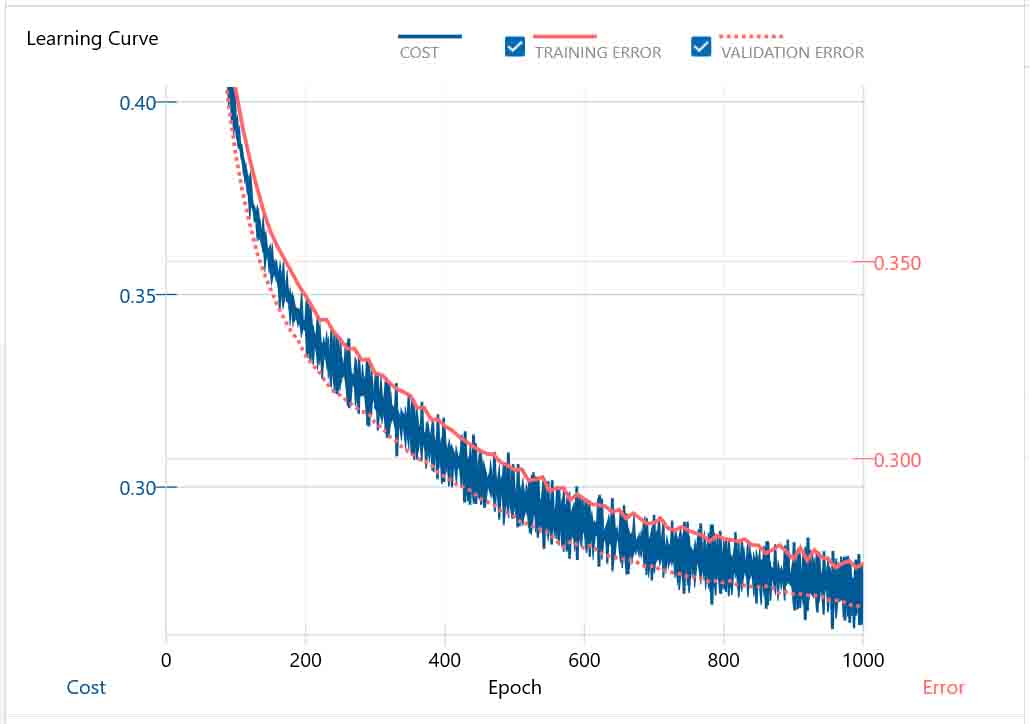
オーっと!
まだまだ最小値にたどり着いてなかったんですね。
Zoom Outした状態で見れば、もう限界かなと思ってしまいましたが、それは間違いでした。
ただ、これ以上Max Epochを増やしてテストすると、貴重な時間を奪われるのでこの辺で止めときます。
ちょっと疑問なのは、前回記事が903件のデータセットだけの学習だったのに対して、今回は60000件の学習なので、その場合はもっと正答率が上がっても良いのではないかと思いました。
実は、いろいろ調べると、前回記事のExcel計算と、このNeural Network Consoleのニューラルネットワークではかなり異なる箇所があったことが分かりました。
例えば、前回記事の2つ目のConvolutionが実はDepthwise Convolutionだったり、バイアスを加算していなかったりなどです。
また、画像の前処理をしない方が正答率は断然高くなりますし、ニューロン(ノード)数を増やすと更に正答率が上がりました。
これについて説明すると、とても長くなるので、次回にアップする記事で述べたいと思います。
8.まとめ
以上のように、SONYのNeural Network Console を使えば、膨大なデータのディープラーニングが短時間で出来るようになり、圧倒的に快適になりました。
しかも、60000件の学習データと10000件の評価用データを一気に計算できてしまう優れものでした。
前回記事のExcelでは1000件以下のデータしか学習できませんでしたから、ホントに素晴らしいです。
ニューラルネットワークも直感的にサクサク作って試すことができ、しかも各パラメータが一目瞭然で文句のつけようが無いですね。
とても良くできたディープラーニングツールだと思いました。
ただ、各層の計算方法がマニュアルを見ただけでは良くわからない事が多く、ブラックボックス化してしまっているような感じがしました。
これを使ってESP32やM5Stackおよびラズパイなどの組み込みマイコンに流用するには、各層の計算方法を理解しないとダメですね。
ということで、次回の記事ではNeural Network Consoleで学習させたものから重み(W)とバイアス(b)をエクスポートして、Excelに落とし込んで比較してみたり、ノード数を変えたり、画像前処理をカットしたりする実験を紹介したいと思います。
実は、既にその記事が出来上がっていて、今回の記事と一体化したら、文字数が多くなり過ぎたので分割した次第です。
ですから、この後数日でアップできると思います。
今回はここまでです。
ではまた。。。
Amazon.co.jp 当ブログのおすすめ












コメント
ESP32 で画像認識するの楽しみにしてます!
ponmikanさん
うれしいコメントありがとうございまーす!!!
このあともう一つアップした記事の後にESP32プログラミングに移ろうと思います。
がんばります!